 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Paper Reviewing with Heterogeneous Graph Reasoning over LLM-Simulated Reviewer-Author Debates
Nov 11, 2025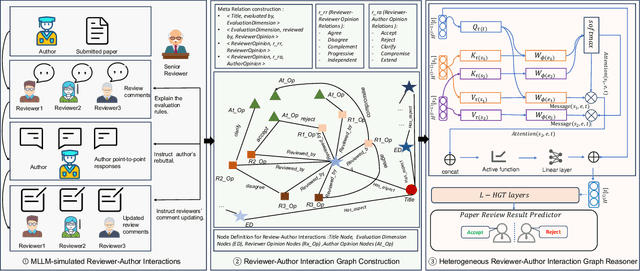
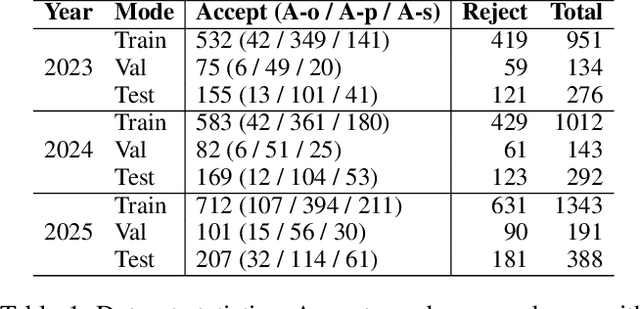
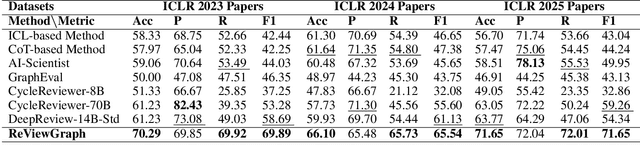
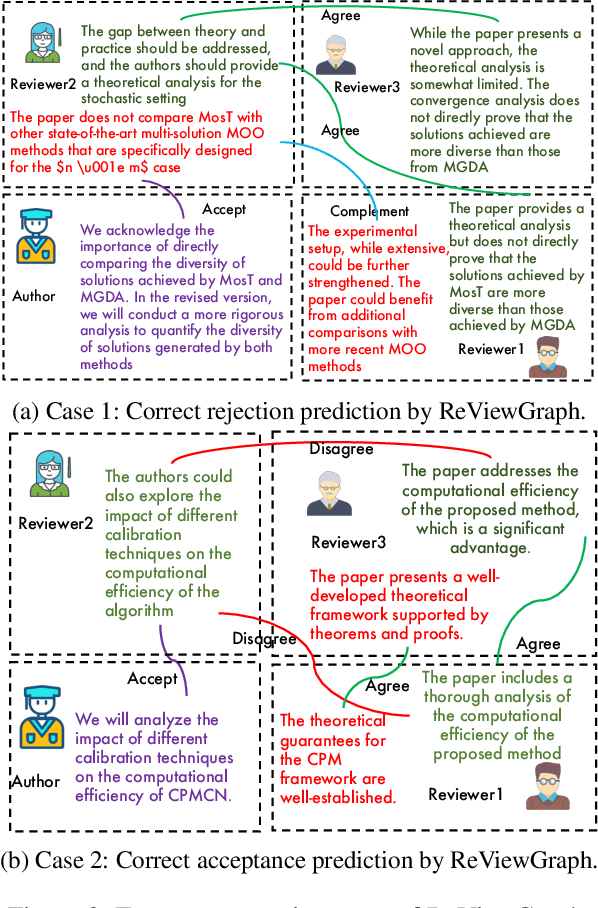
Existing paper review methods often rely on superficial manuscript features or directly on large language models (LLMs), which are prone to hallucinations, biased scoring, and limited reasoning capabilities. Moreover, these methods often fail to capture the complex argumentative reasoning and negotiation dynamics inherent in reviewer-author interactions. To address these limitations, we propose ReViewGraph (Reviewer-Author Debates Graph Reasoner), a novel framework that performs heterogeneous graph reasoning over LLM-simulated multi-round reviewer-author debates. In our approach, reviewer-author exchanges are simulated through LLM-based multi-agent collaboration. Diverse opinion relations (e.g., acceptance, rejection, clarification, and compromise) are then explicitly extracted and encoded as typed edges within a heterogeneous interaction graph. By applying graph neural networks to reason over these structured debate graphs, ReViewGraph captures fine-grained argumentative dynamics and enables more informed review decisions. Extensive experiments on three datasets demonstrate that ReViewGraph outperforms strong baselines with an average relative improvement of 15.73%, underscoring the value of modeling detailed reviewer-author debate structures.
xJailbreak: Representation Space Guided Reinforcement Learning for Interpretable LLM Jailbreaking
Jan 30, 2025



Safety alignment mechanism are essential for preventing large language models (LLMs) from generating harmful information or unethical content. However, cleverly crafted prompts can bypass these safety measures without accessing the model's internal parameters, a phenomenon known as black-box jailbreak. Existing heuristic black-box attack methods, such as genetic algorithms, suffer from limited effectiveness due to their inherent randomness, while recent reinforcement learning (RL) based methods often lack robust and informative reward signals. To address these challenges, we propose a novel black-box jailbreak method leveraging RL, which optimizes prompt generation by analyzing the embedding proximity between benign and malicious prompts. This approach ensures that the rewritten prompts closely align with the intent of the original prompts while enhancing the attack's effectiveness. Furthermore, we introduce a comprehensive jailbreak evaluation framework incorporating keywords, intent matching, and answer validation to provide a more rigorous and holistic assessment of jailbreak success. Experimental results show the superiority of our approach, achieving state-of-the-art (SOTA) performance on several prominent open and closed-source LLMs, including Qwen2.5-7B-Instruct, Llama3.1-8B-Instruct, and GPT-4o-0806. Our method sets a new benchmark in jailbreak attack effectiveness, highlighting potential vulnerabilities in LLMs. The codebase for this work is available at https://github.com/Aegis1863/xJailbreak.
DataVisT5: A Pre-trained Language Model for Jointly Understanding Text and Data Visualization
Aug 14, 2024



Data visualization (DV) is the fundamental and premise tool to improve the efficiency in conveying the insights behind the big data, which has been widely accepted in existing data-driven world. Task automation in DV, such as converting natural language queries to visualizations (i.e., text-to-vis), generating explanations from visualizations (i.e., vis-to-text), answering DV-related questions in free form (i.e. FeVisQA), and explicating tabular data (i.e., table-to-text), is vital for advancing the field. Despite their potential, the application of pre-trained language models (PLMs) like T5 and BERT in DV has been limited by high costs and challenges in handling cross-modal information, leading to few studies on PLMs for DV. We introduce \textbf{DataVisT5}, a novel PLM tailored for DV that enhances the T5 architecture through a hybrid objective pre-training and multi-task fine-tuning strategy, integrating text and DV datasets to effectively interpret cross-modal semantics. Extensive evaluations on public datasets show that DataVisT5 consistently outperforms current state-of-the-art models on various DV-related tasks. We anticipate that DataVisT5 will not only inspire further research on vertical PLMs but also expand the range of applications for PLMs.