 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond the Golden Teacher: Enhancing Graph Learning through LLM-GNN Co-teaching
Jun 10, 2026Text-attributed graphs (TAGs) underlie real-world applications such as citation networks, social media, and e-commerce. Few-shot graph learning on TAGs is hard: with only a handful of labels per class and the rest of the graph unannotated, neither GNNs nor LLMs can learn well on their own. GNNs read topology and fail on cold nodes; LLMs read text and fail on text-ambiguous nodes. Existing LLM-GNN methods all follow the same recipe: designate one model as the golden teacher and use its outputs (e.g., features or pseudo-labels) to supervise the other. We argue this golden-teacher assumption breaks under sparse supervision: neither model is golden, and treating either as such transfers its blind spots into the student. We therefore ask: can we avoid designating either model as the golden teacher, and still perform effective graph learning? We answer with LLM-GNN Co-Teaching, a bidirectional co-teaching framework in which neither model is fixed as teacher. The GNN and LLM exchange their most confident pseudo-labels under an architecture-specific small-loss criterion, and both update every round. Supervision is then mined from the trajectory: whenever a node moves from cross-model contradiction at round t to cross-model agreement at round t+1, the LLM's two answers on the same input form a preference pair (old contradicting self < new peer-endorsed self) for DPO training. We call this Round-based Pseudo-Label Preference Optimization (RPL-PO). On six benchmarks, LLM-GNN Co-Teaching consistently outperforms GNN-as-Judge and all prior methods, with absolute 3-shot gains of 7.86% on Cora and 7.73% on ogbn-arxiv; improvements carry over to 5-shot and to zero-shot cross-dataset transfer. Error-structure analysis further shows that abandoning the golden-teacher assumption substantially improves the LLM's graph learning capability on challenging samples.
GraphInfer-Bench: Benchmarking LLM's Inference Capability on Graphs
Jun 10, 2026Graph analysis underlies many applications whose answers cannot be looked up in a single record or retrieved along a path: laundering rings, drug repurposing, user preference, and scientific theme are all inferred from a node together with its neighbourhood. We introduce GraphInfer-Bench, a benchmark for whether LLMs can perform this graph inference: producing an open-ended answer that no single node supports and no path retrieves. Existing graph-QA protocols cannot test this capability: algorithm simulation, node classification, single-node description, KG-QA, and GraphRAG all admit answers retrievable from one node or along a path. GraphInfer-Bench defines five tasks along Description (what a region is) and Comparison (how regions differ), each constructed so the ground truth lives in no single node. The release contains 42,000 samples across six real-world graphs, produced automatically and screened by a four-layer quality-control protocol. We evaluate four method families against the same tasks: graph-token alignment models, zero-shot frontier closed-source LLMs, Graph2Text supervised fine-tuning, and plain GNNs as a structural reference. No method family closes the gap. Graph-token alignment partially handles description tasks (relational, theme) but collapses on comparison tasks. Frontier LLMs lead on outlier detection and community partition among LLM-based methods but lag on masked-node prediction. Graph2Text SFT is the strongest LLM-based method on the description side yet falls behind frontier LLMs on comparison. Across every task, plain GNNs match or beat the strongest LLM-based row, with the largest margin on community detection. GraphInfer-Bench surfaces graph inference as an open capability gap rather than a property of any one architecture.
Trustworthy Federated Label Distribution Learning under Annotation Quality Disparity
May 06, 2026Label Distribution Learning (LDL) models supervision as an instance-wise probability distribution, enabling fine-grained learning under inherent ambiguity, but its success relies on high-fidelity label distributions that are costly to obtain and thus often noisy. Motivated by privacy-sensitive applications, we study Federated Label Distribution Learning (Fed-LDL), where data isolation further induces heterogeneous annotation quality across clients, making local updates unevenly reliable and breaking sample-size-based aggregation (e.g., FedAvg). To address this trust dilemma, we propose FedQual, a quality-aware Fed-LDL framework with two coupled mechanisms: (i) quality-adaptive client training guided by a global semantic anchor that calibrates low-quality clients while preserving high-quality autonomy, and (ii) reliability-aware server aggregation that reweights client contributions by effective reliable information rather than raw sample size. To enable rigorous evaluation, we construct four new Fed-LDL benchmarks (FER-LDL, FI-LDL, PIPAL-LDL, and KADID-LDL) with controlled annotation quality disparity. We further provide a theoretical guarantee showing that under heterogeneous supervision quality, client-specific calibration is strictly better than any uniform calibration. Extensive experiments on the proposed benchmarks demonstrate the effectiveness of FedQual.
