 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan LLMs Clean Up Your Mess? A Survey of Application-Ready Data Preparation with LLMs
Jan 22, 2026Data preparation aims to denoise raw datasets, uncover cross-dataset relationships, and extract valuable insights from them, which is essential for a wide range of data-centric applications. Driven by (i) rising demands for application-ready data (e.g., for analytics, visualization, decision-making), (ii) increasingly powerful LLM techniques, and (iii) the emergence of infrastructures that facilitate flexible agent construction (e.g., using Databricks Unity Catalog), LLM-enhanced methods are rapidly becoming a transformative and potentially dominant paradigm for data preparation. By investigating hundreds of recent literature works, this paper presents a systematic review of this evolving landscape, focusing on the use of LLM techniques to prepare data for diverse downstream tasks. First, we characterize the fundamental paradigm shift, from rule-based, model-specific pipelines to prompt-driven, context-aware, and agentic preparation workflows. Next, we introduce a task-centric taxonomy that organizes the field into three major tasks: data cleaning (e.g., standardization, error processing, imputation), data integration (e.g., entity matching, schema matching), and data enrichment (e.g., data annotation, profiling). For each task, we survey representative techniques, and highlight their respective strengths (e.g., improved generalization, semantic understanding) and limitations (e.g., the prohibitive cost of scaling LLMs, persistent hallucinations even in advanced agents, the mismatch between advanced methods and weak evaluation). Moreover, we analyze commonly used datasets and evaluation metrics (the empirical part). Finally, we discuss open research challenges and outline a forward-looking roadmap that emphasizes scalable LLM-data systems, principled designs for reliable agentic workflows, and robust evaluation protocols.
Jupiter: Enhancing LLM Data Analysis Capabilities via Notebook and Inference-Time Value-Guided Search
Sep 11, 2025

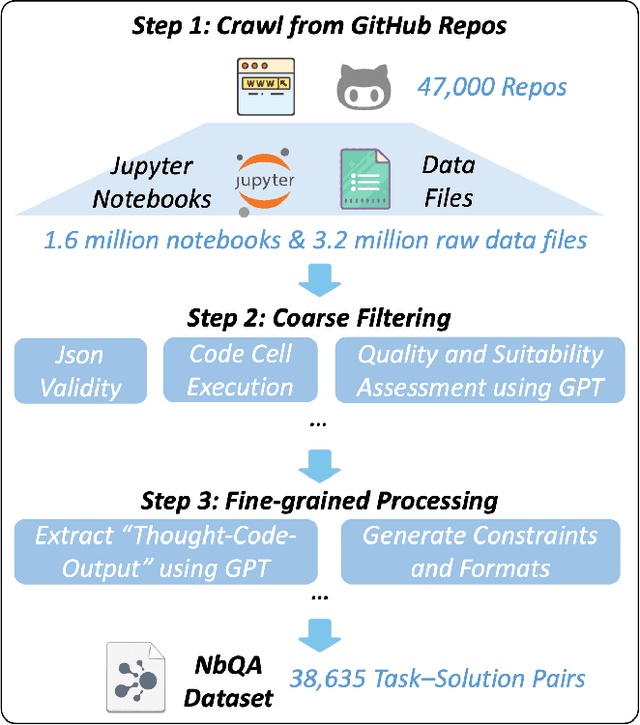
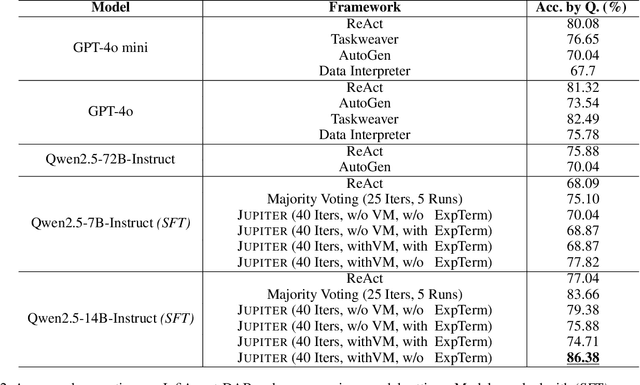
