 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePIDT: Physics-Informed Digital Twin for Optical Fiber Parameter Estimation
Jan 12, 2026We propose physics-informed digital twin (PIDT): a fiber parameter estimation approach that combines a parameterized split-step method with a physics-informed loss. PIDT improves accuracy and convergence speed with lower complexity compared to previous neural operators.
AhaKV: Adaptive Holistic Attention-Driven KV Cache Eviction for Efficient Inference of Large Language Models
Jun 04, 2025Large Language Models (LLMs) have significantly advanced the field of Artificial Intelligence. However, their deployment is resource-intensive, not only due to the large number of model parameters but also because the (Key-Value) KV cache consumes a lot of memory during inference. While several works propose reducing the KV cache by evicting the unnecessary tokens, these approaches rely on accumulated attention score as eviction score to quantify the importance of the token. We identify the accumulated attention score is biased and it decreases with the position of the tokens in the mathematical expectation. As a result, the retained tokens concentrate on the initial positions, limiting model's access to global contextual information. To address this issue, we propose Adaptive holistic attention KV (AhaKV), it addresses the bias of the accumulated attention score by adaptively tuning the scale of softmax according the expectation of information entropy of attention scores. To make use of the holistic attention information in self-attention mechanism, AhaKV utilize the information of value vectors, which is overlooked in previous works, to refine the adaptive score. We show theoretically that our method is well suited for bias reduction. We deployed AhaKV on different models with a fixed cache budget. Experiments show that AhaKV successfully mitigates bias and retains crucial tokens across global context and achieve state-of-the-art results against other related work on several benchmark tasks.
LogQuant: Log-Distributed 2-Bit Quantization of KV Cache with Superior Accuracy Preservation
Mar 25, 2025We introduce LogQuant, a groundbreaking 2-bit quantization technique for KV Cache in large language model (LLM) inference, delivering substantial memory savings while preserving superior performance. Previous methods either assume that later tokens are more important or attempt to predict important tokens based on earlier attention patterns. Both approaches, however, can result in performance bottlenecks or frequent mispredictions. LogQuant takes a different approach. By applying a log-based filtering mechanism, it selectively compresses the KV Cache across the entire context, achieving better performance with the same or even reduced memory footprint compared to existing methods. In benchmark tests, it enhances throughput by 25% and boosts batch size by 60% without increasing memory consumption. For challenging tasks such as Math and Code Completion, LogQuant improves accuracy by 40% to 200% at the same compression ratio, outperforming comparable techniques.LogQuant integrates effortlessly with popular inference frameworks like Python's transformers library. Implementation can be available in https://github.com/Concyclics/LogQuantKV.
FDS: Frequency-Aware Denoising Score for Text-Guided Latent Diffusion Image Editing
Mar 24, 2025



Text-guided image editing using Text-to-Image (T2I) models often fails to yield satisfactory results, frequently introducing unintended modifications, such as the loss of local detail and color changes. In this paper, we analyze these failure cases and attribute them to the indiscriminate optimization across all frequency bands, even though only specific frequencies may require adjustment. To address this, we introduce a simple yet effective approach that enables the selective optimization of specific frequency bands within localized spatial regions for precise edits. Our method leverages wavelets to decompose images into different spatial resolutions across multiple frequency bands, enabling precise modifications at various levels of detail. To extend the applicability of our approach, we provide a comparative analysis of different frequency-domain techniques. Additionally, we extend our method to 3D texture editing by performing frequency decomposition on the triplane representation, enabling frequency-aware adjustments for 3D textures. Quantitative evaluations and user studies demonstrate the effectiveness of our method in producing high-quality and precise edits.
