 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLess is Enough: Training-Free Video Diffusion Acceleration via Runtime-Adaptive Caching
Jul 03, 2025Video generation models have demonstrated remarkable performance, yet their broader adoption remains constrained by slow inference speeds and substantial computational costs, primarily due to the iterative nature of the denoising process. Addressing this bottleneck is essential for democratizing advanced video synthesis technologies and enabling their integration into real-world applications. This work proposes EasyCache, a training-free acceleration framework for video diffusion models. EasyCache introduces a lightweight, runtime-adaptive caching mechanism that dynamically reuses previously computed transformation vectors, avoiding redundant computations during inference. Unlike prior approaches, EasyCache requires no offline profiling, pre-computation, or extensive parameter tuning. We conduct comprehensive studies on various large-scale video generation models, including OpenSora, Wan2.1, and HunyuanVideo. Our method achieves leading acceleration performance, reducing inference time by up to 2.1-3.3$\times$ compared to the original baselines while maintaining high visual fidelity with a significant up to 36% PSNR improvement compared to the previous SOTA method. This improvement makes our EasyCache a efficient and highly accessible solution for high-quality video generation in both research and practical applications. The code is available at https://github.com/H-EmbodVis/EasyCache.
DiST-4D: Disentangled Spatiotemporal Diffusion with Metric Depth for 4D Driving Scene Generation
Mar 19, 2025



Current generative models struggle to synthesize dynamic 4D driving scenes that simultaneously support temporal extrapolation and spatial novel view synthesis (NVS) without per-scene optimization. A key challenge lies in finding an efficient and generalizable geometric representation that seamlessly connects temporal and spatial synthesis. To address this, we propose DiST-4D, the first disentangled spatiotemporal diffusion framework for 4D driving scene generation, which leverages metric depth as the core geometric representation. DiST-4D decomposes the problem into two diffusion processes: DiST-T, which predicts future metric depth and multi-view RGB sequences directly from past observations, and DiST-S, which enables spatial NVS by training only on existing viewpoints while enforcing cycle consistency. This cycle consistency mechanism introduces a forward-backward rendering constraint, reducing the generalization gap between observed and unseen viewpoints. Metric depth is essential for both accurate reliable forecasting and accurate spatial NVS, as it provides a view-consistent geometric representation that generalizes well to unseen perspectives. Experiments demonstrate that DiST-4D achieves state-of-the-art performance in both temporal prediction and NVS tasks, while also delivering competitive performance in planning-related evaluations.
HERMES: A Unified Self-Driving World Model for Simultaneous 3D Scene Understanding and Generation
Jan 24, 2025



Driving World Models (DWMs) have become essential for autonomous driving by enabling future scene prediction. However, existing DWMs are limited to scene generation and fail to incorporate scene understanding, which involves interpreting and reasoning about the driving environment. In this paper, we present a unified Driving World Model named HERMES. We seamlessly integrate 3D scene understanding and future scene evolution (generation) through a unified framework in driving scenarios. Specifically, HERMES leverages a Bird's-Eye View (BEV) representation to consolidate multi-view spatial information while preserving geometric relationships and interactions. We also introduce world queries, which incorporate world knowledge into BEV features via causal attention in the Large Language Model (LLM), enabling contextual enrichment for understanding and generation tasks. We conduct comprehensive studies on nuScenes and OmniDrive-nuScenes datasets to validate the effectiveness of our method. HERMES achieves state-of-the-art performance, reducing generation error by 32.4% and improving understanding metrics such as CIDEr by 8.0%. The model and code will be publicly released at https://github.com/LMD0311/HERMES.
UniScene: Unified Occupancy-centric Driving Scene Generation
Dec 06, 2024Generating high-fidelity, controllable, and annotated training data is critical for autonomous driving. Existing methods typically generate a single data form directly from a coarse scene layout, which not only fails to output rich data forms required for diverse downstream tasks but also struggles to model the direct layout-to-data distribution. In this paper, we introduce UniScene, the first unified framework for generating three key data forms - semantic occupancy, video, and LiDAR - in driving scenes. UniScene employs a progressive generation process that decomposes the complex task of scene generation into two hierarchical steps: (a) first generating semantic occupancy from a customized scene layout as a meta scene representation rich in both semantic and geometric information, and then (b) conditioned on occupancy, generating video and LiDAR data, respectively, with two novel transfer strategies of Gaussian-based Joint Rendering and Prior-guided Sparse Modeling. This occupancy-centric approach reduces the generation burden, especially for intricate scenes, while providing detailed intermediate representations for the subsequent generation stages. Extensive experiments demonstrate that UniScene outperforms previous SOTAs in the occupancy, video, and LiDAR generation, which also indeed benefits downstream driving tasks.
SparseAD: Sparse Query-Centric Paradigm for Efficient End-to-End Autonomous Driving
Apr 10, 2024



