 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonte Carlo Tree Search with Reasoning Path Refinement for Small Language Models in Conversational Text-to-NoSQL
Feb 13, 2026NoSQL databases have been widely adopted in big data analytics, geospatial applications, and healthcare services, due to their flexibility and scalability. However, querying NoSQL databases requires specialized technical expertise, creating a high barrier for users. While recent studies have explored text-to-NoSQL problem, they primarily focus on single-turn interactions, ignoring the conversational nature of real-world queries. To bridge this gap, we introduce the Conversational Text-to-NoSQL task, which generates NoSQL queries given a natural language question, a NoSQL database, and the dialogue history. To address this task, we propose Stage-MCTS, a framework that endows small language models (SLMs) with NoSQL-specific reasoning capabilities by formulating query generation as a search problem. The framework employs Monte Carlo Tree Search (MCTS) guided by a rule-based reward to produce stepwise reasoning data, followed by progressive supervised fine-tuning (SFT) and self-training strategies. We further construct CoNoSQL, a cross-domain dataset with over 2,000 dialogues and 150 databases, to support evaluation. Experiments demonstrate that our approach outperforms state-of-the-art large reasoning models, improving execution value match (EVM) accuracy by up to 7.93%.
TS-Memory: Plug-and-Play Memory for Time Series Foundation Models
Feb 12, 2026Time Series Foundation Models (TSFMs) achieve strong zero-shot forecasting through large-scale pre-training, but adapting them to downstream domains under distribution shift remains challenging. Existing solutions face a trade-off: Parametric Adaptation can cause catastrophic forgetting and requires costly multi-domain maintenance, while Non-Parametric Retrieval improves forecasts but incurs high inference latency due to datastore search. We propose Parametric Memory Distillation and implement it as TS-Memory, a lightweight memory adapter that augments frozen TSFMs. TS-Memory is trained in two stages. First, we construct an offline, leakage-safe kNN teacher that synthesizes confidence-aware quantile targets from retrieved futures. Second, we distill this retrieval-induced distributional correction into a lightweight memory adapter via confidence-gated supervision. During inference, TS-Memory fuses memory and backbone predictions with constant-time overhead, enabling retrieval-free deployment. Experiments across diverse TSFMs and benchmarks demonstrate consistent improvements in both point and probabilistic forecasting over representative adaptation methods, with efficiency comparable to the frozen backbone.
MultiVis-Agent: A Multi-Agent Framework with Logic Rules for Reliable and Comprehensive Cross-Modal Data Visualization
Jan 26, 2026Real-world visualization tasks involve complex, multi-modal requirements that extend beyond simple text-to-chart generation, requiring reference images, code examples, and iterative refinement. Current systems exhibit fundamental limitations: single-modality input, one-shot generation, and rigid workflows. While LLM-based approaches show potential for these complex requirements, they introduce reliability challenges including catastrophic failures and infinite loop susceptibility. To address this gap, we propose MultiVis-Agent, a logic rule-enhanced multi-agent framework for reliable multi-modal and multi-scenario visualization generation. Our approach introduces a four-layer logic rule framework that provides mathematical guarantees for system reliability while maintaining flexibility. Unlike traditional rule-based systems, our logic rules are mathematical constraints that guide LLM reasoning rather than replacing it. We formalize the MultiVis task spanning four scenarios from basic generation to iterative refinement, and develop MultiVis-Bench, a benchmark with over 1,000 cases for multi-modal visualization evaluation. Extensive experiments demonstrate that our approach achieves 75.63% visualization score on challenging tasks, significantly outperforming baselines (57.54-62.79%), with task completion rates of 99.58% and code execution success rates of 94.56% (vs. 74.48% and 65.10% without logic rules), successfully addressing both complexity and reliability challenges in automated visualization generation.
Auto-Test: Learning Semantic-Domain Constraints for Unsupervised Error Detection in Tables
Apr 14, 2025
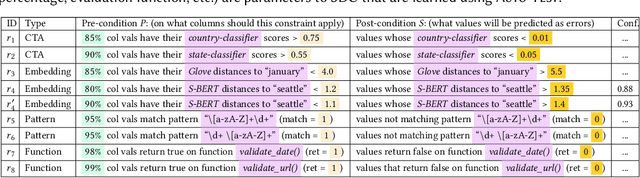


