 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoregressive Meta-Actions for Unified Controllable Trajectory Generation
May 29, 2025



Controllable trajectory generation guided by high-level semantic decisions, termed meta-actions, is crucial for autonomous driving systems. A significant limitation of existing frameworks is their reliance on invariant meta-actions assigned over fixed future time intervals, causing temporal misalignment with the actual behavior trajectories. This misalignment leads to irrelevant associations between the prescribed meta-actions and the resulting trajectories, disrupting task coherence and limiting model performance. To address this challenge, we introduce Autoregressive Meta-Actions, an approach integrated into autoregressive trajectory generation frameworks that provides a unified and precise definition for meta-action-conditioned trajectory prediction. Specifically, We decompose traditional long-interval meta-actions into frame-level meta-actions, enabling a sequential interplay between autoregressive meta-action prediction and meta-action-conditioned trajectory generation. This decomposition ensures strict alignment between each trajectory segment and its corresponding meta-action, achieving a consistent and unified task formulation across the entire trajectory span and significantly reducing complexity. Moreover, we propose a staged pre-training process to decouple the learning of basic motion dynamics from the integration of high-level decision control, which offers flexibility, stability, and modularity. Experimental results validate our framework's effectiveness, demonstrating improved trajectory adaptivity and responsiveness to dynamic decision-making scenarios. We provide the video document and dataset, which are available at https://arma-traj.github.io/.
DRoPE: Directional Rotary Position Embedding for Efficient Agent Interaction Modeling
Mar 19, 2025Accurate and efficient modeling of agent interactions is essential for trajectory generation, the core of autonomous driving systems. Existing methods, scene-centric, agent-centric, and query-centric frameworks, each present distinct advantages and drawbacks, creating an impossible triangle among accuracy, computational time, and memory efficiency. To break this limitation, we propose Directional Rotary Position Embedding (DRoPE), a novel adaptation of Rotary Position Embedding (RoPE), originally developed in natural language processing. Unlike traditional relative position embedding (RPE), which introduces significant space complexity, RoPE efficiently encodes relative positions without explicitly increasing complexity but faces inherent limitations in handling angular information due to periodicity. DRoPE overcomes this limitation by introducing a uniform identity scalar into RoPE's 2D rotary transformation, aligning rotation angles with realistic agent headings to naturally encode relative angular information. We theoretically analyze DRoPE's correctness and efficiency, demonstrating its capability to simultaneously optimize trajectory generation accuracy, time complexity, and space complexity. Empirical evaluations compared with various state-of-the-art trajectory generation models, confirm DRoPE's good performance and significantly reduced space complexity, indicating both theoretical soundness and practical effectiveness. The video documentation is available at https://drope-traj.github.io/.
Force Sensing Guided Artery-Vein Segmentation via Sequential Ultrasound Images
Jul 31, 2024Accurate identification of arteries and veins in ultrasound images is crucial for vascular examinations and interventions in robotics-assisted surgeries. However, current methods for ultrasound vessel segmentation face challenges in distinguishing between arteries and veins due to their morphological similarities. To address this challenge, this study introduces a novel force sensing guided segmentation approach to enhance artery-vein segmentation accuracy by leveraging their distinct deformability. Our proposed method utilizes force magnitude to identify key frames with the most significant vascular deformation in a sequence of ultrasound images. These key frames are then integrated with the current frame through attention mechanisms, with weights assigned in accordance with force magnitude. Our proposed force sensing guided framework can be seamlessly integrated into various segmentation networks and achieves significant performance improvements in multiple U-shaped networks such as U-Net, Swin-unet and Transunet. Furthermore, we contribute the first multimodal ultrasound artery-vein segmentation dataset, Mus-V, which encompasses both force and image data simultaneously. The dataset comprises 3114 ultrasound images of carotid and femoral vessels extracted from 105 videos, with corresponding force data recorded by the force sensor mounted on the US probe. Our code and dataset will be publicly available.