Large language models (LLMs) have shown great promise in automating data science workflows, but existing models still struggle with multi-step reasoning and tool use, which limits their effectiveness on complex data analysis tasks. To address this, we propose a scalable pipeline that extracts high-quality, tool-based data analysis tasks and their executable multi-step solutions from real-world Jupyter notebooks and associated data files. Using this pipeline, we introduce NbQA, a large-scale dataset of standardized task-solution pairs that reflect authentic tool-use patterns in practical data science scenarios. To further enhance multi-step reasoning, we present Jupiter, a framework that formulates data analysis as a search problem and applies Monte Carlo Tree Search (MCTS) to generate diverse solution trajectories for value model learning. During inference, Jupiter combines the value model and node visit counts to efficiently collect executable multi-step plans with minimal search steps. Experimental results show that Qwen2.5-7B and 14B-Instruct models on NbQA solve 77.82% and 86.38% of tasks on InfiAgent-DABench, respectively-matching or surpassing GPT-4o and advanced agent frameworks. Further evaluations demonstrate improved generalization and stronger tool-use reasoning across diverse multi-step reasoning tasks.
MMTU: A Massive Multi-Task Table Understanding and Reasoning Benchmark
Jun 05, 2025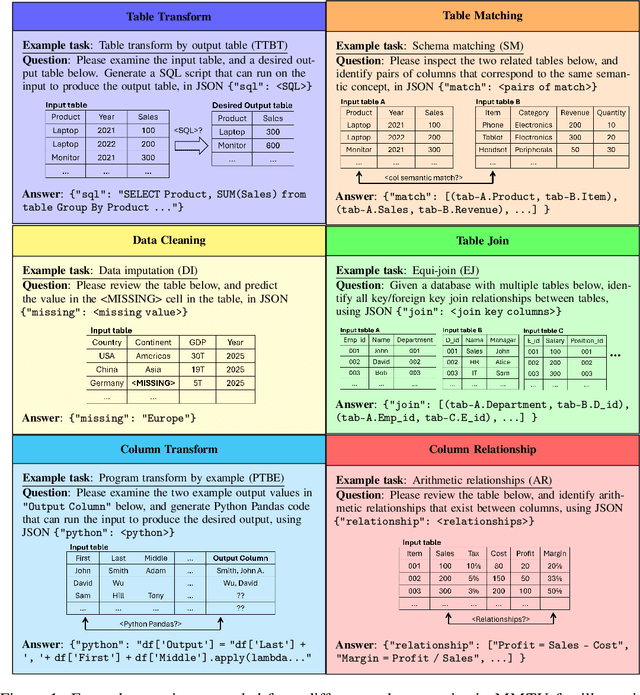
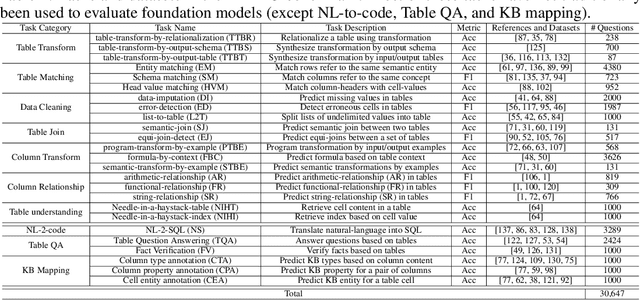

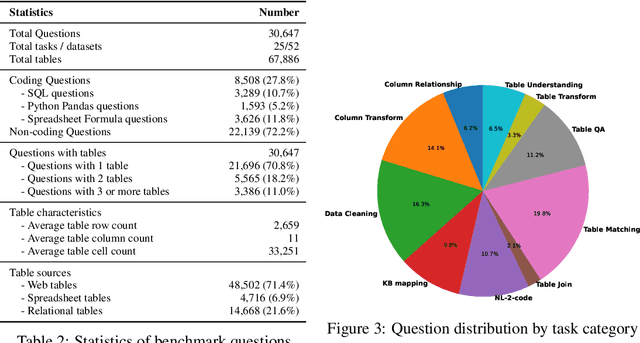
Tables and table-based use cases play a crucial role in many important real-world applications, such as spreadsheets, databases, and computational notebooks, which traditionally require expert-level users like data engineers, data analysts, and database administrators to operate. Although LLMs have shown remarkable progress in working with tables (e.g., in spreadsheet and database copilot scenarios), comprehensive benchmarking of such capabilities remains limited. In contrast to an extensive and growing list of NLP benchmarks, evaluations of table-related tasks are scarce, and narrowly focus on tasks like NL-to-SQL and Table-QA, overlooking the broader spectrum of real-world tasks that professional users face. This gap limits our understanding and model progress in this important area. In this work, we introduce MMTU, a large-scale benchmark with over 30K questions across 25 real-world table tasks, designed to