 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiVis-Agent: A Multi-Agent Framework with Logic Rules for Reliable and Comprehensive Cross-Modal Data Visualization
Jan 26, 2026Real-world visualization tasks involve complex, multi-modal requirements that extend beyond simple text-to-chart generation, requiring reference images, code examples, and iterative refinement. Current systems exhibit fundamental limitations: single-modality input, one-shot generation, and rigid workflows. While LLM-based approaches show potential for these complex requirements, they introduce reliability challenges including catastrophic failures and infinite loop susceptibility. To address this gap, we propose MultiVis-Agent, a logic rule-enhanced multi-agent framework for reliable multi-modal and multi-scenario visualization generation. Our approach introduces a four-layer logic rule framework that provides mathematical guarantees for system reliability while maintaining flexibility. Unlike traditional rule-based systems, our logic rules are mathematical constraints that guide LLM reasoning rather than replacing it. We formalize the MultiVis task spanning four scenarios from basic generation to iterative refinement, and develop MultiVis-Bench, a benchmark with over 1,000 cases for multi-modal visualization evaluation. Extensive experiments demonstrate that our approach achieves 75.63% visualization score on challenging tasks, significantly outperforming baselines (57.54-62.79%), with task completion rates of 99.58% and code execution success rates of 94.56% (vs. 74.48% and 65.10% without logic rules), successfully addressing both complexity and reliability challenges in automated visualization generation.
MedInsightBench: Evaluating Medical Analytics Agents Through Multi-Step Insight Discovery in Multimodal Medical Data
Dec 15, 2025In medical data analysis, extracting deep insights from complex, multi-modal datasets is essential for improving patient care, increasing diagnostic accuracy, and optimizing healthcare operations. However, there is currently a lack of high-quality datasets specifically designed to evaluate the ability of large multi-modal models (LMMs) to discover medical insights. In this paper, we introduce MedInsightBench, the first benchmark that comprises 332 carefully curated medical cases, each annotated with thoughtfully designed insights. This benchmark is intended to evaluate the ability of LMMs and agent frameworks to analyze multi-modal medical image data, including posing relevant questions, interpreting complex findings, and synthesizing actionable insights and recommendations. Our analysis indicates that existing LMMs exhibit limited performance on MedInsightBench, which is primarily attributed to their challenges in extracting multi-step, deep insights and the absence of medical expertise. Therefore, we propose MedInsightAgent, an automated agent framework for medical data analysis, composed of three modules: Visual Root Finder, Analytical Insight Agent, and Follow-up Question Composer. Experiments on MedInsightBench highlight pervasive challenges and demonstrate that MedInsightAgent can improve the performance of general LMMs in medical data insight discovery.
DataSage: Multi-agent Collaboration for Insight Discovery with External Knowledge Retrieval, Multi-role Debating, and Multi-path Reasoning
Nov 18, 2025In today's data-driven era, fully automated end-to-end data analytics, particularly insight discovery, is critical for discovering actionable insights that assist organizations in making effective decisions. With the rapid advancement of large language models (LLMs), LLM-driven agents have emerged as a promising paradigm for automating data analysis and insight discovery. However, existing data insight agents remain limited in several key aspects, often failing to deliver satisfactory results due to: (1) insufficient utilization of domain knowledge, (2) shallow analytical depth, and (3) error-prone code generation during insight generation. To address these issues, we propose DataSage, a novel multi-agent framework that incorporates three innovative features including external knowledge retrieval to enrich the analytical context, a multi-role debating mechanism to simulate diverse analytical perspectives and deepen analytical depth, and multi-path reasoning to improve the accuracy of the generated code and insights. Extensive experiments on InsightBench demonstrate that DataSage consistently outperforms existing data insight agents across all difficulty levels, offering an effective solution for automated data insight discovery.