Data cleaning is a long-standing challenge in data management. While powerful logic and statistical algorithms have been developed to detect and repair data errors in tables, existing algorithms predominantly rely on domain-experts to first manually specify data-quality constraints specific to a given table, before data cleaning algorithms can be applied. In this work, we propose a new class of data-quality constraints that we call Semantic-Domain Constraints, which can be reliably inferred and automatically applied to any tables, without requiring domain-experts to manually specify on a per-table basis. We develop a principled framework to systematically learn such constraints from table corpora using large-scale statistical tests, which can further be distilled into a core set of constraints using our optimization framework, with provable quality guarantees. Extensive evaluations show that this new class of constraints can be used to both (1) directly detect errors on real tables in the wild, and (2) augment existing expert-driven data-cleaning techniques as a new class of complementary constraints. Our extensively labeled benchmark dataset with 2400 real data columns, as well as our code are available at https://github.com/qixuchen/AutoTest to facilitate future research.
Practical and Asymptotically Optimal Quantization of High-Dimensional Vectors in Euclidean Space for Approximate Nearest Neighbor Search
Sep 16, 2024



Approximate nearest neighbor (ANN) query in high-dimensional Euclidean space is a key operator in database systems. For this query, quantization is a popular family of methods developed for compressing vectors and reducing memory consumption. Recently, a method called RaBitQ achieves the state-of-the-art performance among these methods. It produces better empirical performance in both accuracy and efficiency when using the same compression rate and provides rigorous theoretical guarantees. However, the method is only designed for compressing vectors at high compression rates (32x) and lacks support for achieving higher accuracy by using more space. In this paper, we introduce a new quantization method to address this limitation by extending RaBitQ. The new method inherits the theoretical guarantees of RaBitQ and achieves the asymptotic optimality in terms of the trade-off between space and error bounds as to be proven in this study. Additionally, we present efficient implementations of the method, enabling its application to ANN queries to reduce both space and time consumption. Extensive experiments on real-world datasets confirm that our method consistently outperforms the state-of-the-art baselines in both accuracy and efficiency when using the same amount of memory.
DataVisT5: A Pre-trained Language Model for Jointly Understanding Text and Data Visualization
Aug 14, 2024



Data visualization (DV) is the fundamental and premise tool to improve the efficiency in conveying the insights behind the big data, which has been widely accepted in existing data-driven world. Task automation in DV, such as converting natural language queries to visualizations (i.e., text-to-vis), generating explanations from visualizations (i.e., vis-to-text), answering DV-related questions in free form (i.e. FeVisQA), and explicating tabular data (i.e., table-to-text), is vital for advancing the field. Despite their potential, the application of pre-trained language models (PLMs) like T5 and BERT in DV has been limited by high costs and challenges in handling cross-modal information, leading to few studies on PLMs for DV. We introduce \textbf{DataVisT5}, a novel PLM tailored for DV that enhances the T5 architecture through a hybrid objective pre-training and multi-task fine-tuning strategy, integrating text and DV datasets to effectively interpret cross-modal semantics. Extensive evaluations on public datasets show that DataVisT5 consistently outperforms current state-of-the-art models on various DV-related tasks. We anticipate that DataVisT5 will not only inspire further research on vertical PLMs but also expand the range of applications for PLMs.
Towards Robustness of Text-to-Visualization Translation against Lexical and Phrasal Variability
Apr 11, 2024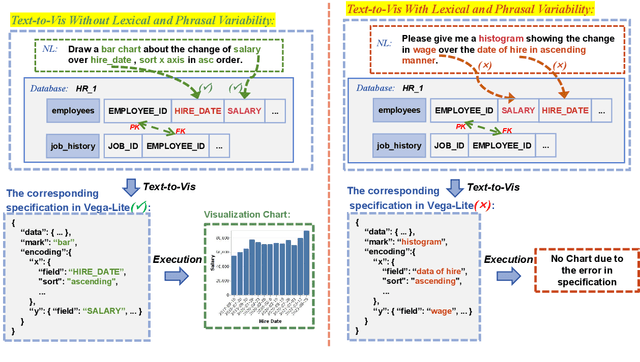
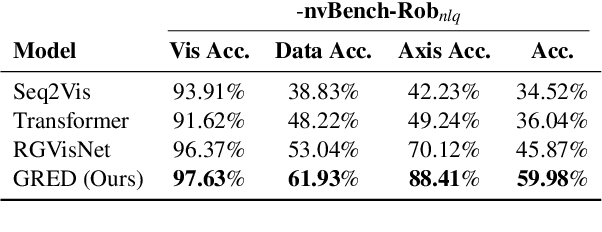
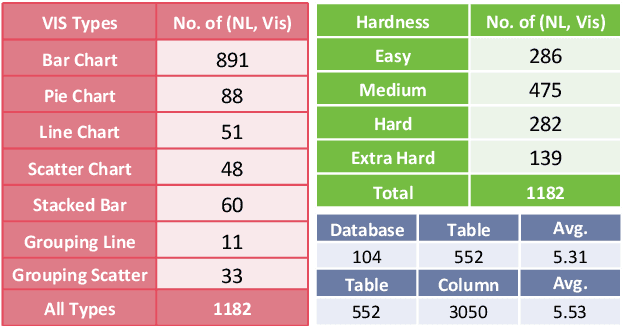
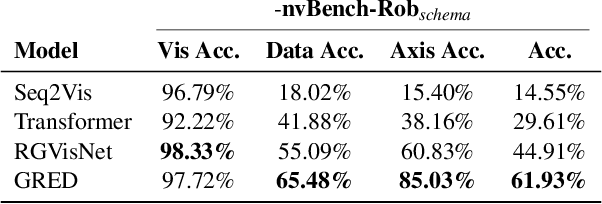
Text-to-Vis is an emerging task in the natural language processing (NLP) area that aims to automatically generate data visualizations from natural language questions (NLQs). Despite their progress, existing text-to-vis models often heavily rely on lexical matching between words in the questions and tokens in data schemas. This overreliance on lexical matching may lead to a diminished level of model robustness against input variations. In this study, we thoroughly examine the robustness of current text-to-vis models, an area that has not previously been explored. In particular, we construct the first robustness dataset nvBench-Rob, which contains diverse lexical and phrasal variations based on the original text-to-vis benchmark nvBench. Then, we found that the performance of existing text-to-vis models on this new dataset dramatically drops, implying that these methods exhibit inadequate robustness overall. Finally, we propose a novel framework based on Retrieval-Augmented Generation (RAG) technique, named GRED, specifically designed to address input perturbations in these two variants. The framework consists of three parts: NLQ-Retrieval Generator, Visualization Query-Retrieval Retuner and Annotation-based Debugger, which are used to tackle the challenges posed by natural language variants, programming style differences and data schema variants, respectively. Extensive experimental evaluations show that, compared to the state-of-the-art model RGVisNet in the Text-to-Vis field, GRED performs better in terms of model robustness, with a 32% increase in accuracy on the proposed nvBench-Rob dataset.
Natural Language Interfaces for Tabular Data Querying and Visualization: A Survey
Oct 27, 2023



