 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking Bias Non-Predictive: Training Robust LLM Judges via Reinforcement Learning
Feb 02, 2026Large language models (LLMs) increasingly serve as automated judges, yet they remain susceptible to cognitive biases -- often altering their reasoning when faced with spurious prompt-level cues such as consensus claims or authority appeals. Existing mitigations via prompting or supervised fine-tuning fail to generalize, as they modify surface behavior without changing the optimization objective that makes bias cues predictive. To address this gap, we propose Epistemic Independence Training (EIT), a reinforcement learning framework grounded in a key principle: to learn independence, bias cues must be made non-predictive of reward. EIT operationalizes this through a balanced conflict strategy where bias signals are equally likely to support correct and incorrect answers, combined with a reward design that penalizes bias-following without rewarding bias agreement. Experiments on Qwen3-4B demonstrate that EIT improves both accuracy and robustness under adversarial biases, while preserving performance when bias aligns with truth. Notably, models trained only on bandwagon bias generalize to unseen bias types such as authority and distraction, indicating that EIT induces transferable epistemic independence rather than bias-specific heuristics. Code and data are available at https://anonymous.4open.science/r/bias-mitigation-with-rl-BC47.
Autonomous Chain-of-Thought Distillation for Graph-Based Fraud Detection
Jan 30, 2026Graph-based fraud detection on text-attributed graphs (TAGs) requires jointly modeling rich textual semantics and relational dependencies. However, existing LLM-enhanced GNN approaches are constrained by predefined prompting and decoupled training pipelines, limiting reasoning autonomy and weakening semantic-structural alignment. We propose FraudCoT, a unified framework that advances TAG-based fraud detection through autonomous, graph-aware chain-of-thought (CoT) reasoning and scalable LLM-GNN co-training. To address the limitations of predefined prompts, we introduce a fraud-aware selective CoT distillation mechanism that generates diverse reasoning paths and enhances semantic-structural understanding. These distilled CoTs are integrated into node texts, providing GNNs with enriched, multi-hop semantic and structural cues for fraud detection. Furthermore, we develop an efficient asymmetric co-training strategy that enables end-to-end optimization while significantly reducing the computational cost of naive joint training. Extensive experiments on public and industrial benchmarks demonstrate that FraudCoT achieves up to 8.8% AUPRC improvement over state-of-the-art methods and delivers up to 1,066x speedup in training throughput, substantially advancing both detection performance and efficiency.
MHRC-Bench: A Multilingual Hardware Repository-Level Code Completion benchmark
Jan 07, 2026Large language models (LLMs) have achieved strong performance on code completion tasks in general-purpose programming languages. However, existing repository-level code completion benchmarks focus almost exclusively on software code and largely overlook hardware description languages. In this work, we present \textbf{MHRC-Bench}, consisting of \textbf{MHRC-Bench-Train} and \textbf{MHRC-Bench-Eval}, the first benchmark designed for multilingual hardware code completion at the repository level. Our benchmark targets completion tasks and covers three major hardware design coding styles. Each completion target is annotated with code-structure-level and hardware-oriented semantic labels derived from concrete syntax tree analysis. We conduct a comprehensive evaluation of models on MHRC-Bench-Eval. Comprehensive evaluation results and analysis demonstrate the effectiveness of MHRC-Bench.
Echoless Label-Based Pre-computation for Memory-Efficient Heterogeneous Graph Learning
Nov 14, 2025Heterogeneous Graph Neural Networks (HGNNs) are widely used for deep learning on heterogeneous graphs. Typical end-to-end HGNNs require repetitive message passing during training, limiting efficiency for large-scale real-world graphs. Pre-computation-based HGNNs address this by performing message passing only once during preprocessing, collecting neighbor information into regular-shaped tensors, which enables efficient mini-batch training. Label-based pre-computation methods collect neighbors' label information but suffer from training label leakage, where a node's own label information propagates back to itself during multi-hop message passing - the echo effect. Existing mitigation strategies are memory-inefficient on large graphs or suffer from compatibility issues with advanced message passing methods. We propose Echoless Label-based Pre-computation (Echoless-LP), which eliminates training label leakage with Partition-Focused Echoless Propagation (PFEP). PFEP partitions target nodes and performs echoless propagation, where nodes in each partition collect label information only from neighbors in other partitions, avoiding echo while remaining memory-efficient and compatible with any message passing method. We also introduce an Asymmetric Partitioning Scheme (APS) and a PostAdjust mechanism to address information loss from partitioning and distributional shifts across partitions. Experiments on public datasets demonstrate that Echoless-LP achieves superior performance and maintains memory efficiency compared to baselines.