KiGRAS: Kinematic-Driven Generative Model for Realistic Agent Simulation
Jul 17, 2024Trajectory generation is a pivotal task in autonomous driving. Recent studies have introduced the autoregressive paradigm, leveraging the state transition model to approximate future trajectory distributions. This paradigm closely mirrors the real-world trajectory generation process and has achieved notable success. However, its potential is limited by the ineffective representation of realistic trajectories within the redundant state space. To address this limitation, we propose the Kinematic-Driven Generative Model for Realistic Agent Simulation (KiGRAS). Instead of modeling in the state space, KiGRAS factorizes the driving scene into action probability distributions at each time step, providing a compact space to represent realistic driving patterns. By establishing physical causality from actions (cause) to trajectories (effect) through the kinematic model, KiGRAS eliminates massive redundant trajectories. All states derived from actions in the cause space are constrained to be physically feasible. Furthermore, redundant trajectories representing identical action sequences are mapped to the same representation, reflecting their underlying actions. This approach significantly reduces task complexity and ensures physical feasibility. KiGRAS achieves state-of-the-art performance in Waymo's SimAgents Challenge, ranking first on the WOMD leaderboard with significantly fewer parameters than other models. The video documentation is available at \url{https://kigras-mach.github.io/KiGRAS/}.
SpreadsheetLLM: Encoding Spreadsheets for Large Language Models
Jul 12, 2024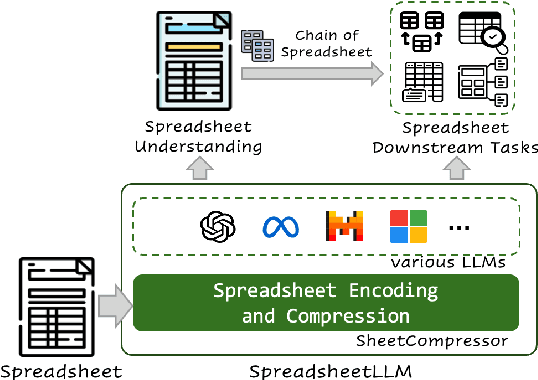

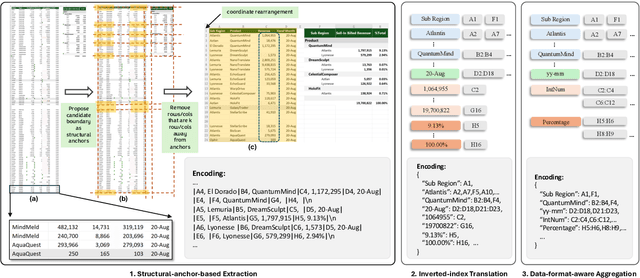
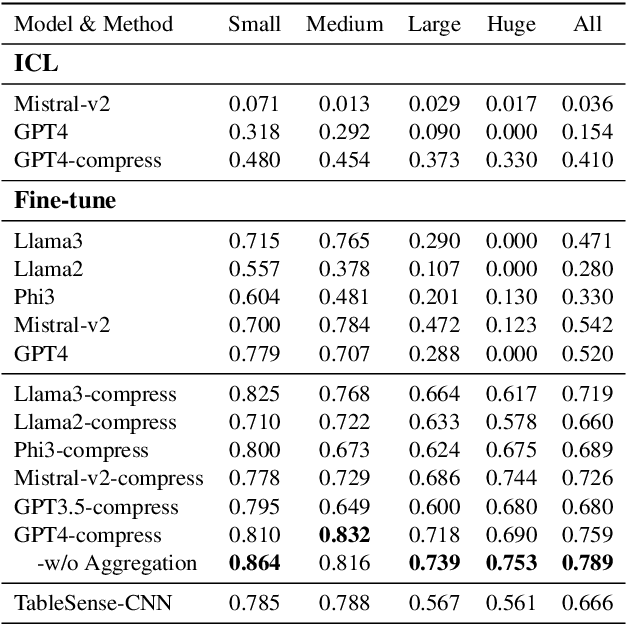
Spreadsheets, with their extensive two-dimensional grids, various layouts, and diverse formatting options, present notable challenges for large language models (LLMs). In response, we introduce SpreadsheetLLM, pioneering an efficient encoding method designed to unleash and optimize LLMs' powerful understanding and reasoning capability on spreadsheets. Initially, we propose a vanilla serialization approach that incorporates cell addresses, values, and formats. However, this approach was limited by LLMs' token constraints, making it impractical for most applications. To tackle this challenge, we develop SheetCompressor, an innovative encoding framework that compresses spreadsheets effectively for LLMs. It comprises three modules: structural-anchor-based compression, inverse index translation, and data-format-aware aggregation. It significantly improves performance in spreadsheet table detection task, outperforming the vanilla approach by 25.6% in GPT4's in-context learning setting. Moreover, fine-tuned LLM with SheetCompressor has an average compression ratio of 25 times, but achieves a state-of-the-art 78.9% F1 score, surpassing the best existing models by 12.3%. Finally, we propose Chain of Spreadsheet for downstream tasks of spreadsheet understanding and validate in a new and demanding spreadsheet QA task. We methodically leverage the inherent layout and structure of spreadsheets, demonstrating that SpreadsheetLLM is highly effective across a variety of spreadsheet tasks.
