 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpSeek: Self-Triggered Experience Seeking for Web Agents
Jan 13, 2026Experience intervention in web agents emerges as a promising technical paradigm, enhancing agent interaction capabilities by providing valuable insights from accumulated experiences. However, existing methods predominantly inject experience passively as global context before task execution, struggling to adapt to dynamically changing contextual observations during agent-environment interaction. We propose ExpSeek, which shifts experience toward step-level proactive seeking: (1) estimating step-level entropy thresholds to determine intervention timing using the model's intrinsic signals; (2) designing step-level tailor-designed experience content. Experiments on Qwen3-8B and 32B models across four challenging web agent benchmarks demonstrate that ExpSeek achieves absolute improvements of 9.3% and 7.5%, respectively. Our experiments validate the feasibility and advantages of entropy as a self-triggering signal, reveal that even a 4B small-scale experience model can significantly boost the performance of larger agent models.
Kling-Avatar: Grounding Multimodal Instructions for Cascaded Long-Duration Avatar Animation Synthesis
Sep 11, 2025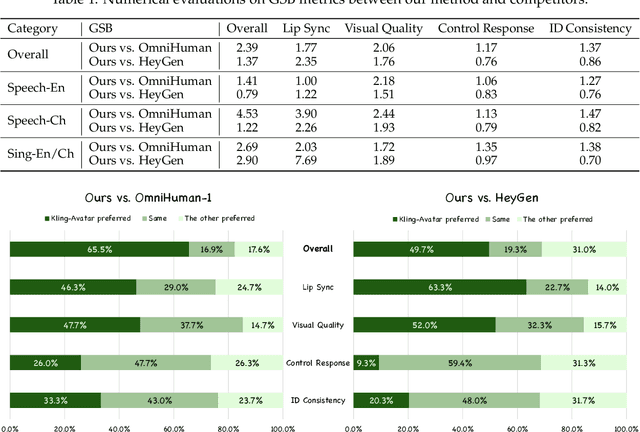
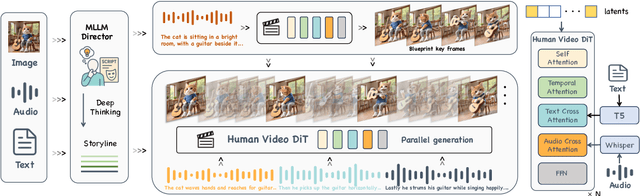


Recent advances in audio-driven avatar video generation have significantly enhanced audio-visual realism. However, existing methods treat instruction conditioning merely as low-level tracking driven by acoustic or visual cues, without modeling the communicative purpose conveyed by the instructions. This limitation compromises their narrative coherence and character expressiveness. To bridge this gap, we introduce Kling-Avatar, a novel cascaded framework that unifies multimodal instruction understanding with photorealistic portrait generation. Our approach adopts a two-stage pipeline. In the first stage, we design a multimodal large language model (MLLM) director that produces a blueprint video conditioned on diverse instruction signals, thereby governing high-level semantics such as character motion and emotions. In the second stage, guided by blueprint keyframes, we generate multiple sub-clips in parallel using a first-last frame strategy. This global-to-local framework preserves fine-grained details while faithfully encoding the high-level intent behind multimodal instructions. Our parallel architecture also enables fast and stable generation of long-duration videos, making it suitable for real-world applications such as digital human livestreaming and vlogging. To comprehensively evaluate our method, we construct a benchmark of 375 curated samples covering diverse instructions and challenging scenarios. Extensive experiments demonstrate that Kling-Avatar is capable of generating vivid, fluent, long-duration videos at up to 1080p and 48 fps, achieving superior performance in lip synchronization accuracy, emotion and dynamic expressiveness, instruction controllability, identity preservation, and cross-domain generalization. These results establish Kling-Avatar as a new benchmark for semantically grounded, high-fidelity audio-driven avatar synthesis.
MIDAS: Multimodal Interactive Digital-humAn Synthesis via Real-time Autoregressive Video Generation
Aug 28, 2025Recently, interactive digital human video generation has attracted widespread attention and achieved remarkable progress. However, building such a practical system that can interact with diverse input signals in real time remains challenging to existing methods, which often struggle with heavy computational cost and limited controllability. In this work, we introduce an autoregressive video generation framework that enables interactive multimodal control and low-latency extrapolation in a streaming manner. With minimal modifications to a standard large language model (LLM), our framework accepts multimodal condition encodings including audio, pose, and text, and outputs spatially and semantically coherent representations to guide the denoising process of a diffusion head. To support this, we construct a large-scale dialogue dataset of approximately 20,000 hours from multiple sources, providing rich conversational scenarios for training. We further introduce a deep compression autoencoder with up to 64$\times$ reduction ratio, which effectively alleviates the long-horizon inference burden of the autoregressive model. Extensive experiments on duplex conversation, multilingual human synthesis, and interactive world model highlight the advantages of our approach in low latency, high efficiency, and fine-grained multimodal controllability.
GAP: Gaussianize Any Point Clouds with Text Guidance
Aug 07, 20253D Gaussian Splatting (3DGS) has demonstrated its advantages in achieving fast and high-quality rendering. As point clouds serve as a widely-used and easily accessible form of 3D representation, bridging the gap between point clouds and Gaussians becomes increasingly important. Recent studies have explored how to convert the colored points into Gaussians, but directly generating Gaussians from colorless 3D point clouds remains an unsolved challenge. In this paper, we propose GAP, a novel approach that gaussianizes raw point clouds into high-fidelity 3D Gaussians with text guidance. Our key idea is to design a multi-view optimization framework that leverages a depth-aware image diffusion model to synthesize consistent appearances across different viewpoints. To ensure geometric accuracy, we introduce a surface-anchoring mechanism that effectively constrains Gaussians to lie on the surfaces of 3D shapes during optimization. Furthermore, GAP incorporates a diffuse-based inpainting strategy that specifically targets at completing hard-to-observe regions. We evaluate GAP on the Point-to-Gaussian generation task across varying complexity levels, from synthetic point clouds to challenging real-world scans, and even large-scale scenes. Project Page: https://weiqi-zhang.github.io/GAP.
S1-Bench: A Simple Benchmark for Evaluating System 1 Thinking Capability of Large Reasoning Models
Apr 14, 2025