Beyond SELECT: A Comprehensive Taxonomy-Guided Benchmark for Real-World Text-to-SQL Translation
Nov 17, 2025Text-to-SQL datasets are essential for training and evaluating text-to-SQL models, but existing datasets often suffer from limited coverage and fail to capture the diversity of real-world applications. To address this, we propose a novel taxonomy for text-to-SQL classification based on dimensions including core intents, statement types, syntax structures, and key actions. Using this taxonomy, we evaluate widely used public text-to-SQL datasets (e.g., Spider and Bird) and reveal limitations in their coverage and diversity. We then introduce a taxonomy-guided dataset synthesis pipeline, yielding a new dataset named SQL-Synth. This approach combines the taxonomy with Large Language Models (LLMs) to ensure the dataset reflects the breadth and complexity of real-world text-to-SQL applications. Extensive analysis and experimental results validate the effectiveness of our taxonomy, as SQL-Synth exhibits greater diversity and coverage compared to existing benchmarks. Moreover, we uncover that existing LLMs typically fall short in adequately capturing the full range of scenarios, resulting in limited performance on SQL-Synth. However, fine-tuning can substantially improve their performance in these scenarios. The proposed taxonomy has significant potential impact, as it not only enables comprehensive analysis of datasets and the performance of different LLMs, but also guides the construction of training data for LLMs.
Graph-Reward-SQL: Execution-Free Reinforcement Learning for Text-to-SQL via Graph Matching and Stepwise Reward
May 18, 2025Reinforcement learning (RL) has been widely adopted to enhance the performance of large language models (LLMs) on Text-to-SQL tasks. However, existing methods often rely on execution-based or LLM-based Bradley-Terry reward models. The former suffers from high execution latency caused by repeated database calls, whereas the latter imposes substantial GPU memory overhead, both of which significantly hinder the efficiency and scalability of RL pipelines. To this end, we propose a novel Text-to-SQL RL fine-tuning framework named Graph-Reward-SQL, which employs the GMNScore outcome reward model. We leverage SQL graph representations to provide accurate reward signals while significantly reducing inference time and GPU memory usage. Building on this foundation, we further introduce StepRTM, a stepwise reward model that provides intermediate supervision over Common Table Expression (CTE) subqueries. This encourages both functional correctness and structural clarity of SQL. Extensive comparative and ablation experiments on standard benchmarks, including Spider and BIRD, demonstrate that our method consistently outperforms existing reward models.
Text-to-TrajVis: Enabling Trajectory Data Visualizations from Natural Language Questions
Apr 23, 2025This paper introduces the Text-to-TrajVis task, which aims to transform natural language questions into trajectory data visualizations, facilitating the development of natural language interfaces for trajectory visualization systems. As this is a novel task, there is currently no relevant dataset available in the community. To address this gap, we first devised a new visualization language called Trajectory Visualization Language (TVL) to facilitate querying trajectory data and generating visualizations. Building on this foundation, we further proposed a dataset construction method that integrates Large Language Models (LLMs) with human efforts to create high-quality data. Specifically, we first generate TVLs using a comprehensive and systematic process, and then label each TVL with corresponding natural language questions using LLMs. This process results in the creation of the first large-scale Text-to-TrajVis dataset, named TrajVL, which contains 18,140 (question, TVL) pairs. Based on this dataset, we systematically evaluated the performance of multiple LLMs (GPT, Qwen, Llama, etc.) on this task. The experimental results demonstrate that this task is both feasible and highly challenging and merits further exploration within the research community.
PPC-GPT: Federated Task-Specific Compression of Large Language Models via Pruning and Chain-of-Thought Distillation
Feb 21, 2025



Compressing Large Language Models (LLMs) into task-specific Small Language Models (SLMs) encounters two significant challenges: safeguarding domain-specific knowledge privacy and managing limited resources. To tackle these challenges, we propose PPC-GPT, a innovative privacy-preserving federated framework specifically designed for compressing LLMs into task-specific SLMs via pruning and Chain-of-Thought (COT) distillation. PPC-GPT works on a server-client federated architecture, where the client sends differentially private (DP) perturbed task-specific data to the server's LLM. The LLM then generates synthetic data along with their corresponding rationales. This synthetic data is subsequently used for both LLM pruning and retraining processes. Additionally, we harness COT knowledge distillation, leveraging the synthetic data to further improve the retraining of structurally-pruned SLMs. Our experimental results demonstrate the effectiveness of PPC-GPT across various text generation tasks. By compressing LLMs into task-specific SLMs, PPC-GPT not only achieves competitive performance but also prioritizes data privacy protection.