comprehensively evaluate models ability to understand, reason, and manipulate real tables at the expert-level. These tasks are drawn from decades' worth of computer science research on tabular data, with a focus on complex table tasks faced by professional users. We show that MMTU require a combination of skills -- including table understanding, reasoning, and coding -- that remain challenging for today's frontier models, where even frontier reasoning models like OpenAI o4-mini and DeepSeek R1 score only around 60%, suggesting significant room for improvement. We highlight key findings in our evaluation using MMTU and hope that this benchmark drives further advances in understanding and developing foundation models for structured data processing and analysis. Our code and data are available at https://github.com/MMTU-Benchmark/MMTU and https://huggingface.co/datasets/MMTU-benchmark/MMTU.
Auto-Test: Learning Semantic-Domain Constraints for Unsupervised Error Detection in Tables
Apr 14, 2025
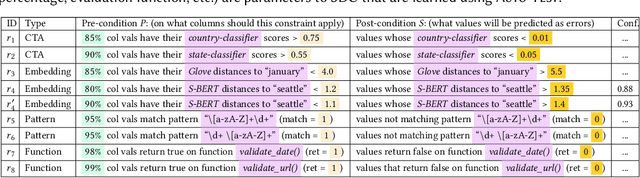


Data cleaning is a long-standing challenge in data management. While powerful logic and statistical algorithms have been developed to detect and repair data errors in tables, existing algorithms predominantly rely on domain-experts to first manually specify data-quality constraints specific to a given table, before data cleaning algorithms can be applied. In this work, we propose a new class of data-quality constraints that we call Semantic-Domain Constraints, which can be reliably inferred and automatically applied to any tables, without requiring domain-experts to manually specify on a per-table basis. We develop a principled framework to systematically learn such constraints from table corpora using large-scale statistical tests, which can further be distilled into a core set of constraints using our optimization framework, with provable quality guarantees. Extensive evaluations show that this new class of constraints can be used to both (1) directly detect errors on real tables in the wild, and (2) augment existing expert-driven data-cleaning techniques as a new class of complementary constraints. Our extensively labeled benchmark dataset with 2400 real data columns, as well as our code are available at https://github.com/qixuchen/AutoTest to facilitate future research.