We introduce S1-Bench, a novel benchmark designed to evaluate Large Reasoning Models' (LRMs) performance on simple tasks that favor intuitive system 1 thinking rather than deliberative system 2 reasoning. While LRMs have achieved significant breakthroughs in complex reasoning tasks through explicit chains of thought, their reliance on deep analytical thinking may limit their system 1 thinking capabilities. Moreover, a lack of benchmark currently exists to evaluate LRMs' performance in tasks that require such capabilities. To fill this gap, S1-Bench presents a set of simple, diverse, and naturally clear questions across multiple domains and languages, specifically designed to assess LRMs' performance in such tasks. Our comprehensive evaluation of 22 LRMs reveals significant lower efficiency tendencies, with outputs averaging 15.5 times longer than those of traditional small LLMs. Additionally, LRMs often identify correct answers early but continue unnecessary deliberation, with some models even producing numerous errors. These findings highlight the rigid reasoning patterns of current LRMs and underscore the substantial development needed to achieve balanced dual-system thinking capabilities that can adapt appropriately to task complexity.
SOTOPIA-Ω: Dynamic Strategy Injection Learning and Social Instrucion Following Evaluation for Social Agents
Feb 21, 2025Despite the abundance of prior social strategies possessed by humans, there remains a paucity of research dedicated to their transfer and integration into social agents. Our proposed SOTOPIA-{\Omega} framework aims to address and bridge this gap, with a particular focus on enhancing the social capabilities of language agents. This framework dynamically injects multi-step reasoning strategies inspired by negotiation theory, along with two simple direct strategies, into expert agents, thereby automating the construction of high-quality social dialogue training corpus. Additionally, we introduce the concept of Social Instruction Following (S-IF) and propose two new S-IF evaluation metrics that are complementary to social capability. We demonstrate that several 7B models trained on high-quality corpus not only significantly surpass the expert agent (GPT-4) in achieving social goals but also enhance S-IF performance. Analysis and variant experiments validate the advantages of dynamic construction, which can especially break the agent's prolonged deadlock.
Sparis: Neural Implicit Surface Reconstruction of Indoor Scenes from Sparse Views
Jan 02, 2025



