 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond the Golden Teacher: Enhancing Graph Learning through LLM-GNN Co-teaching
Jun 10, 2026Text-attributed graphs (TAGs) underlie real-world applications such as citation networks, social media, and e-commerce. Few-shot graph learning on TAGs is hard: with only a handful of labels per class and the rest of the graph unannotated, neither GNNs nor LLMs can learn well on their own. GNNs read topology and fail on cold nodes; LLMs read text and fail on text-ambiguous nodes. Existing LLM-GNN methods all follow the same recipe: designate one model as the golden teacher and use its outputs (e.g., features or pseudo-labels) to supervise the other. We argue this golden-teacher assumption breaks under sparse supervision: neither model is golden, and treating either as such transfers its blind spots into the student. We therefore ask: can we avoid designating either model as the golden teacher, and still perform effective graph learning? We answer with LLM-GNN Co-Teaching, a bidirectional co-teaching framework in which neither model is fixed as teacher. The GNN and LLM exchange their most confident pseudo-labels under an architecture-specific small-loss criterion, and both update every round. Supervision is then mined from the trajectory: whenever a node moves from cross-model contradiction at round t to cross-model agreement at round t+1, the LLM's two answers on the same input form a preference pair (old contradicting self < new peer-endorsed self) for DPO training. We call this Round-based Pseudo-Label Preference Optimization (RPL-PO). On six benchmarks, LLM-GNN Co-Teaching consistently outperforms GNN-as-Judge and all prior methods, with absolute 3-shot gains of 7.86% on Cora and 7.73% on ogbn-arxiv; improvements carry over to 5-shot and to zero-shot cross-dataset transfer. Error-structure analysis further shows that abandoning the golden-teacher assumption substantially improves the LLM's graph learning capability on challenging samples.
GraphInfer-Bench: Benchmarking LLM's Inference Capability on Graphs
Jun 10, 2026Graph analysis underlies many applications whose answers cannot be looked up in a single record or retrieved along a path: laundering rings, drug repurposing, user preference, and scientific theme are all inferred from a node together with its neighbourhood. We introduce GraphInfer-Bench, a benchmark for whether LLMs can perform this graph inference: producing an open-ended answer that no single node supports and no path retrieves. Existing graph-QA protocols cannot test this capability: algorithm simulation, node classification, single-node description, KG-QA, and GraphRAG all admit answers retrievable from one node or along a path. GraphInfer-Bench defines five tasks along Description (what a region is) and Comparison (how regions differ), each constructed so the ground truth lives in no single node. The release contains 42,000 samples across six real-world graphs, produced automatically and screened by a four-layer quality-control protocol. We evaluate four method families against the same tasks: graph-token alignment models, zero-shot frontier closed-source LLMs, Graph2Text supervised fine-tuning, and plain GNNs as a structural reference. No method family closes the gap. Graph-token alignment partially handles description tasks (relational, theme) but collapses on comparison tasks. Frontier LLMs lead on outlier detection and community partition among LLM-based methods but lag on masked-node prediction. Graph2Text SFT is the strongest LLM-based method on the description side yet falls behind frontier LLMs on comparison. Across every task, plain GNNs match or beat the strongest LLM-based row, with the largest margin on community detection. GraphInfer-Bench surfaces graph inference as an open capability gap rather than a property of any one architecture.
FedProxy: Federated Fine-Tuning of LLMs via Proxy SLMs and Heterogeneity-Aware Fusion
Apr 21, 2026Federated fine-tuning of Large Language Models (LLMs) is obstructed by a trilemma of challenges: protecting LLMs intellectual property (IP), ensuring client privacy, and mitigating performance loss on heterogeneous data. Existing methods like Offsite-Tuning (OT) secure the LLMs IP by having clients train only lightweight adapters, yet our analysis reveals they suffer from a fundamental performance bottleneck, leaving a significant gap compared to centralized training. To bridge this gap, we introduce FedProxy, a new federated adaptation framework. FedProxy replaces weak adapters with a unified, powerful Proxy Small Language Model (SLM), compressed from the proprietary LLM, to serve as a high-fidelity surrogate for collaborative fine-tuning. Our framework systematically resolves the trilemma through a three-stage architecture: (i) Efficient Representation via server-guided compression to create a resource-friendly proxy; (ii) Robust Optimization through an interference-mitigating aggregation strategy to handle data heterogeneity; and (iii) Effortless Fusion via a training-free "plug-in" mechanism to integrate learned knowledge back into the LLM. Experiments show FedProxy significantly outperforms OT methods and approaches centralized performance, establishing a new benchmark for secure and high-performance federated LLM adaptation.
