 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrder-Level Attention Similarity Across Language Models: A Latent Commonality
Nov 07, 2025
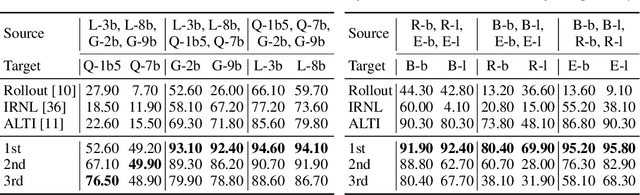


In this paper, we explore an important yet previously neglected question: Do context aggregation patterns across Language Models (LMs) share commonalities? While some works have investigated context aggregation or attention weights in LMs, they typically focus on individual models or attention heads, lacking a systematic analysis across multiple LMs to explore their commonalities. In contrast, we focus on the commonalities among LMs, which can deepen our understanding of LMs and even facilitate cross-model knowledge transfer. In this work, we introduce the Order-Level Attention (OLA) derived from the order-wise decomposition of Attention Rollout and reveal that the OLA at the same order across LMs exhibits significant similarities. Furthermore, we discover an implicit mapping between OLA and syntactic knowledge. Based on these two findings, we propose the Transferable OLA Adapter (TOA), a training-free cross-LM adapter transfer method. Specifically, we treat the OLA as a unified syntactic feature representation and train an adapter that takes OLA as input. Due to the similarities in OLA across LMs, the adapter generalizes to unseen LMs without requiring any parameter updates. Extensive experiments demonstrate that TOA's cross-LM generalization effectively enhances the performance of unseen LMs. Code is available at https://github.com/jinglin-liang/OLAS.
ReplayCAD: Generative Diffusion Replay for Continual Anomaly Detection
May 10, 2025



Continual Anomaly Detection (CAD) enables anomaly detection models in learning new classes while preserving knowledge of historical classes. CAD faces two key challenges: catastrophic forgetting and segmentation of small anomalous regions. Existing CAD methods store image distributions or patch features to mitigate catastrophic forgetting, but they fail to preserve pixel-level detailed features for accurate segmentation. To overcome this limitation, we propose ReplayCAD, a novel diffusion-driven generative replay framework that replay high-quality historical data, thus effectively preserving pixel-level detailed features. Specifically, we compress historical data by searching for a class semantic embedding in the conditional space of the pre-trained diffusion model, which can guide the model to replay data with fine-grained pixel details, thus improving the segmentation performance. However, relying solely on semantic features results in limited spatial diversity. Hence, we further use spatial features to guide data compression, achieving precise control of sample space, thereby generating more diverse data. Our method achieves state-of-the-art performance in both classification and segmentation, with notable improvements in segmentation: 11.5% on VisA and 8.1% on MVTec. Our source code is available at https://github.com/HULEI7/ReplayCAD.
Monocular and Generalizable Gaussian Talking Head Animation
Apr 01, 2025



In this work, we introduce Monocular and Generalizable Gaussian Talking Head Animation (MGGTalk), which requires monocular datasets and generalizes to unseen identities without personalized re-training. Compared with previous 3D Gaussian Splatting (3DGS) methods that requires elusive multi-view datasets or tedious personalized learning/inference, MGGtalk enables more practical and broader applications. However, in the absence of multi-view and personalized training data, the incompleteness of geometric and appearance information poses a significant challenge. To address these challenges, MGGTalk explores depth information to enhance geometric and facial symmetry characteristics to supplement both geometric and appearance features. Initially, based on the pixel-wise geometric information obtained from depth estimation, we incorporate symmetry operations and point cloud filtering techniques to ensure a complete and precise position parameter for 3DGS. Subsequently, we adopt a two-stage strategy with symmetric priors for predicting the remaining 3DGS parameters. We begin by predicting Gaussian parameters for the visible facial regions of the source image. These parameters are subsequently utilized to improve the prediction of Gaussian parameters for the non-visible regions. Extensive experiments demonstrate that MGGTalk surpasses previous state-of-the-art methods, achieving superior performance across various metrics.
MPDrive: Improving Spatial Understanding with Marker-Based Prompt Learning for Autonomous Driving
Apr 01, 2025