Dial-In LLM: Human-Aligned Dialogue Intent Clustering with LLM-in-the-loop
Dec 12, 2024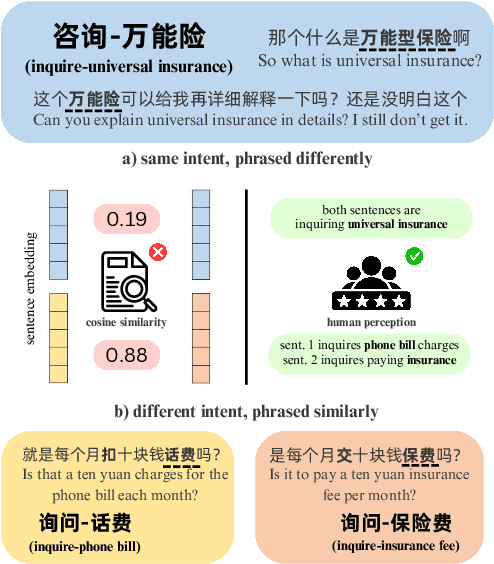
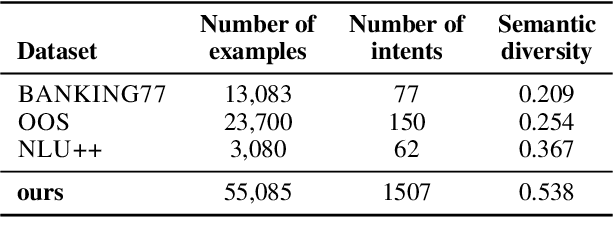
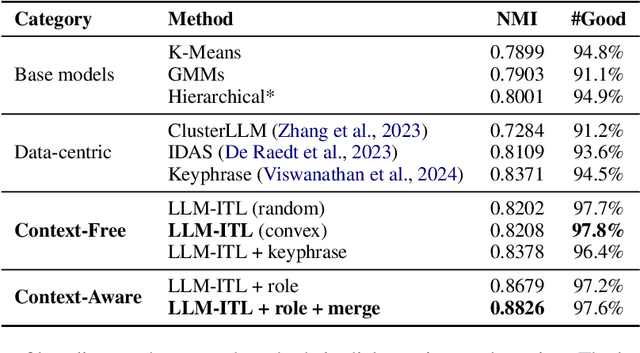
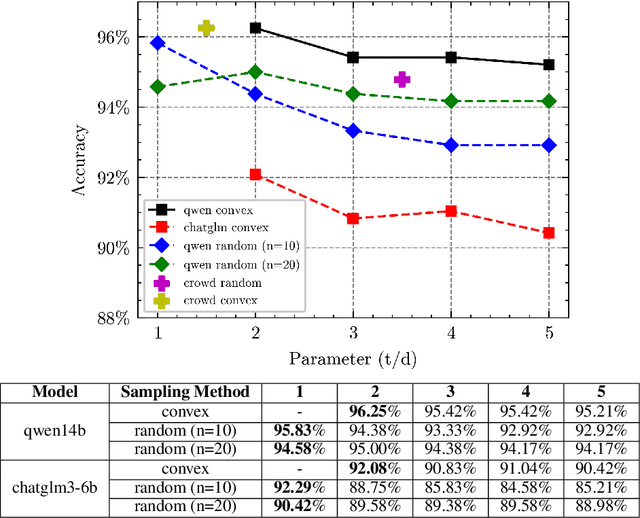
The discovery of customer intention from dialogue plays an important role in automated support system. However, traditional text clustering methods are poorly aligned with human perceptions due to the shift from embedding distance to semantic distance, and existing quantitative metrics for text clustering may not accurately reflect the true quality of intent clusters. In this paper, we leverage the superior language understanding capabilities of Large Language Models (LLMs) for designing better-calibrated intent clustering algorithms. We first establish the foundation by verifying the robustness of fine-tuned LLM utility in semantic coherence evaluation and cluster naming, resulting in an accuracy of 97.50% and 94.40%, respectively, when compared to the human-labeled ground truth. Then, we propose an iterative clustering algorithm that facilitates cluster-level refinement and the continuous discovery of high-quality intent clusters. Furthermore, we present several LLM-in-the-loop semi-supervised clustering techniques tailored for intent discovery from customer service dialogue. Experiments on a large-scale industrial dataset comprising 1,507 intent clusters demonstrate the effectiveness of the proposed techniques. The methods outperformed existing counterparts, achieving 6.25% improvement in quantitative metrics and 12% enhancement in application-level performance when constructing an intent classifier.
