 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Model for All Tasks: Leveraging Efficient World Models in Multi-Task Planning
Sep 09, 2025In heterogeneous multi-task learning, tasks not only exhibit diverse observation and action spaces but also vary substantially in intrinsic difficulty. While conventional multi-task world models like UniZero excel in single-task settings, we find that when handling large-scale heterogeneous environments, gradient conflicts and the loss of model plasticity often constrain their sample and computational efficiency. In this work, we address these challenges from two perspectives: the single learning iteration and the overall learning process. First, we investigate the impact of key design spaces on extending UniZero to multi-task planning. We find that a Mixture-of-Experts (MoE) architecture provides the most substantial performance gains by mitigating gradient conflicts, leading to our proposed model, \textit{ScaleZero}. Second, to dynamically balance the computational load across the learning process, we introduce an online, LoRA-based \textit{dynamic parameter scaling} (DPS) strategy. This strategy progressively integrates LoRA adapters in response to task-specific progress, enabling adaptive knowledge retention and parameter expansion. Empirical evaluations on standard benchmarks such as Atari, DMControl (DMC), and Jericho demonstrate that ScaleZero, relying exclusively on online reinforcement learning with one model, attains performance on par with specialized single-task baselines. Furthermore, when augmented with our dynamic parameter scaling strategy, our method achieves competitive performance while requiring only 80\% of the single-task environment interaction steps. These findings underscore the potential of ScaleZero for effective large-scale multi-task learning. Our code is available at \textcolor{magenta}{https://github.com/opendilab/LightZero}.
DocR1: Evidence Page-Guided GRPO for Multi-Page Document Understanding
Aug 10, 2025Understanding multi-page documents poses a significant challenge for multimodal large language models (MLLMs), as it requires fine-grained visual comprehension and multi-hop reasoning across pages. While prior work has explored reinforcement learning (RL) for enhancing advanced reasoning in MLLMs, its application to multi-page document understanding remains underexplored. In this paper, we introduce DocR1, an MLLM trained with a novel RL framework, Evidence Page-Guided GRPO (EviGRPO). EviGRPO incorporates an evidence-aware reward mechanism that promotes a coarse-to-fine reasoning strategy, guiding the model to first retrieve relevant pages before generating answers. This training paradigm enables us to build high-quality models with limited supervision. To support this, we design a two-stage annotation pipeline and a curriculum learning strategy, based on which we construct two datasets: EviBench, a high-quality training set with 4.8k examples, and ArxivFullQA, an evaluation benchmark with 8.6k QA pairs based on scientific papers. Extensive experiments across a wide range of benchmarks demonstrate that DocR1 achieves state-of-the-art performance on multi-page tasks, while consistently maintaining strong results on single-page benchmarks.