FedIDM: Achieving Fast and Stable Convergence in Byzantine Federated Learning through Iterative Distribution Matching
Apr 16, 2026Most existing Byzantine-robust federated learning (FL) methods suffer from slow and unstable convergence. Moreover, when handling a substantial proportion of colluded malicious clients, achieving robustness typically entails compromising model utility. To address these issues, this work introduces FedIDM, which employs distribution matching to construct trustworthy condensed data for identifying and filtering abnormal clients. FedIDM consists of two main components: (1) attack-tolerant condensed data generation, and (2) robust aggregation with negative contribution-based rejection. These components exclude local updates that (1) deviate from the update direction derived from condensed data, or (2) cause a significant loss on the condensed dataset. Comprehensive evaluations on three benchmark datasets demonstrate that FedIDM achieves fast and stable convergence while maintaining acceptable model utility, under multiple state-of-the-art Byzantine attacks involving a large number of malicious clients.
InkDrop: Invisible Backdoor Attacks Against Dataset Condensation
Mar 30, 2026Dataset Condensation (DC) is a data-efficient learning paradigm that synthesizes small yet informative datasets, enabling models to match the performance of full-data training. However, recent work exposes a critical vulnerability of DC to backdoor attacks, where malicious patterns (\textit{e.g.}, triggers) are implanted into the condensation dataset, inducing targeted misclassification on specific inputs. Existing attacks always prioritize attack effectiveness and model utility, overlooking the crucial dimension of stealthiness. To bridge this gap, we propose InkDrop, which enhances the imperceptibility of malicious manipulation without degrading attack effectiveness and model utility. InkDrop leverages the inherent uncertainty near model decision boundaries, where minor input perturbations can induce semantic shifts, to construct a stealthy and effective backdoor attack. Specifically, InkDrop first selects candidate samples near the target decision boundary that exhibit latent semantic affinity to the target class. It then learns instance-dependent perturbations constrained by perceptual and spatial consistency, embedding targeted malicious behavior into the condensed dataset. Extensive experiments across diverse datasets validate the overall effectiveness of InkDrop, demonstrating its ability to integrate adversarial intent into condensed datasets while preserving model utility and minimizing detectability. Our code is available at https://github.com/lvdongyi/InkDrop.
Federated Heterogeneous Language Model Optimization for Hybrid Automatic Speech Recognition
Mar 05, 2026Training automatic speech recognition (ASR) models increasingly relies on decentralized federated learning to ensure data privacy and accessibility, producing multiple local models that require effective merging. In hybrid ASR systems, while acoustic models can be merged using established methods, the language model (LM) for rescoring the N-best speech recognition list faces challenges due to the heterogeneity of non-neural n-gram models and neural network models. This paper proposes a heterogeneous LM optimization task and introduces a match-and-merge paradigm with two algorithms: the Genetic Match-and-Merge Algorithm (GMMA), using genetic operations to evolve and pair LMs, and the Reinforced Match-and-Merge Algorithm (RMMA), leveraging reinforcement learning for efficient convergence. Experiments on seven OpenSLR datasets show RMMA achieves the lowest average Character Error Rate and better generalization than baselines, converging up to seven times faster than GMMA, highlighting the paradigm's potential for scalable, privacy-preserving ASR systems.