FedGRPO: Privately Optimizing Foundation Models with Group-Relative Rewards from Domain Client
Feb 12, 2026One important direction of Federated Foundation Models (FedFMs) is leveraging data from small client models to enhance the performance of a large server-side foundation model. Existing methods based on model level or representation level knowledge transfer either require expensive local training or incur high communication costs and introduce unavoidable privacy risks. We reformulate this problem as a reinforcement learning style evaluation process and propose FedGRPO, a privacy preserving framework comprising two modules. The first module performs competence-based expert selection by building a lightweight confidence graph from auxiliary data to identify the most suitable clients for each question. The second module leverages the "Group Relative" concept from the Group Relative Policy Optimization (GRPO) framework by packaging each question together with its solution rationale into candidate policies, dispatching these policies to a selected subset of expert clients, and aggregating solely the resulting scalar reward signals via a federated group-relative loss function. By exchanging reward values instead of data or model updates, FedGRPO reduces privacy risk and communication overhead while enabling parallel evaluation across heterogeneous devices. Empirical results on diverse domain tasks demonstrate that FedGRPO achieves superior downstream accuracy and communication efficiency compared to conventional FedFMs baselines.
Order-Level Attention Similarity Across Language Models: A Latent Commonality
Nov 07, 2025
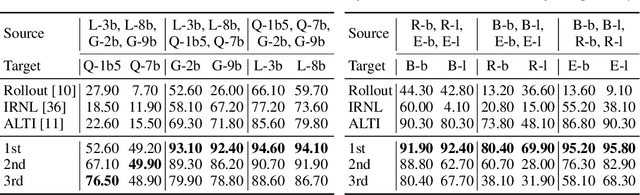


In this paper, we explore an important yet previously neglected question: Do context aggregation patterns across Language Models (LMs) share commonalities? While some works have investigated context aggregation or attention weights in LMs, they typically focus on individual models or attention heads, lacking a systematic analysis across multiple LMs to explore their commonalities. In contrast, we focus on the commonalities among LMs, which can deepen our understanding of LMs and even facilitate cross-model knowledge transfer. In this work, we introduce the Order-Level Attention (OLA) derived from the order-wise decomposition of Attention Rollout and reveal that the OLA at the same order across LMs exhibits significant similarities. Furthermore, we discover an implicit mapping between OLA and syntactic knowledge. Based on these two findings, we propose the Transferable OLA Adapter (TOA), a training-free cross-LM adapter transfer method. Specifically, we treat the OLA as a unified syntactic feature representation and train an adapter that takes OLA as input. Due to the similarities in OLA across LMs, the adapter generalizes to unseen LMs without requiring any parameter updates. Extensive experiments demonstrate that TOA's cross-LM generalization effectively enhances the performance of unseen LMs. Code is available at https://github.com/jinglin-liang/OLAS.
PPC-GPT: Federated Task-Specific Compression of Large Language Models via Pruning and Chain-of-Thought Distillation
Feb 21, 2025



Compressing Large Language Models (LLMs) into task-specific Small Language Models (SLMs) encounters two significant challenges: safeguarding domain-specific knowledge privacy and managing limited resources. To tackle these challenges, we propose PPC-GPT, a innovative privacy-preserving federated framework specifically designed for compressing LLMs into task-specific SLMs via pruning and Chain-of-Thought (COT) distillation. PPC-GPT works on a server-client federated architecture, where the client sends differentially private (DP) perturbed task-specific data to the server's LLM. The LLM then generates synthetic data along with their corresponding rationales. This synthetic data is subsequently used for both LLM pruning and retraining processes. Additionally, we harness COT knowledge distillation, leveraging the synthetic data to further improve the retraining of structurally-pruned SLMs. Our experimental results demonstrate the effectiveness of PPC-GPT across various text generation tasks. By compressing LLMs into task-specific SLMs, PPC-GPT not only achieves competitive performance but also prioritizes data privacy protection.
Vertical Federated Learning in Practice: The Good, the Bad, and the Ugly
Feb 12, 2025Vertical Federated Learning (VFL) is a privacy-preserving collaborative learning paradigm that enables multiple parties with distinct feature sets to jointly train machine learning models without sharing their raw data. Despite its potential to facilitate cross-organizational collaborations, the deployment of VFL systems in real-world applications remains limited. To investigate the gap between existing VFL research and practical deployment, this survey analyzes the real-world data distributions in potential VFL applications and identifies four key findings that highlight this gap. We propose a novel data-oriented taxonomy of VFL algorithms based on real VFL data distributions. Our comprehensive review of existing VFL algorithms reveals that some common practical VFL scenarios have few or no viable solutions. Based on these observations, we outline key research directions aimed at bridging the gap between current VFL research and real-world applications.
Top Ten Challenges Towards Agentic Neural Graph Databases
Jan 24, 2025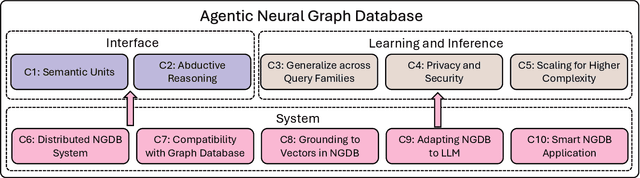
Graph databases (GDBs) like Neo4j and TigerGraph excel at handling interconnected data but lack advanced inference capabilities. Neural Graph Databases (NGDBs) address this by integrating Graph Neural Networks (GNNs) for predictive analysis and reasoning over incomplete or noisy data. However, NGDBs rely on predefined queries and lack autonomy and adaptability. This paper introduces Agentic Neural Graph Databases (Agentic NGDBs), which extend NGDBs with three core functionalities: autonomous query construction, neural query execution, and continuous learning. We identify ten key challenges in realizing Agentic NGDBs: semantic unit representation, abductive reasoning, scalable query execution, and integration with foundation models like large language models (LLMs). By addressing these challenges, Agentic NGDBs can enable intelligent, self-improving systems for modern data-driven applications, paving the way for adaptable and autonomous data management solutions.