Autonomous driving visual question answering (AD-VQA) aims to answer questions related to perception, prediction, and planning based on given driving scene images, heavily relying on the model's spatial understanding capabilities. Prior works typically express spatial information through textual representations of coordinates, resulting in semantic gaps between visual coordinate representations and textual descriptions. This oversight hinders the accurate transmission of spatial information and increases the expressive burden. To address this, we propose a novel Marker-based Prompt learning framework (MPDrive), which represents spatial coordinates by concise visual markers, ensuring linguistic expressive consistency and enhancing the accuracy of both visual perception and spatial expression in AD-VQA. Specifically, we create marker images by employing a detection expert to overlay object regions with numerical labels, converting complex textual coordinate generation into straightforward text-based visual marker predictions. Moreover, we fuse original and marker images as scene-level features and integrate them with detection priors to derive instance-level features. By combining these features, we construct dual-granularity visual prompts that stimulate the LLM's spatial perception capabilities. Extensive experiments on the DriveLM and CODA-LM datasets show that MPDrive achieves state-of-the-art performance, particularly in cases requiring sophisticated spatial understanding.
SEG-SAM: Semantic-Guided SAM for Unified Medical Image Segmentation
Dec 17, 2024



Recently, developing unified medical image segmentation models gains increasing attention, especially with the advent of the Segment Anything Model (SAM). SAM has shown promising binary segmentation performance in natural domains, however, transferring it to the medical domain remains challenging, as medical images often possess substantial inter-category overlaps. To address this, we propose the SEmantic-Guided SAM (SEG-SAM), a unified medical segmentation model that incorporates semantic medical knowledge to enhance medical segmentation performance. First, to avoid the potential conflict between binary and semantic predictions, we introduce a semantic-aware decoder independent of SAM's original decoder, specialized for both semantic segmentation on the prompted object and classification on unprompted objects in images. To further enhance the model's semantic understanding, we solicit key characteristics of medical categories from large language models and incorporate them into SEG-SAM through a text-to-vision semantic module, adaptively transferring the language information into the visual segmentation task. In the end, we introduce the cross-mask spatial alignment strategy to encourage greater overlap between the predicted masks from SEG-SAM's two decoders, thereby benefiting both predictions. Extensive experiments demonstrate that SEG-SAM outperforms state-of-the-art SAM-based methods in unified binary medical segmentation and task-specific methods in semantic medical segmentation, showcasing promising results and potential for broader medical applications.
Globally Correlation-Aware Hard Negative Generation
Nov 20, 2024Hard negative generation aims to generate informative negative samples that help to determine the decision boundaries and thus facilitate advancing deep metric learning. Current works select pair/triplet samples, learn their correlations, and fuse them to generate hard negatives. However, these works merely consider the local correlations of selected samples, ignoring global sample correlations that would provide more significant information to generate more informative negatives. In this work, we propose a Globally Correlation-Aware Hard Negative Generation (GCA-HNG) framework, which first learns sample correlations from a global perspective and exploits these correlations to guide generating hardness-adaptive and diverse negatives. Specifically, this approach begins by constructing a structured graph to model sample correlations, where each node represents a specific sample and each edge represents the correlations between corresponding samples. Then, we introduce an iterative graph message propagation to propagate the messages of node and edge through the whole graph and thus learn the sample correlations globally. Finally, with the guidance of the learned global correlations, we propose a channel-adaptive manner to combine an anchor and multiple negatives for HNG. Compared to current methods, GCA-HNG allows perceiving sample correlations with numerous negatives from a global and comprehensive perspective and generates the negatives with better hardness and diversity. Extensive experiment results demonstrate that the proposed GCA-HNG is superior to related methods on four image retrieval benchmark datasets. Codes and trained models are available at \url{https://github.com/PWenJay/GCA-HNG}.
One-Shot Diffusion Mimicker for Handwritten Text Generation