Orchestration-Free Customer Service Automation: A Privacy-Preserving and Flowchart-Guided Framework
Feb 17, 2026Customer service automation has seen growing demand within digital transformation. Existing approaches either rely on modular system designs with extensive agent orchestration or employ over-simplified instruction schemas, providing limited guidance and poor generalizability. This paper introduces an orchestration-free framework using Task-Oriented Flowcharts (TOFs) to enable end-to-end automation without manual intervention. We first define the components and evaluation metrics for TOFs, then formalize a cost-efficient flowchart construction algorithm to abstract procedural knowledge from service dialogues. We emphasize local deployment of small language models and propose decentralized distillation with flowcharts to mitigate data scarcity and privacy issues in model training. Extensive experiments validate the effectiveness in various service tasks, with superior quantitative and application performance compared to strong baselines and market products. By releasing a web-based system demonstration with case studies, we aim to promote streamlined creation of future service automation.
FedGRPO: Privately Optimizing Foundation Models with Group-Relative Rewards from Domain Client
Feb 12, 2026One important direction of Federated Foundation Models (FedFMs) is leveraging data from small client models to enhance the performance of a large server-side foundation model. Existing methods based on model level or representation level knowledge transfer either require expensive local training or incur high communication costs and introduce unavoidable privacy risks. We reformulate this problem as a reinforcement learning style evaluation process and propose FedGRPO, a privacy preserving framework comprising two modules. The first module performs competence-based expert selection by building a lightweight confidence graph from auxiliary data to identify the most suitable clients for each question. The second module leverages the "Group Relative" concept from the Group Relative Policy Optimization (GRPO) framework by packaging each question together with its solution rationale into candidate policies, dispatching these policies to a selected subset of expert clients, and aggregating solely the resulting scalar reward signals via a federated group-relative loss function. By exchanging reward values instead of data or model updates, FedGRPO reduces privacy risk and communication overhead while enabling parallel evaluation across heterogeneous devices. Empirical results on diverse domain tasks demonstrate that FedGRPO achieves superior downstream accuracy and communication efficiency compared to conventional FedFMs baselines.
Order-Level Attention Similarity Across Language Models: A Latent Commonality
Nov 07, 2025


In this paper, we explore an important yet previously neglected question: Do context aggregation patterns across Language Models (LMs) share commonalities? While some works have investigated context aggregation or attention weights in LMs, they typically focus on individual models or attention heads, lacking a systematic analysis across multiple LMs to explore their commonalities. In contrast, we focus on the commonalities among LMs, which can deepen our understanding of LMs and even facilitate cross-model knowledge transfer. In this work, we introduce the Order-Level Attention (OLA) derived from the order-wise decomposition of Attention Rollout and reveal that the OLA at the same order across LMs exhibits significant similarities. Furthermore, we discover an implicit mapping between OLA and syntactic knowledge. Based on these two findings, we propose the Transferable OLA Adapter (TOA), a training-free cross-LM adapter transfer method. Specifically, we treat the OLA as a unified syntactic feature representation and train an adapter that takes OLA as input. Due to the similarities in OLA across LMs, the adapter generalizes to unseen LMs without requiring any parameter updates. Extensive experiments demonstrate that TOA's cross-LM generalization effectively enhances the performance of unseen LMs. Code is available at https://github.com/jinglin-liang/OLAS.