TableLoRA: Low-rank Adaptation on Table Structure Understanding for Large Language Models
Mar 06, 2025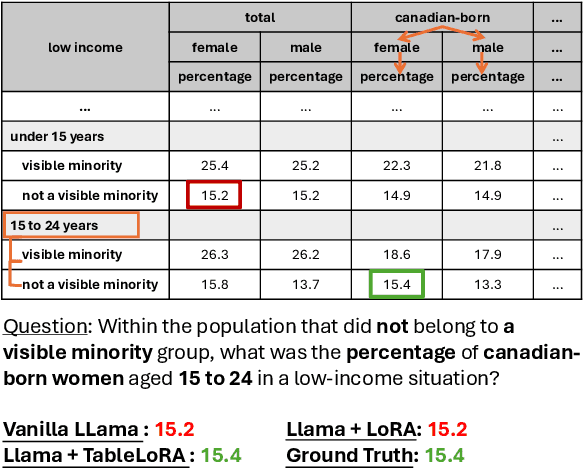
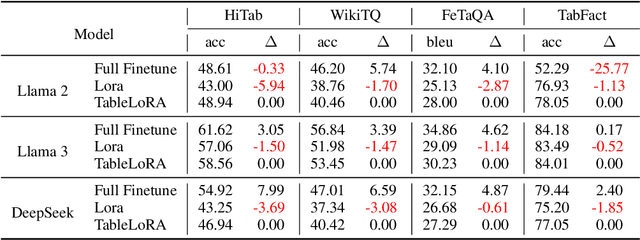
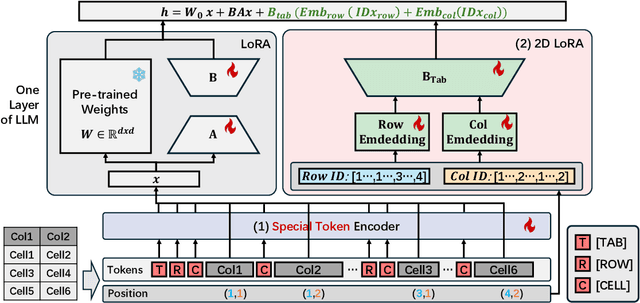
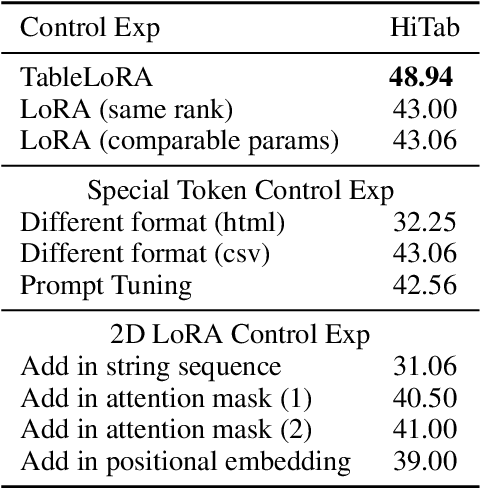
Tabular data are crucial in many fields and their understanding by large language models (LLMs) under high parameter efficiency paradigm is important. However, directly applying parameter-efficient fine-tuning (PEFT) techniques to tabular tasks presents significant challenges, particularly in terms of better table serialization and the representation of two-dimensional structured information within a one-dimensional sequence. To address this, we propose TableLoRA, a module designed to improve LLMs' understanding of table structure during PEFT. It incorporates special tokens for serializing tables with special token encoder and uses 2D LoRA to encode low-rank information on cell positions. Experiments on four tabular-related datasets demonstrate that TableLoRA consistently outperforms vanilla LoRA and surpasses various table encoding methods tested in control experiments. These findings reveal that TableLoRA, as a table-specific LoRA, enhances the ability of LLMs to process tabular data effectively, especially in low-parameter settings, demonstrating its potential as a robust solution for handling table-related tasks.
Table-LLM-Specialist: Language Model Specialists for Tables using Iterative Generator-Validator Fine-tuning
Oct 16, 2024



In this work, we propose Table-LLM-Specialist, or Table-Specialist for short, as a new self-trained fine-tuning paradigm specifically designed for table tasks. Our insight is that for each table task, there often exist two dual versions of the same task, one generative and one classification in nature. Leveraging their duality, we propose a Generator-Validator paradigm, to iteratively generate-then-validate training data from language-models, to fine-tune stronger \sys models that can specialize in a given task, without requiring manually-labeled data. Our extensive evaluations suggest that our Table-Specialist has (1) \textit{strong performance} on diverse table tasks over vanilla language-models -- for example, Table-Specialist fine-tuned on GPT-3.5 not only outperforms vanilla GPT-3.5, but can often match or surpass GPT-4 level quality, (2) \textit{lower cost} to deploy, because when Table-Specialist fine-tuned on GPT-3.5 achieve GPT-4 level quality, it becomes possible to deploy smaller models with lower latency and inference cost, with comparable quality, and (3) \textit{better generalizability} when evaluated across multiple benchmarks, since \sys is fine-tuned on a broad range of training data systematically generated from diverse real tables. Our code and data will be available at https://github.com/microsoft/Table-LLM-Specialist.