Addressing Spatial-Temporal Data Heterogeneity in Federated Continual Learning via Tail Anchor
Dec 24, 2024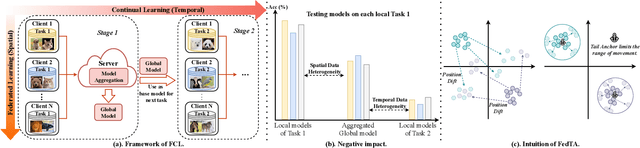
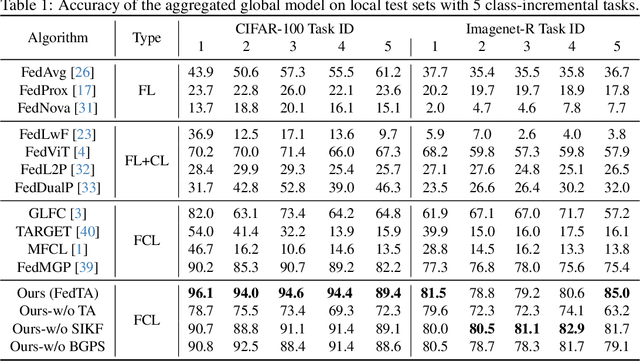
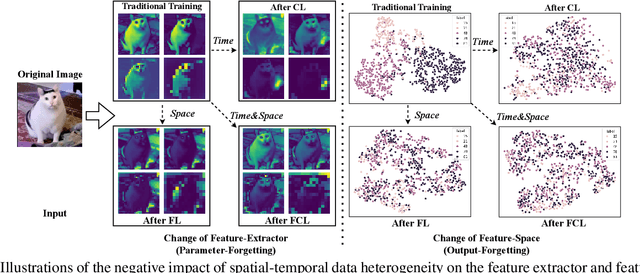
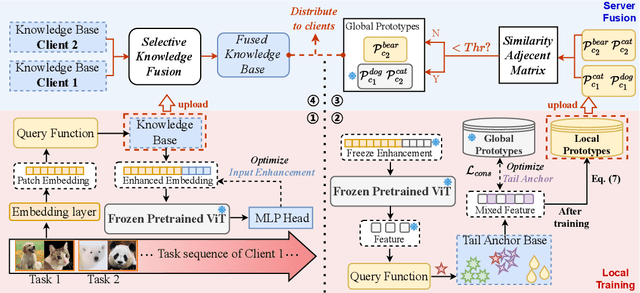
Federated continual learning (FCL) allows each client to continually update its knowledge from task streams, enhancing the applicability of federated learning in real-world scenarios. However, FCL needs to address not only spatial data heterogeneity between clients but also temporal data heterogeneity between tasks. In this paper, empirical experiments demonstrate that such input-level heterogeneity significantly affects the model's internal parameters and outputs, leading to severe spatial-temporal catastrophic forgetting of local and previous knowledge. To this end, we propose Federated Tail Anchor (FedTA) to mix trainable Tail Anchor with the frozen output features to adjust their position in the feature space, thereby overcoming parameter-forgetting and output-forgetting. Moreover, three novel components are also included in FedTA: Input Enhancement for improving the performance of pre-trained models on downstream tasks; Selective Input Knowledge Fusion for fusion of heterogeneous local knowledge on the server side; and Best Global Prototype Selection for finding the best anchor point for each class in the feature space. Extensive experiments demonstrate that FedTA not only outperforms existing FCL methods but also effectively preserves the relative positions of features, remaining unaffected by spatial and temporal changes.
FedCoLLM: A Parameter-Efficient Federated Co-tuning Framework for Large and Small Language Models
Nov 18, 2024


By adapting Large Language Models (LLMs) to domain-specific tasks or enriching them with domain-specific knowledge, we can fully harness the capabilities of LLMs. Nonetheless, a gap persists in achieving simultaneous mutual enhancement between the server's LLM and the downstream clients' Small Language Models (SLMs). To address this, we propose FedCoLLM, a novel and parameter-efficient federated framework designed for co-tuning LLMs and SLMs. This approach is aimed at adaptively transferring server-side LLMs knowledge to clients' SLMs while simultaneously enriching the LLMs with domain insights from the clients. To accomplish this, FedCoLLM utilizes lightweight adapters in conjunction with SLMs, facilitating knowledge exchange between server and clients in a manner that respects data privacy while also minimizing computational and communication overhead. Our evaluation of FedCoLLM, utilizing various public LLMs and SLMs across a range of NLP text generation tasks, reveals that the performance of clients' SLMs experiences notable improvements with the assistance of the LLMs. Simultaneously, the LLMs enhanced via FedCoLLM achieves comparable performance to that obtained through direct fine-tuning on clients' data.