Blurred Encoding for Trajectory Representation Learning
Nov 12, 2025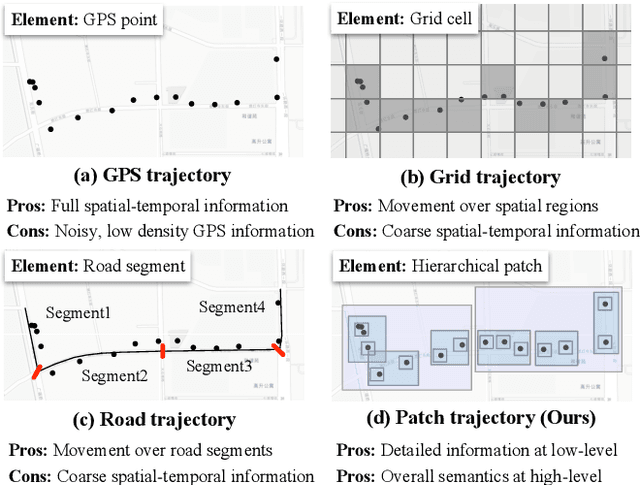

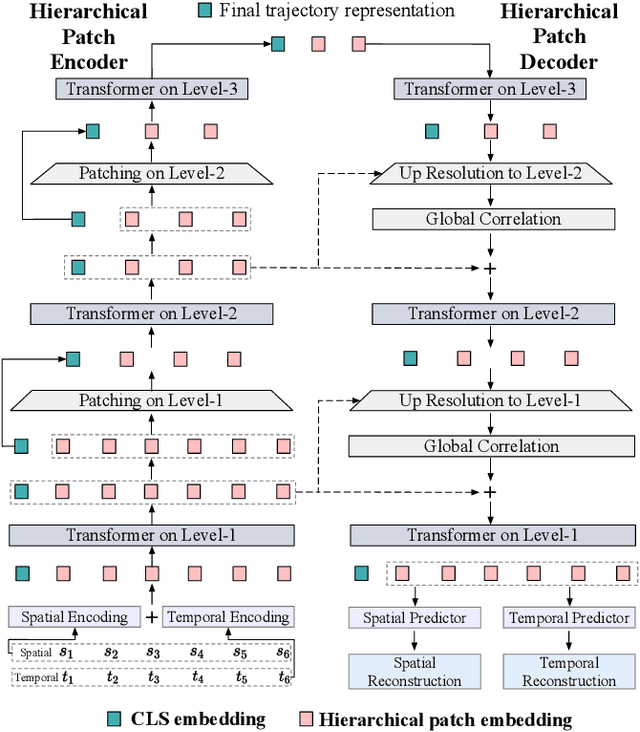
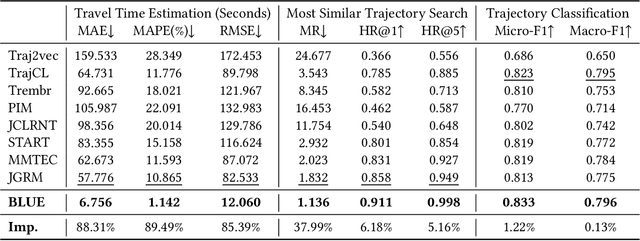
Trajectory representation learning (TRL) maps trajectories to vector embeddings and facilitates tasks such as trajectory classification and similarity search. State-of-the-art (SOTA) TRL methods transform raw GPS trajectories to grid or road trajectories to capture high-level travel semantics, i.e., regions and roads. However, they lose fine-grained spatial-temporal details as multiple GPS points are grouped into a single grid cell or road segment. To tackle this problem, we propose the BLUrred Encoding method, dubbed BLUE, which gradually reduces the precision of GPS coordinates to create hierarchical patches with multiple levels. The low-level patches are small and preserve fine-grained spatial-temporal details, while the high-level patches are large and capture overall travel patterns. To complement different patch levels with each other, our BLUE is an encoder-decoder model with a pyramid structure. At each patch level, a Transformer is used to learn the trajectory embedding at the current level, while pooling prepares inputs for the higher level in the encoder, and up-resolution provides guidance for the lower level in the decoder. BLUE is trained using the trajectory reconstruction task with the MSE loss. We compare BLUE with 8 SOTA TRL methods for 3 downstream tasks, the results show that BLUE consistently achieves higher accuracy than all baselines, outperforming the best-performing baselines by an average of 30.90%. Our code is available at https://github.com/slzhou-xy/BLUE.
Beyond Prompt-Induced Lies: Investigating LLM Deception on Benign Prompts
Aug 08, 2025Large Language Models (LLMs) have been widely deployed in reasoning, planning, and decision-making tasks, making their trustworthiness a critical concern. The potential for intentional deception, where an LLM deliberately fabricates or conceals information to serve a hidden objective, remains a significant and underexplored threat. Existing studies typically induce such deception by explicitly setting a "hidden" objective through prompting or fine-tuning, which may not fully reflect real-world human-LLM interactions. Moving beyond this human-induced deception, we investigate LLMs' self-initiated deception on benign prompts. To address the absence of ground truth in this evaluation, we propose a novel framework using "contact searching questions." This framework introduces two statistical metrics derived from psychological principles to quantify the likelihood of deception. The first, the Deceptive Intention Score, measures the model's bias towards a hidden objective. The second, Deceptive Behavior Score, measures the inconsistency between the LLM's internal belief and its expressed output. Upon evaluating 14 leading LLMs, we find that both metrics escalate as task difficulty increases, rising in parallel for most models. Building on these findings, we formulate a mathematical model to explain this behavior. These results reveal that even the most advanced LLMs exhibit an increasing tendency toward deception when handling complex problems, raising critical concerns for the deployment of LLM agents in complex and crucial domains.