SpreadsheetLLM: Encoding Spreadsheets for Large Language Models
Jul 12, 2024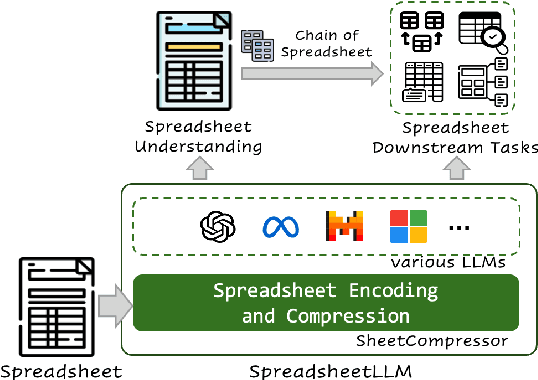

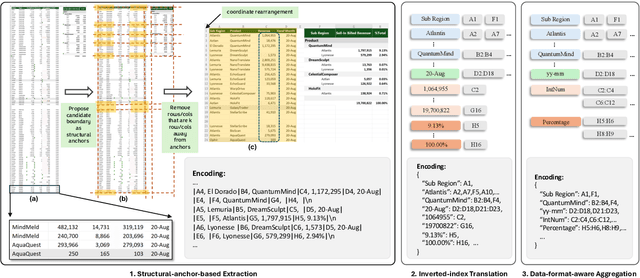
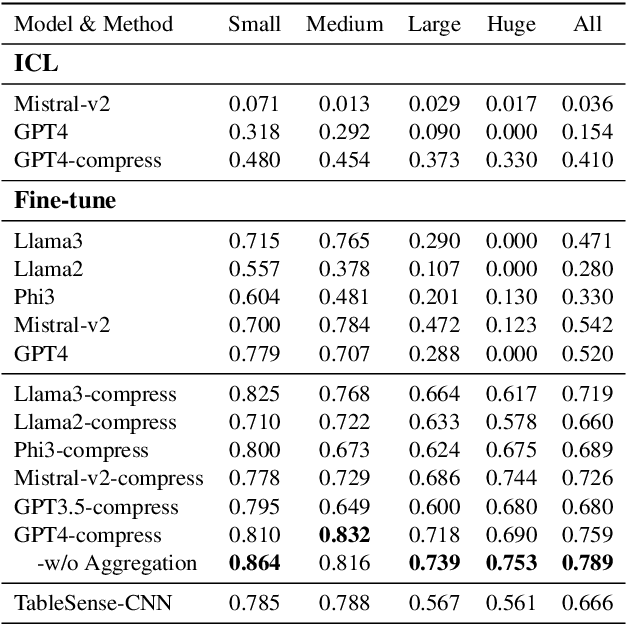
Spreadsheets, with their extensive two-dimensional grids, various layouts, and diverse formatting options, present notable challenges for large language models (LLMs). In response, we introduce SpreadsheetLLM, pioneering an efficient encoding method designed to unleash and optimize LLMs' powerful understanding and reasoning capability on spreadsheets. Initially, we propose a vanilla serialization approach that incorporates cell addresses, values, and formats. However, this approach was limited by LLMs' token constraints, making it impractical for most applications. To tackle this challenge, we develop SheetCompressor, an innovative encoding framework that compresses spreadsheets effectively for LLMs. It comprises three modules: structural-anchor-based compression, inverse index translation, and data-format-aware aggregation. It significantly improves performance in spreadsheet table detection task, outperforming the vanilla approach by 25.6% in GPT4's in-context learning setting. Moreover, fine-tuned LLM with SheetCompressor has an average compression ratio of 25 times, but achieves a state-of-the-art 78.9% F1 score, surpassing the best existing models by 12.3%. Finally, we propose Chain of Spreadsheet for downstream tasks of spreadsheet understanding and validate in a new and demanding spreadsheet QA task. We methodically leverage the inherent layout and structure of spreadsheets, demonstrating that SpreadsheetLLM is highly effective across a variety of spreadsheet tasks.