ErrorEraser: Unlearning Data Bias for Improved Continual Learning
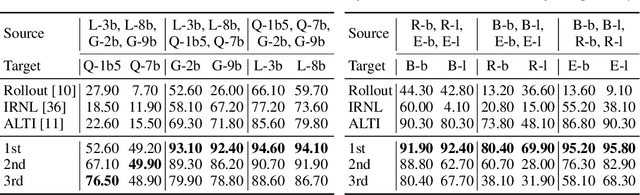
Jun 11, 2025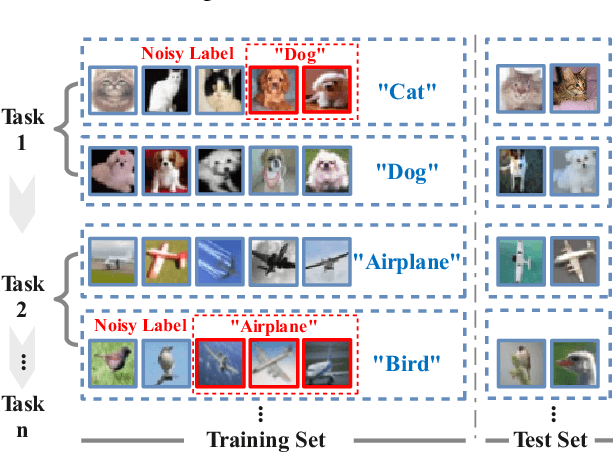
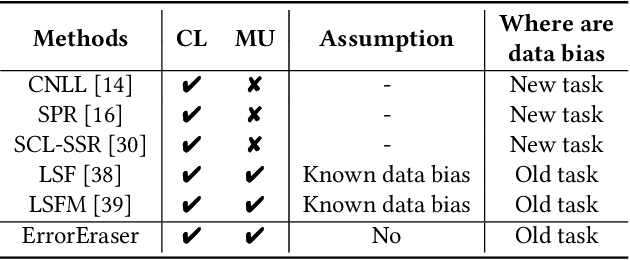
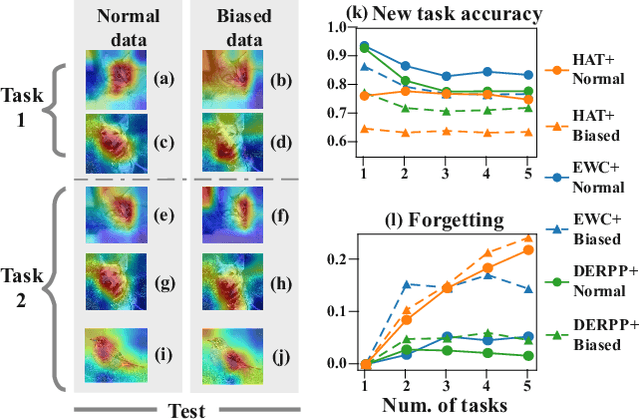
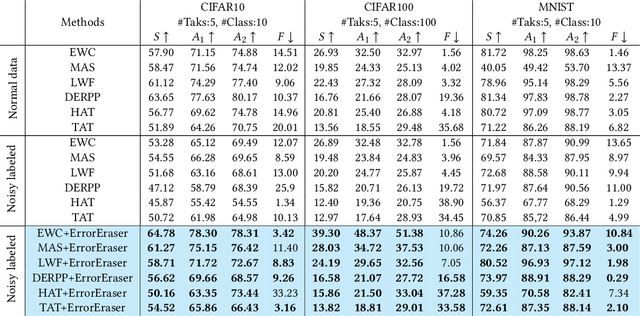
Continual Learning (CL) primarily aims to retain knowledge to prevent catastrophic forgetting and transfer knowledge to facilitate learning new tasks. Unlike traditional methods, we propose a novel perspective: CL not only needs to prevent forgetting, but also requires intentional forgetting.This arises from existing CL methods ignoring biases in real-world data, leading the model to learn spurious correlations that transfer and amplify across tasks. From feature extraction and prediction results, we find that data biases simultaneously reduce CL's ability to retain and transfer knowledge. To address this, we propose ErrorEraser, a universal plugin that removes erroneous memories caused by biases in CL, enhancing performance in both new and old tasks. ErrorEraser consists of two modules: Error Identification and Error Erasure. The former learns the probability density distribution of task data in the feature space without prior knowledge, enabling accurate identification of potentially biased samples. The latter ensures only erroneous knowledge is erased by shifting the decision space of representative outlier samples. Additionally, an incremental feature distribution learning strategy is designed to reduce the resource overhead during error identification in downstream tasks. Extensive experimental results show that ErrorEraser significantly mitigates the negative impact of data biases, achieving higher accuracy and lower forgetting rates across three types of CL methods. The code is available at https://github.com/diadai/ErrorEraser.