Sep 11, 2024Existing handwritten text generation methods often require more than ten handwriting samples as style references. However, in practical applications, users tend to prefer a handwriting generation model that operates with just a single reference sample for its convenience and efficiency. This approach, known as "one-shot generation", significantly simplifies the process but poses a significant challenge due to the difficulty of accurately capturing a writer's style from a single sample, especially when extracting fine details from the characters' edges amidst sparse foreground and undesired background noise. To address this problem, we propose a One-shot Diffusion Mimicker (One-DM) to generate handwritten text that can mimic any calligraphic style with only one reference sample. Inspired by the fact that high-frequency information of the individual sample often contains distinct style patterns (e.g., character slant and letter joining), we develop a novel style-enhanced module to improve the style extraction by incorporating high-frequency components from a single sample. We then fuse the style features with the text content as a merged condition for guiding the diffusion model to produce high-quality handwritten text images. Extensive experiments demonstrate that our method can successfully generate handwriting scripts with just one sample reference in multiple languages, even outperforming previous methods using over ten samples. Our source code is available at https://github.com/dailenson/One-DM.
Diffusion-Driven Data Replay: A Novel Approach to Combat Forgetting in Federated Class Continual Learning
Sep 04, 2024Federated Class Continual Learning (FCCL) merges the challenges of distributed client learning with the need for seamless adaptation to new classes without forgetting old ones. The key challenge in FCCL is catastrophic forgetting, an issue that has been explored to some extent in Continual Learning (CL). However, due to privacy preservation requirements, some conventional methods, such as experience replay, are not directly applicable to FCCL. Existing FCCL methods mitigate forgetting by generating historical data through federated training of GANs or data-free knowledge distillation. However, these approaches often suffer from unstable training of generators or low-quality generated data, limiting their guidance for the model. To address this challenge, we propose a novel method of data replay based on diffusion models. Instead of training a diffusion model, we employ a pre-trained conditional diffusion model to reverse-engineer each class, searching the corresponding input conditions for each class within the model's input space, significantly reducing computational resources and time consumption while ensuring effective generation. Furthermore, we enhance the classifier's domain generalization ability on generated and real data through contrastive learning, indirectly improving the representational capability of generated data for real data. Comprehensive experiments demonstrate that our method significantly outperforms existing baselines. Code is available at https://github.com/jinglin-liang/DDDR.
KMTalk: Speech-Driven 3D Facial Animation with Key Motion Embedding
Sep 02, 2024We present a novel approach for synthesizing 3D facial motions from audio sequences using key motion embeddings. Despite recent advancements in data-driven techniques, accurately mapping between audio signals and 3D facial meshes remains challenging. Direct regression of the entire sequence often leads to over-smoothed results due to the ill-posed nature of the problem. To this end, we propose a progressive learning mechanism that generates 3D facial animations by introducing key motion capture to decrease cross-modal mapping uncertainty and learning complexity. Concretely, our method integrates linguistic and data-driven priors through two modules: the linguistic-based key motion acquisition and the cross-modal motion completion. The former identifies key motions and learns the associated 3D facial expressions, ensuring accurate lip-speech synchronization. The latter extends key motions into a full sequence of 3D talking faces guided by audio features, improving temporal coherence and audio-visual consistency. Extensive experimental comparisons against existing state-of-the-art methods demonstrate the superiority of our approach in generating more vivid and consistent talking face animations. Consistent enhancements in results through the integration of our proposed learning scheme with existing methods underscore the efficacy of our approach. Our code and weights will be at the project website: \url{https://github.com/ffxzh/KMTalk}.
Perception and Semantic Aware Regularization for Sequential Confidence Calibration
May 31, 2023Deep sequence recognition (DSR) models receive increasing attention due to their superior application to various applications. Most DSR models use merely the target sequences as supervision without considering other related sequences, leading to over-confidence in their predictions. The DSR models trained with label smoothing regularize labels by equally and independently smoothing each token, reallocating a small value to other tokens for mitigating overconfidence. However, they do not consider tokens/sequences correlations that may provide more effective information to regularize training and thus lead to sub-optimal performance. In this work, we find tokens/sequences with high perception and semantic correlations with the target ones contain more correlated and effective information and thus facilitate more effective regularization. To this end, we propose a Perception and Semantic aware Sequence Regularization framework, which explore perceptively and semantically correlated tokens/sequences as regularization. Specifically, we introduce a semantic context-free recognition and a language model to acquire similar sequences with high perceptive similarities and semantic correlation, respectively. Moreover, over-confidence degree varies across samples according to their difficulties. Thus, we further design an adaptive calibration intensity module to compute a difficulty score for each samples to obtain finer-grained regularization. Extensive experiments on canonical sequence recognition tasks, including scene text and speech recognition, demonstrate that our method sets novel state-of-the-art results. Code is available at https://github.com/husterpzh/PSSR.