Vision Language Models for Spreadsheet Understanding: Challenges and Opportunities
May 25, 2024



This paper explores capabilities of Vision Language Models on spreadsheet comprehension. We propose three self-supervised challenges with corresponding evaluation metrics to comprehensively evaluate VLMs on Optical Character Recognition (OCR), spatial perception, and visual format recognition. Additionally, we utilize the spreadsheet table detection task to assess the overall performance of VLMs by integrating these challenges. To probe VLMs more finely, we propose three spreadsheet-to-image settings: column width adjustment, style change, and address augmentation. We propose variants of prompts to address the above tasks in different settings. Notably, to leverage the strengths of VLMs in understanding text rather than two-dimensional positioning, we propose to decode cell values on the four boundaries of the table in spreadsheet boundary detection. Our findings reveal that VLMs demonstrate promising OCR capabilities but produce unsatisfactory results due to cell omission and misalignment, and they notably exhibit insufficient spatial and format recognition skills, motivating future work to enhance VLMs' spreadsheet data comprehension capabilities using our methods to generate extensive spreadsheet-image pairs in various settings.
Auto-Formula: Recommend Formulas in Spreadsheets using Contrastive Learning for Table Representations
Apr 19, 2024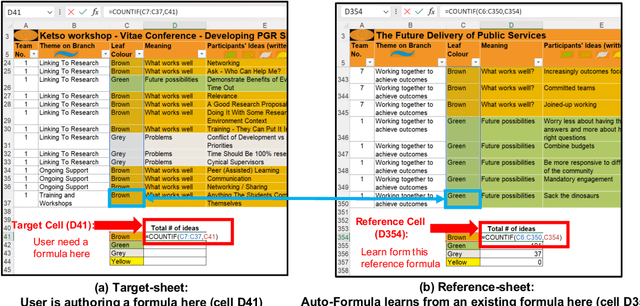
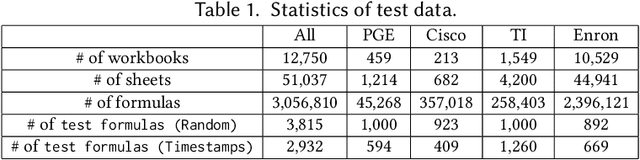
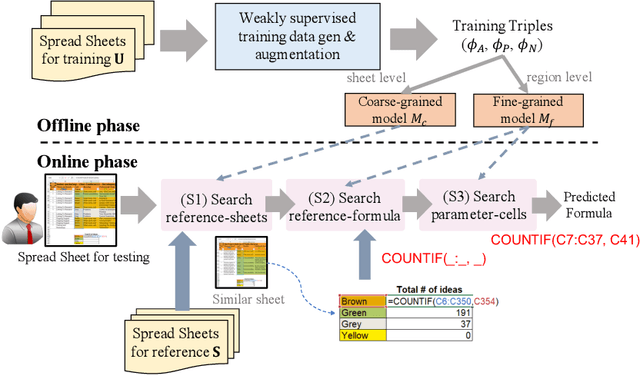

Spreadsheets are widely recognized as the most popular end-user programming tools, which blend the power of formula-based computation, with an intuitive table-based interface. Today, spreadsheets are used by billions of users to manipulate tables, most of whom are neither database experts nor professional programmers. Despite the success of spreadsheets, authoring complex formulas remains challenging, as non-technical users need to look up and understand non-trivial formula syntax. To address this pain point, we leverage the observation that there is often an abundance of similar-looking spreadsheets in the same organization, which not only have similar data, but also share similar computation logic encoded as formulas. We develop an Auto-Formula system that can accurately predict formulas that users want to author in a target spreadsheet cell, by learning and adapting formulas that already exist in similar spreadsheets, using contrastive-learning techniques inspired by "similar-face recognition" from compute vision. Extensive evaluations on over 2K test formulas extracted from real enterprise spreadsheets show the effectiveness of Auto-Formula over alternatives. Our benchmark data is available at https://github.com/microsoft/Auto-Formula to facilitate future research.