SpreadsheetLLM: Encoding Spreadsheets for Large Language Models
Jul 12, 2024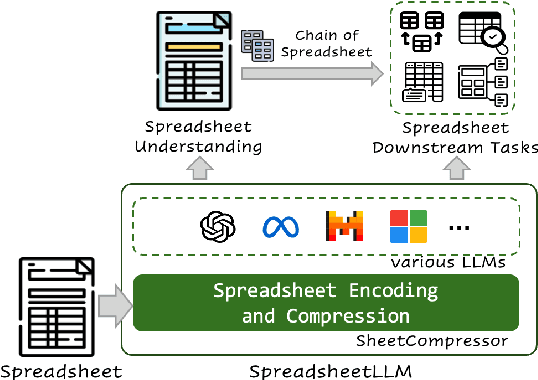

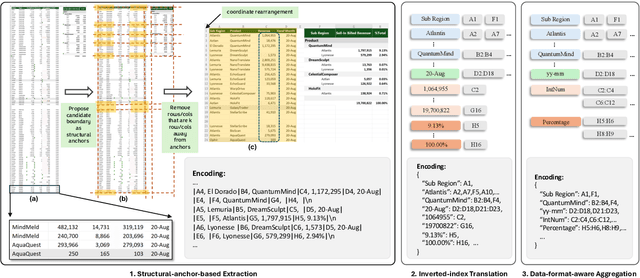
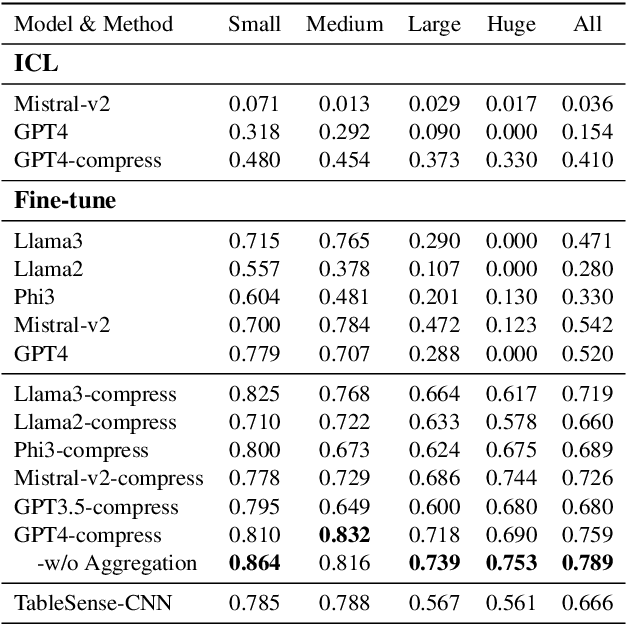
Spreadsheets, with their extensive two-dimensional grids, various layouts, and diverse formatting options, present notable challenges for large language models (LLMs). In response, we introduce SpreadsheetLLM, pioneering an efficient encoding method designed to unleash and optimize LLMs' powerful understanding and reasoning capability on spreadsheets. Initially, we propose a vanilla serialization approach that incorporates cell addresses, values, and formats. However, this approach was limited by LLMs' token constraints, making it impractical for most applications. To tackle this challenge, we develop SheetCompressor, an innovative encoding framework that compresses spreadsheets effectively for LLMs. It comprises three modules: structural-anchor-based compression, inverse index translation, and data-format-aware aggregation. It significantly improves performance in spreadsheet table detection task, outperforming the vanilla approach by 25.6% in GPT4's in-context learning setting. Moreover, fine-tuned LLM with SheetCompressor has an average compression ratio of 25 times, but achieves a state-of-the-art 78.9% F1 score, surpassing the best existing models by 12.3%. Finally, we propose Chain of Spreadsheet for downstream tasks of spreadsheet understanding and validate in a new and demanding spreadsheet QA task. We methodically leverage the inherent layout and structure of spreadsheets, demonstrating that SpreadsheetLLM is highly effective across a variety of spreadsheet tasks.
Vision Language Models for Spreadsheet Understanding: Challenges and Opportunities
May 25, 2024



This paper explores capabilities of Vision Language Models on spreadsheet comprehension. We propose three self-supervised challenges with corresponding evaluation metrics to comprehensively evaluate VLMs on Optical Character Recognition (OCR), spatial perception, and visual format recognition. Additionally, we utilize the spreadsheet table detection task to assess the overall performance of VLMs by integrating these challenges. To probe VLMs more finely, we propose three spreadsheet-to-image settings: column width adjustment, style change, and address augmentation. We propose variants of prompts to address the above tasks in different settings. Notably, to leverage the strengths of VLMs in understanding text rather than two-dimensional positioning, we propose to decode cell values on the four boundaries of the table in spreadsheet boundary detection. Our findings reveal that VLMs demonstrate promising OCR capabilities but produce unsatisfactory results due to cell omission and misalignment, and they notably exhibit insufficient spatial and format recognition skills, motivating future work to enhance VLMs' spreadsheet data comprehension capabilities using our methods to generate extensive spreadsheet-image pairs in various settings.