Vision Language Models for Spreadsheet Understanding: Challenges and Opportunities
May 25, 2024



This paper explores capabilities of Vision Language Models on spreadsheet comprehension. We propose three self-supervised challenges with corresponding evaluation metrics to comprehensively evaluate VLMs on Optical Character Recognition (OCR), spatial perception, and visual format recognition. Additionally, we utilize the spreadsheet table detection task to assess the overall performance of VLMs by integrating these challenges. To probe VLMs more finely, we propose three spreadsheet-to-image settings: column width adjustment, style change, and address augmentation. We propose variants of prompts to address the above tasks in different settings. Notably, to leverage the strengths of VLMs in understanding text rather than two-dimensional positioning, we propose to decode cell values on the four boundaries of the table in spreadsheet boundary detection. Our findings reveal that VLMs demonstrate promising OCR capabilities but produce unsatisfactory results due to cell omission and misalignment, and they notably exhibit insufficient spatial and format recognition skills, motivating future work to enhance VLMs' spreadsheet data comprehension capabilities using our methods to generate extensive spreadsheet-image pairs in various settings.
SparseAD: Sparse Query-Centric Paradigm for Efficient End-to-End Autonomous Driving
Apr 10, 2024



End-to-End paradigms use a unified framework to implement multi-tasks in an autonomous driving system. Despite simplicity and clarity, the performance of end-to-end autonomous driving methods on sub-tasks is still far behind the single-task methods. Meanwhile, the widely used dense BEV features in previous end-to-end methods make it costly to extend to more modalities or tasks. In this paper, we propose a Sparse query-centric paradigm for end-to-end Autonomous Driving (SparseAD), where the sparse queries completely represent the whole driving scenario across space, time and tasks without any dense BEV representation. Concretely, we design a unified sparse architecture for perception tasks including detection, tracking, and online mapping. Moreover, we revisit motion prediction and planning, and devise a more justifiable motion planner framework. On the challenging nuScenes dataset, SparseAD achieves SOTA full-task performance among end-to-end methods and significantly narrows the performance gap between end-to-end paradigms and single-task methods. Codes will be released soon.