Table-GPT: Table-tuned GPT for Diverse Table Tasks
Oct 13, 2023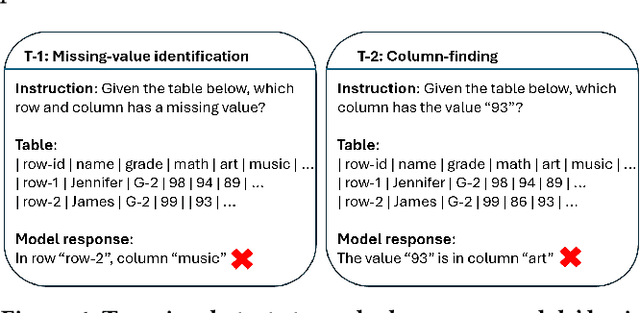
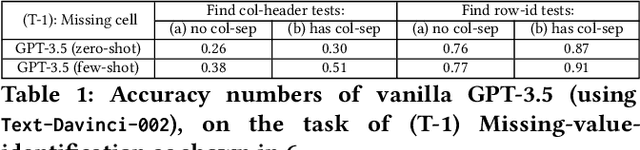

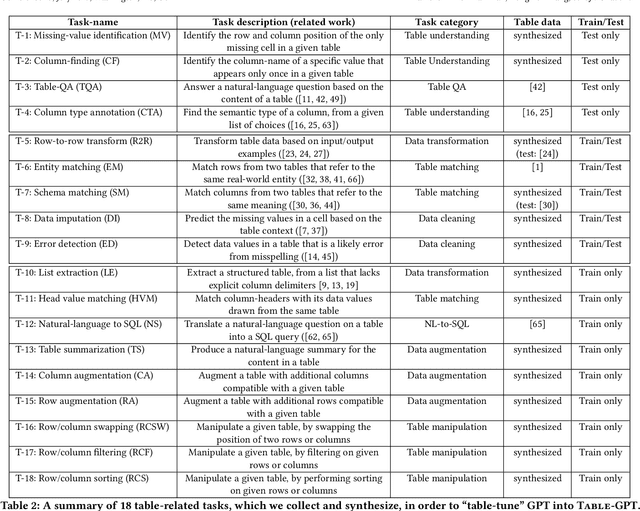
Language models, such as GPT-3.5 and ChatGPT, demonstrate remarkable abilities to follow diverse human instructions and perform a wide range of tasks. However, when probing language models using a range of basic table-understanding tasks, we observe that today's language models are still sub-optimal in many table-related tasks, likely because they are pre-trained predominantly on \emph{one-dimensional} natural-language texts, whereas relational tables are \emph{two-dimensional} objects. In this work, we propose a new "\emph{table-tuning}" paradigm, where we continue to train/fine-tune language models like GPT-3.5 and ChatGPT, using diverse table-tasks synthesized from real tables as training data, with the goal of enhancing language models' ability to understand tables and perform table tasks. We show that our resulting Table-GPT models demonstrate (1) better \emph{table-understanding} capabilities, by consistently outperforming the vanilla GPT-3.5 and ChatGPT, on a wide-range of table tasks, including holdout unseen tasks, and (2) strong \emph{generalizability}, in its ability to respond to diverse human instructions to perform new table-tasks, in a manner similar to GPT-3.5 and ChatGPT.