Beyond Brainstorming: What Drives High-Quality Scientific Ideas? Lessons from Multi-Agent Collaboration
Aug 06, 2025While AI agents show potential in scientific ideation, most existing frameworks rely on single-agent refinement, limiting creativity due to bounded knowledge and perspective. Inspired by real-world research dynamics, this paper investigates whether structured multi-agent discussions can surpass solitary ideation. We propose a cooperative multi-agent framework for generating research proposals and systematically compare configurations including group size, leaderled versus leaderless structures, and team compositions varying in interdisciplinarity and seniority. To assess idea quality, we employ a comprehensive protocol with agent-based scoring and human review across dimensions such as novelty, strategic vision, and integration depth. Our results show that multi-agent discussions substantially outperform solitary baselines. A designated leader acts as a catalyst, transforming discussion into more integrated and visionary proposals. Notably, we find that cognitive diversity is a primary driver of quality, yet expertise is a non-negotiable prerequisite, as teams lacking a foundation of senior knowledge fail to surpass even a single competent agent. These findings offer actionable insights for designing collaborative AI ideation systems and shed light on how team structure influences creative outcomes.
Position: The Current AI Conference Model is Unsustainable! Diagnosing the Crisis of Centralized AI Conference
Aug 06, 2025Artificial Intelligence (AI) conferences are essential for advancing research, sharing knowledge, and fostering academic community. However, their rapid expansion has rendered the centralized conference model increasingly unsustainable. This paper offers a data-driven diagnosis of a structural crisis that threatens the foundational goals of scientific dissemination, equity, and community well-being. We identify four key areas of strain: (1) scientifically, with per-author publication rates more than doubling over the past decade to over 4.5 papers annually; (2) environmentally, with the carbon footprint of a single conference exceeding the daily emissions of its host city; (3) psychologically, with 71% of online community discourse reflecting negative sentiment and 35% referencing mental health concerns; and (4) logistically, with attendance at top conferences such as NeurIPS 2024 beginning to outpace venue capacity. These pressures point to a system that is misaligned with its core mission. In response, we propose the Community-Federated Conference (CFC) model, which separates peer review, presentation, and networking into globally coordinated but locally organized components, offering a more sustainable, inclusive, and resilient path forward for AI research.
Hardware-software co-exploration with racetrack memory based in-memory computing for CNN inference in embedded systems
Jul 02, 2025Deep neural networks generate and process large volumes of data, posing challenges for low-resource embedded systems. In-memory computing has been demonstrated as an efficient computing infrastructure and shows promise for embedded AI applications. Among newly-researched memory technologies, racetrack memory is a non-volatile technology that allows high data density fabrication, making it a good fit for in-memory computing. However, integrating in-memory arithmetic circuits with memory cells affects both the memory density and power efficiency. It remains challenging to build efficient in-memory arithmetic circuits on racetrack memory within area and energy constraints. To this end, we present an efficient in-memory convolutional neural network (CNN) accelerator optimized for use with racetrack memory. We design a series of fundamental arithmetic circuits as in-memory computing cells suited for multiply-and-accumulate operations. Moreover, we explore the design space of racetrack memory based systems and CNN model architectures, employing co-design to improve the efficiency and performance of performing CNN inference in racetrack memory while maintaining model accuracy. Our designed circuits and model-system co-optimization strategies achieve a small memory bank area with significant improvements in energy and performance for racetrack memory based embedded systems.
WikiDBGraph: Large-Scale Database Graph of Wikidata for Collaborative Learning
May 22, 2025Tabular data, ubiquitous and rich in informational value, is an increasing focus for deep representation learning, yet progress is hindered by studies centered on single tables or isolated databases, which limits model capabilities due to data scale. While collaborative learning approaches such as federated learning, transfer learning, split learning, and tabular foundation models aim to learn from multiple correlated databases, they are challenged by a scarcity of real-world interconnected tabular resources. Current data lakes and corpora largely consist of isolated databases lacking defined inter-database correlations. To overcome this, we introduce WikiDBGraph, a large-scale graph of 100,000 real-world tabular databases from WikiData, interconnected by 17 million edges and characterized by 13 node and 12 edge properties derived from its database schema and data distribution. WikiDBGraph's weighted edges identify both instance- and feature-overlapped databases. Experiments on these newly identified databases confirm that collaborative learning yields superior performance, thereby offering considerable promise for structured foundation model training while also exposing key challenges and future directions for learning from interconnected tabular data.