BronchoCopilot: Towards Autonomous Robotic Bronchoscopy via Multimodal Reinforcement Learning
Mar 03, 2024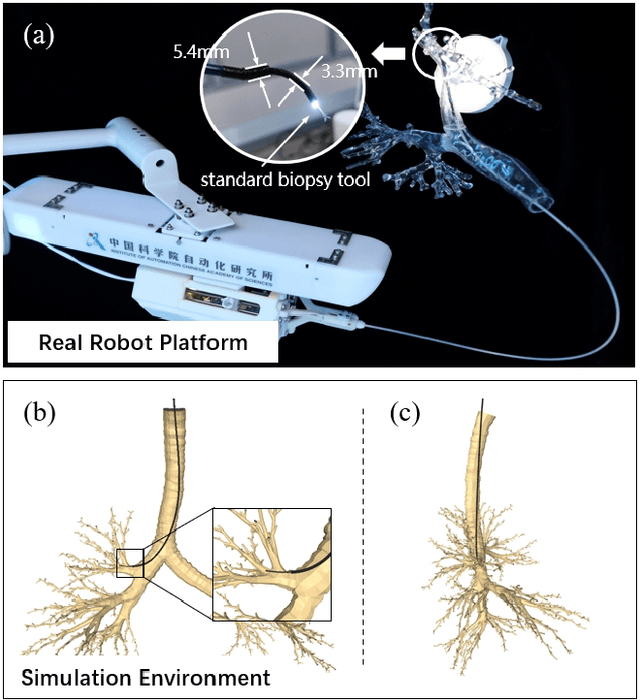
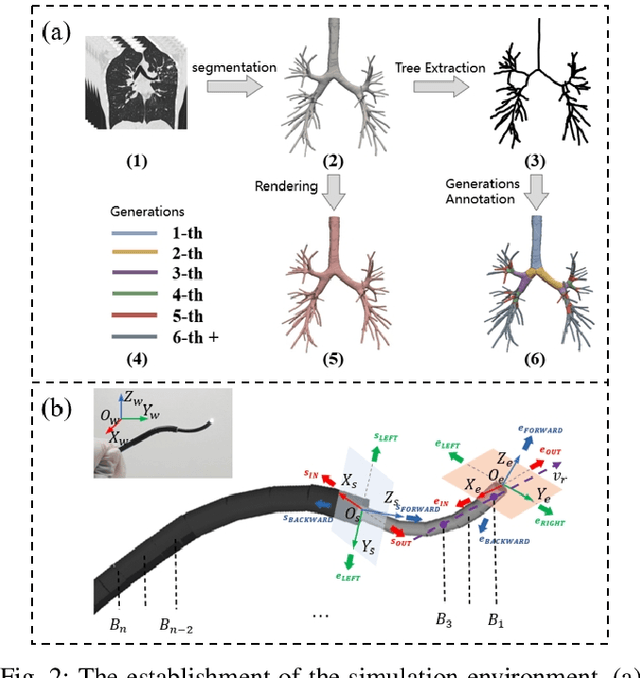
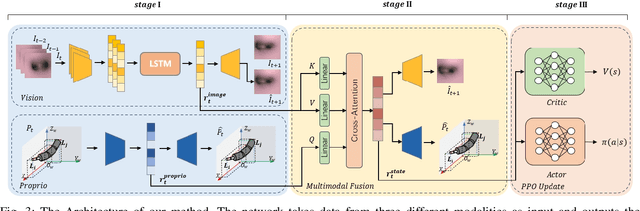

Bronchoscopy plays a significant role in the early diagnosis and treatment of lung diseases. This process demands physicians to maneuver the flexible endoscope for reaching distal lesions, particularly requiring substantial expertise when examining the airways of the upper lung lobe. With the development of artificial intelligence and robotics, reinforcement learning (RL) method has been applied to the manipulation of interventional surgical robots. However, unlike human physicians who utilize multimodal information, most of the current RL methods rely on a single modality, limiting their performance. In this paper, we propose BronchoCopilot, a multimodal RL agent designed to acquire manipulation skills for autonomous bronchoscopy. BronchoCopilot specifically integrates images from the bronchoscope camera and estimated robot poses, aiming for a higher success rate within challenging airway environment. We employ auxiliary reconstruction tasks to compress multimodal data and utilize attention mechanisms to achieve an efficient latent representation of this data, serving as input for the RL module. This framework adopts a stepwise training and fine-tuning approach to mitigate the challenges of training difficulty. Our evaluation in the realistic simulation environment reveals that BronchoCopilot, by effectively harnessing multimodal information, attains a success rate of approximately 90\% in fifth generation airways with consistent movements. Additionally, it demonstrates a robust capacity to adapt to diverse cases.