In recent years, reconstructing indoor scene geometry from multi-view images has achieved encouraging accomplishments. Current methods incorporate monocular priors into neural implicit surface models to achieve high-quality reconstructions. However, these methods require hundreds of images for scene reconstruction. When only a limited number of views are available as input, the performance of monocular priors deteriorates due to scale ambiguity, leading to the collapse of the reconstructed scene geometry. In this paper, we propose a new method, named Sparis, for indoor surface reconstruction from sparse views. Specifically, we investigate the impact of monocular priors on sparse scene reconstruction, introducing a novel prior based on inter-image matching information. Our prior offers more accurate depth information while ensuring cross-view matching consistency. Additionally, we employ an angular filter strategy and an epipolar matching weight function, aiming to reduce errors due to view matching inaccuracies, thereby refining the inter-image prior for improved reconstruction accuracy. The experiments conducted on widely used benchmarks demonstrate superior performance in sparse-view scene reconstruction.
Neural Signed Distance Function Inference through Splatting 3D Gaussians Pulled on Zero-Level Set
Oct 18, 2024It is vital to infer a signed distance function (SDF) in multi-view based surface reconstruction. 3D Gaussian splatting (3DGS) provides a novel perspective for volume rendering, and shows advantages in rendering efficiency and quality. Although 3DGS provides a promising neural rendering option, it is still hard to infer SDFs for surface reconstruction with 3DGS due to the discreteness, the sparseness, and the off-surface drift of 3D Gaussians. To resolve these issues, we propose a method that seamlessly merge 3DGS with the learning of neural SDFs. Our key idea is to more effectively constrain the SDF inference with the multi-view consistency. To this end, we dynamically align 3D Gaussians on the zero-level set of the neural SDF using neural pulling, and then render the aligned 3D Gaussians through the differentiable rasterization. Meanwhile, we update the neural SDF by pulling neighboring space to the pulled 3D Gaussians, which progressively refine the signed distance field near the surface. With both differentiable pulling and splatting, we jointly optimize 3D Gaussians and the neural SDF with both RGB and geometry constraints, which recovers more accurate, smooth, and complete surfaces with more geometry details. Our numerical and visual comparisons show our superiority over the state-of-the-art results on the widely used benchmarks.
MoR: Mixture of Ranks for Low-Rank Adaptation Tuning
Oct 17, 2024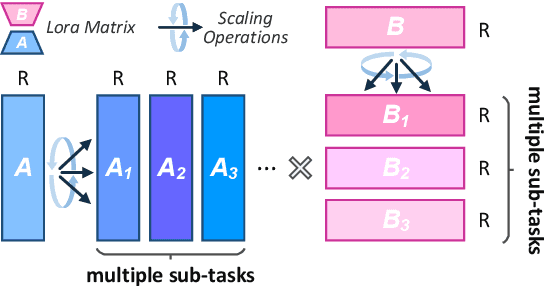
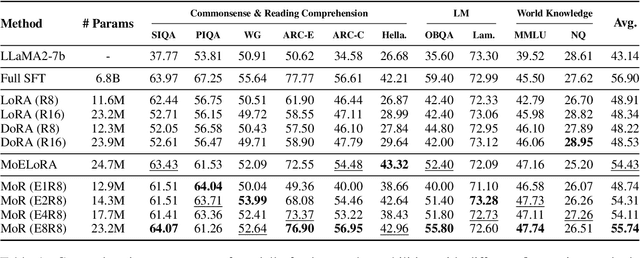
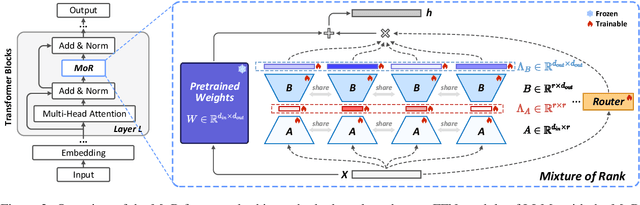

Low-Rank Adaptation (LoRA) drives research to align its performance with full fine-tuning. However, significant challenges remain: (1) Simply increasing the rank size of LoRA does not effectively capture high-rank information, which leads to a performance bottleneck.(2) MoE-style LoRA methods substantially increase parameters and inference latency, contradicting the goals of efficient fine-tuning and ease of application. To address these challenges, we introduce Mixture of Ranks (MoR), which learns rank-specific information for different tasks based on input and efficiently integrates multi-rank information. We firstly propose a new framework that equates the integration of multiple LoRAs to expanding the rank of LoRA. Moreover, we hypothesize that low-rank LoRA already captures sufficient intrinsic information, and MoR can derive high-rank information through mathematical transformations of the low-rank components. Thus, MoR can reduces the learning difficulty of LoRA and enhances its multi-task capabilities. MoR achieves impressive results, with MoR delivering a 1.31\% performance improvement while using only 93.93\% of the parameters compared to baseline methods.
Revealing the Challenge of Detecting Character Knowledge Errors in LLM Role-Playing
Sep 18, 2024



Large language model (LLM) role-playing has gained widespread attention, where the authentic character knowledge is crucial for constructing realistic LLM role-playing agents. However, existing works usually overlook the exploration of LLMs' ability to detect characters' known knowledge errors (KKE) and unknown knowledge errors (UKE) while playing roles, which would lead to low-quality automatic construction of character trainable corpus. In this paper, we propose a probing dataset to evaluate LLMs' ability to detect errors in KKE and UKE. The results indicate that even the latest LLMs struggle to effectively detect these two types of errors, especially when it comes to familiar knowledge. We experimented with various reasoning strategies and propose an agent-based reasoning method, Self-Recollection and Self-Doubt (S2RD), to further explore the potential for improving error detection capabilities. Experiments show that our method effectively improves the LLMs' ability to detect error character knowledge, but it remains an issue that requires ongoing attention.