End-to-End paradigms use a unified framework to implement multi-tasks in an autonomous driving system. Despite simplicity and clarity, the performance of end-to-end autonomous driving methods on sub-tasks is still far behind the single-task methods. Meanwhile, the widely used dense BEV features in previous end-to-end methods make it costly to extend to more modalities or tasks. In this paper, we propose a Sparse query-centric paradigm for end-to-end Autonomous Driving (SparseAD), where the sparse queries completely represent the whole driving scenario across space, time and tasks without any dense BEV representation. Concretely, we design a unified sparse architecture for perception tasks including detection, tracking, and online mapping. Moreover, we revisit motion prediction and planning, and devise a more justifiable motion planner framework. On the challenging nuScenes dataset, SparseAD achieves SOTA full-task performance among end-to-end methods and significantly narrows the performance gap between end-to-end paradigms and single-task methods. Codes will be released soon.
EPNet++: Cascade Bi-directional Fusion for Multi-Modal 3D Object Detection
Jan 12, 2022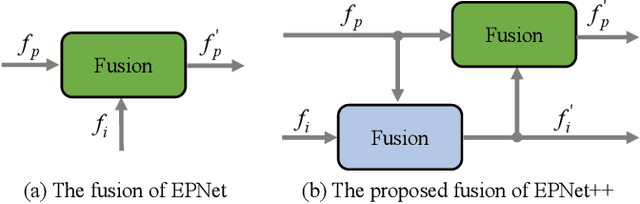



Recently, fusing the LiDAR point cloud and camera image to improve the performance and robustness of 3D object detection has received more and more attention, as these two modalities naturally possess strong complementarity. In this paper, we propose EPNet++ for multi-modal 3D object detection by introducing a novel Cascade Bi-directional Fusion~(CB-Fusion) module and a Multi-Modal Consistency~(MC) loss. More concretely, the proposed CB-Fusion module boosts the plentiful semantic information of point features with the image features in a cascade bi-directional interaction fusion manner, leading to more comprehensive and discriminative feature representations. The MC loss explicitly guarantees the consistency between predicted scores from two modalities to obtain more comprehensive and reliable confidence scores. The experiment results on the KITTI, JRDB and SUN-RGBD datasets demonstrate the superiority of EPNet++ over the state-of-the-art methods. Besides, we emphasize a critical but easily overlooked problem, which is to explore the performance and robustness of a 3D detector in a sparser scene. Extensive experiments present that EPNet++ outperforms the existing SOTA methods with remarkable margins in highly sparse point cloud cases, which might be an available direction to reduce the expensive cost of LiDAR sensors. Code will be released in the future.
PRA-Net: Point Relation-Aware Network for 3D Point Cloud Analysis
Dec 09, 2021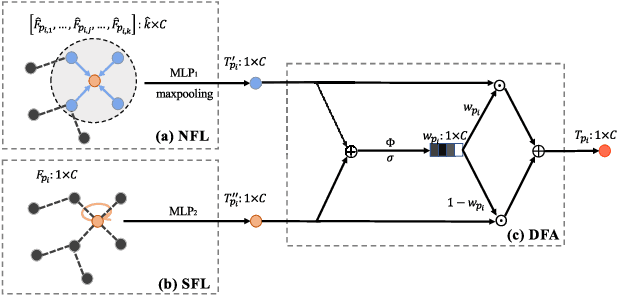
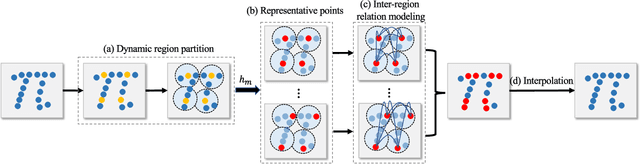