Real-time object detection method based on improved YOLOv4-tiny
Nov 09, 2020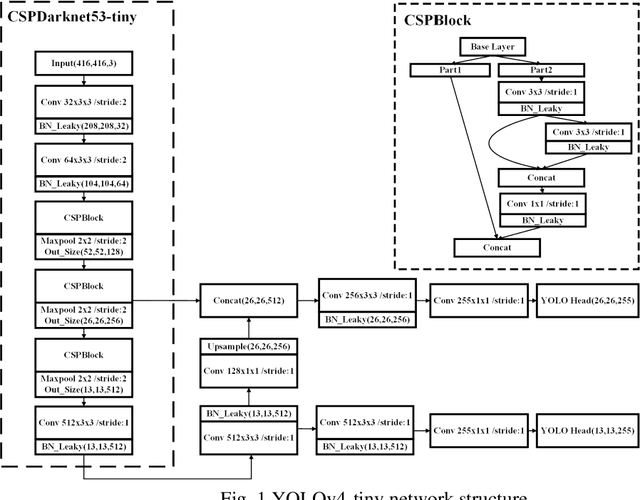
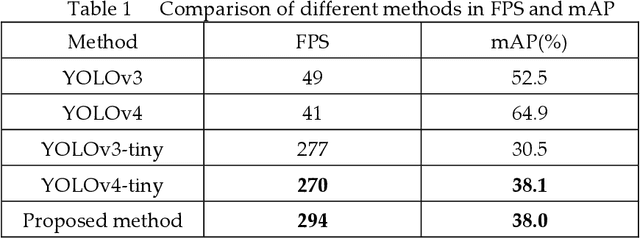
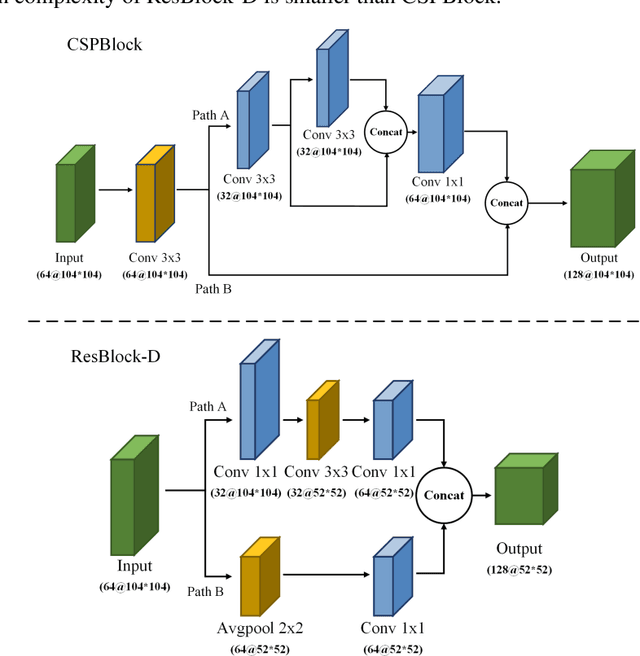
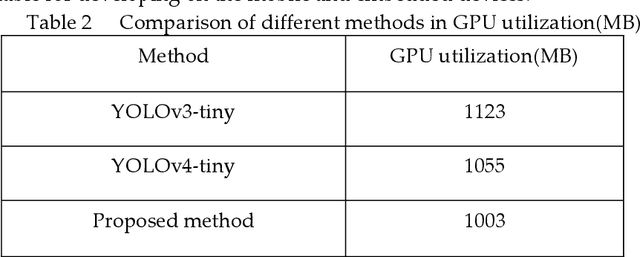
The "You only look once v4"(YOLOv4) is one type of object detection methods in deep learning. YOLOv4-tiny is proposed based on YOLOv4 to simple the network structure and reduce parameters, which makes it be suitable for developing on the mobile and embedded devices. To improve the real-time of object detection, a fast object detection method is proposed based on YOLOv4-tiny. It firstly uses two ResBlock-D modules in ResNet-D network instead of two CSPBlock modules in Yolov4-tiny, which reduces the computation complexity. Secondly, it designs an auxiliary residual network block to extract more feature information of object to reduce detection error. In the design of auxiliary network, two consecutive 3x3 convolutions are used to obtain 5x5 receptive fields to extract global features, and channel attention and spatial attention are also used to extract more effective information. In the end, it merges the auxiliary network and backbone network to construct the whole network structure of improved YOLOv4-tiny. Simulation results show that the proposed method has faster object detection than YOLOv4-tiny and YOLOv3-tiny, and almost the same mean value of average precision as the YOLOv4-tiny. It is more suitable for real-time object detection.