ASR-EC Benchmark: Evaluating Large Language Models on Chinese ASR Error Correction
Dec 04, 2024Automatic speech Recognition (ASR) is a fundamental and important task in the field of speech and natural language processing. It is an inherent building block in many applications such as voice assistant, speech translation, etc. Despite the advancement of ASR technologies in recent years, it is still inevitable for modern ASR systems to have a substantial number of erroneous recognition due to environmental noise, ambiguity, etc. Therefore, the error correction in ASR is crucial. Motivated by this, this paper studies ASR error correction in the Chinese language, which is one of the most popular languages and enjoys a large number of users in the world. We first create a benchmark dataset named \emph{ASR-EC} that contains a wide spectrum of ASR errors generated by industry-grade ASR systems. To the best of our knowledge, it is the first Chinese ASR error correction benchmark. Then, inspired by the recent advances in \emph{large language models (LLMs)}, we investigate how to harness the power of LLMs to correct ASR errors. We apply LLMs to ASR error correction in three paradigms. The first paradigm is prompting, which is further categorized as zero-shot, few-shot, and multi-step. The second paradigm is finetuning, which finetunes LLMs with ASR error correction data. The third paradigm is multi-modal augmentation, which collectively utilizes the audio and ASR transcripts for error correction. Extensive experiments reveal that prompting is not effective for ASR error correction. Finetuning is effective only for a portion of LLMs. Multi-modal augmentation is the most effective method for error correction and achieves state-of-the-art performance.
Expanding Chatbot Knowledge in Customer Service: Context-Aware Similar Question Generation Using Large Language Models
Oct 16, 2024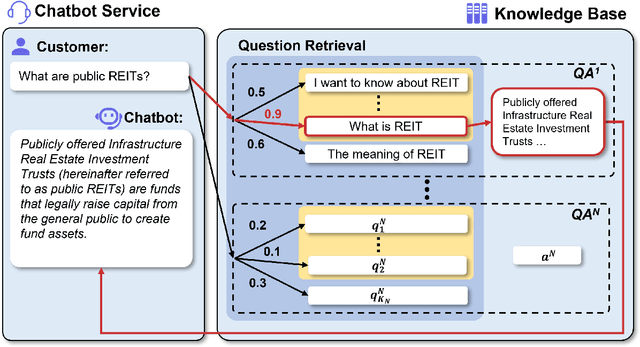

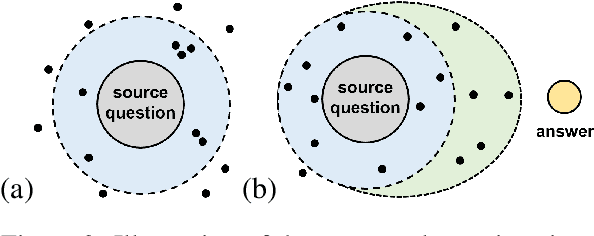
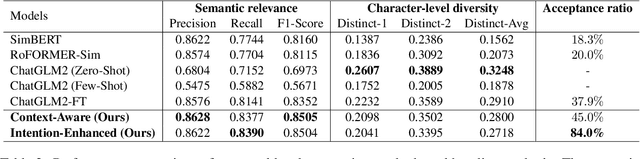
Reliable responses of service chatbots are often achieved by employing retrieval-based methods that restrict answers to a knowledge base comprising predefined question-answer pairs (QA pairs). To accommodate potential variations in how a customer's query may be expressed, it emerges as the favored solution to augment these QA pairs with similar questions that are possibly diverse while remaining semantic consistency. This augmentation task is known as Similar Question Generation (SQG). Traditional methods that heavily rely on human efforts or rule-based techniques suffer from limited diversity or significant semantic deviation from the source question, only capable of producing a finite number of useful questions. To address these limitations, we propose an SQG approach based on Large Language Models (LLMs), capable of producing a substantial number of diverse questions while maintaining semantic consistency to the source QA pair. This is achieved by leveraging LLMs' natural language understanding capability through fine-tuning with specially designed prompts. The experiments conducted on a real customer-service dataset demonstrate that our method surpasses baseline methods by a significant margin in terms of semantic diversity. Human evaluation further confirms that integrating the answer that reflects the customer's intention is crucial for increasing the number of generated questions that meet business requirements.