Learning intra-region contexts and inter-region relations are two effective strategies to strengthen feature representations for point cloud analysis. However, unifying the two strategies for point cloud representation is not fully emphasized in existing methods. To this end, we propose a novel framework named Point Relation-Aware Network (PRA-Net), which is composed of an Intra-region Structure Learning (ISL) module and an Inter-region Relation Learning (IRL) module. The ISL module can dynamically integrate the local structural information into the point features, while the IRL module captures inter-region relations adaptively and efficiently via a differentiable region partition scheme and a representative point-based strategy. Extensive experiments on several 3D benchmarks covering shape classification, keypoint estimation, and part segmentation have verified the effectiveness and the generalization ability of PRA-Net. Code will be available at https://github.com/XiwuChen/PRA-Net .
* 13 pages
TransCrowd: Weakly-Supervised Crowd Counting with Transformer
Apr 19, 2021
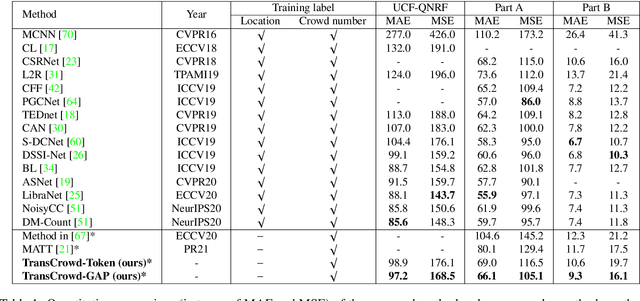


The mainstream crowd counting methods usually utilize the convolution neural network (CNN) to regress a density map, requiring point-level annotations. However, annotating each person with a point is an expensive and laborious process. During the testing phase, the point-level annotations are not considered to evaluate the counting accuracy, which means the point-level annotations are redundant. Hence, it is desirable to develop weakly-supervised counting methods that just rely on count level annotations, a more economical way of labeling. Current weakly-supervised counting methods adopt the CNN to regress a total count of the crowd by an image-to-count paradigm. However, having limited receptive fields for context modeling is an intrinsic limitation of these weakly-supervised CNN-based methods. These methods thus can not achieve satisfactory performance, limited applications in the real-word. The Transformer is a popular sequence-to-sequence prediction model in NLP, which contains a global receptive field. In this paper, we propose TransCrowd, which reformulates the weakly-supervised crowd counting problem from the perspective of sequence-to-count based on Transformer. We observe that the proposed TransCrowd can effectively extract the semantic crowd information by using the self-attention mechanism of Transformer. To the best of our knowledge, this is the first work to adopt a pure Transformer for crowd counting research. Experiments on five benchmark datasets demonstrate that the proposed TransCrowd achieves superior performance compared with all the weakly-supervised CNN-based counting methods and gains highly competitive counting performance compared with some popular fully-supervised counting methods. Code is available at https://github.com/dk-liang/TransCrowd.
EPNet: Enhancing Point Features with Image Semantics for 3D Object Detection
Jul 17, 2020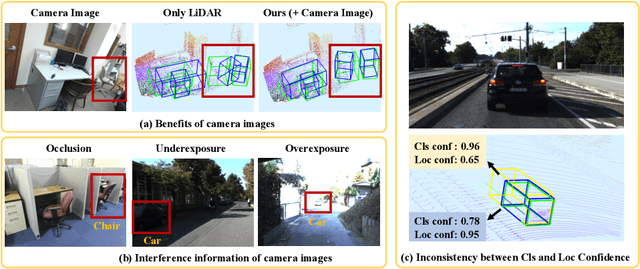
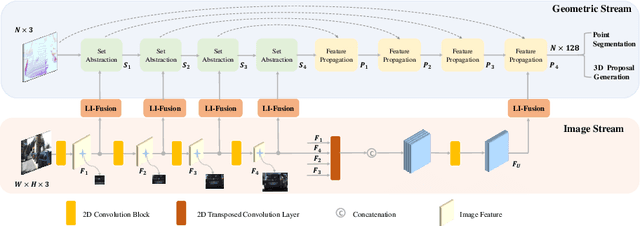


In this paper, we aim at addressing two critical issues in the 3D detection task, including the exploitation of multiple sensors~(namely LiDAR point cloud and camera image), as well as the inconsistency between the localization and classification confidence. To this end, we propose a novel fusion module to enhance the point features with semantic image features in a point-wise manner without any image annotations. Besides, a consistency enforcing loss is employed to explicitly encourage the consistency of both the localization and classification confidence. We design an end-to-end learnable framework named EPNet to integrate these two components. Extensive experiments on the KITTI and SUN-RGBD datasets demonstrate the superiority of EPNet over the state-of-the-art methods. Codes and models are available at: \url{https://github.com/happinesslz/EPNet}.