The emergence of natural language processing has revolutionized the way users interact with tabular data, enabling a shift from traditional query languages and manual plotting to more intuitive, language-based interfaces. The rise of large language models (LLMs) such as ChatGPT and its successors has further advanced this field, opening new avenues for natural language processing techniques. This survey presents a comprehensive overview of natural language interfaces for tabular data querying and visualization, which allow users to interact with data using natural language queries. We introduce the fundamental concepts and techniques underlying these interfaces with a particular emphasis on semantic parsing, the key technology facilitating the translation from natural language to SQL queries or data visualization commands. We then delve into the recent advancements in Text-to-SQL and Text-to-Vis problems from the perspectives of datasets, methodologies, metrics, and system designs. This includes a deep dive into the influence of LLMs, highlighting their strengths, limitations, and potential for future improvements. Through this survey, we aim to provide a roadmap for researchers and practitioners interested in developing and applying natural language interfaces for data interaction in the era of large language models.
SR-PredictAO: Session-based Recommendation with High-Capability Predictor Add-On
Sep 20, 2023



Session-based recommendation, aiming at making the prediction of the user's next item click based on the information in a single session only even in the presence of some random user's behavior, is a complex problem. This complex problem requires a high-capability model of predicting the user's next action. Most (if not all) existing models follow the encoder-predictor paradigm where all studies focus on how to optimize the encoder module extensively in the paradigm but they ignore how to optimize the predictor module. In this paper, we discover the existing critical issue of the low-capability predictor module among existing models. Motivated by this, we propose a novel framework called \emph{\underline{S}ession-based \underline{R}ecommendation with \underline{Pred}ictor \underline{A}dd-\underline{O}n} (SR-PredictAO). In this framework, we propose a high-capability predictor module which could alleviate the effect of random user's behavior for prediction. It is worth mentioning that this framework could be applied to any existing models, which could give opportunities for further optimizing the framework. Extensive experiments on two real benchmark datasets for three state-of-the-art models show that \emph{SR-PredictAO} out-performs the current state-of-the-art model by up to 2.9\% in HR@20 and 2.3\% in MRR@20. More importantly, the improvement is consistent across almost all the existing models on all datasets, which could be regarded as a significant contribution in the field.
Automatic Data Visualization Generation from Chinese Natural Language Questions
Sep 14, 2023



Data visualization has emerged as an effective tool for getting insights from massive datasets. Due to the hardness of manipulating the programming languages of data visualization, automatic data visualization generation from natural languages (Text-to-Vis) is becoming increasingly popular. Despite the plethora of research effort on the English Text-to-Vis, studies have yet to be conducted on data visualization generation from questions in Chinese. Motivated by this, we propose a Chinese Text-to-Vis dataset in the paper and demonstrate our first attempt to tackle this problem. Our model integrates multilingual BERT as the encoder, boosts the cross-lingual ability, and infuses the $n$-gram information into our word representation learning. Our experimental results show that our dataset is challenging and deserves further research.