 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeatInsight: An Online ML Feature Management System on 4Paradigm Sage-Studio Platform
Apr 01, 2025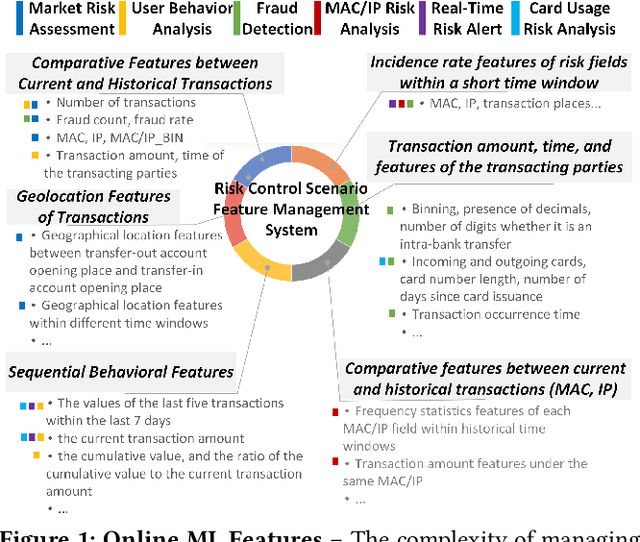
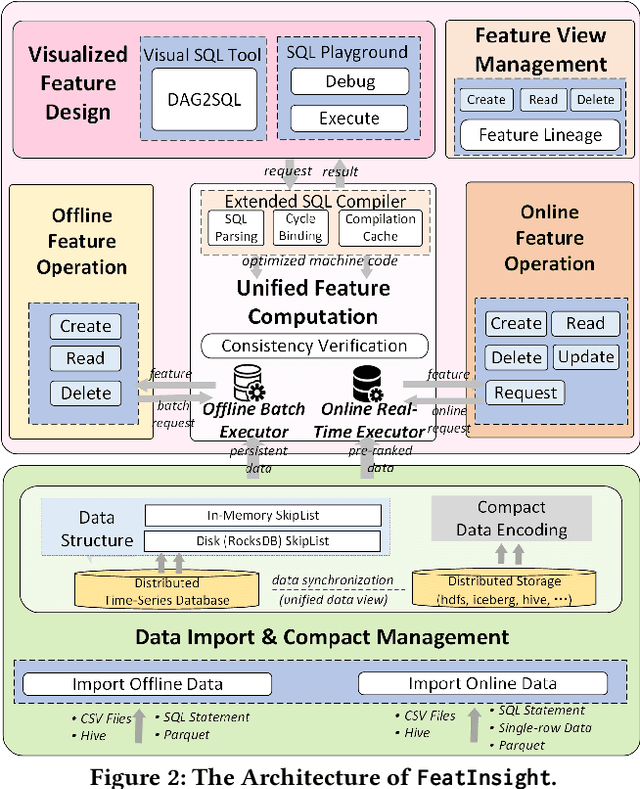
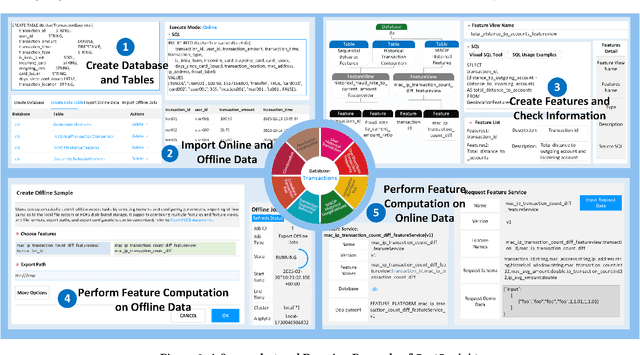
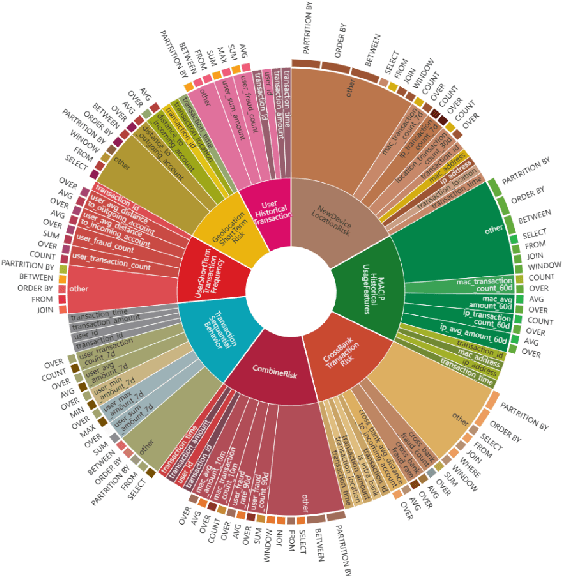
Feature management is essential for many online machine learning applications and can often become the performance bottleneck (e.g., taking up to 70% of the overall latency in sales prediction service). Improper feature configurations (e.g., introducing too many irrelevant features) can severely undermine the model's generalization capabilities. However, managing online ML features is challenging due to (1) large-scale, complex raw data (e.g., the 2018 PHM dataset contains 17 tables and dozens to hundreds of columns), (2) the need for high-performance, consistent computation of interdependent features with complex patterns, and (3) the requirement for rapid updates and deployments to accommodate real-time data changes. In this demo, we present FeatInsight, a system that supports the entire feature lifecycle, including feature design, storage, visualization, computation, verification, and lineage management. FeatInsight (with OpenMLDB as the execution engine) has been deployed in over 100 real-world scenarios on 4Paradigm's Sage Studio platform, handling up to a trillion-dimensional feature space and enabling millisecond-level feature updates. We demonstrate how FeatInsight enhances feature design efficiency (e.g., for online product recommendation) and improve feature computation performance (e.g., for online fraud detection). The code is available at https://github.com/4paradigm/FeatInsight.
LogQuant: Log-Distributed 2-Bit Quantization of KV Cache with Superior Accuracy Preservation
Mar 25, 2025



We introduce LogQuant, a groundbreaking 2-bit quantization technique for KV Cache in large language model (LLM) inference, delivering substantial memory savings while preserving superior performance. Previous methods either assume that later tokens are more important or attempt to predict important tokens based on earlier attention patterns. Both approaches, however, can result in performance bottlenecks or frequent mispredictions. LogQuant takes a different approach. By applying a log-based filtering mechanism, it selectively compresses the KV Cache across the entire context, achieving better performance with the same or even reduced memory footprint compared to existing methods. In benchmark tests, it enhances throughput by 25% and boosts batch size by 60% without increasing memory consumption. For challenging tasks such as Math and Code Completion, LogQuant improves accuracy by 40% to 200% at the same compression ratio, outperforming comparable techniques.LogQuant integrates effortlessly with popular inference frameworks like Python's transformers library. Implementation can be available in https://github.com/Concyclics/LogQuantKV.
OpenMLDB: A Real-Time Relational Data Feature Computation System for Online ML
Jan 15, 2025



Efficient and consistent feature computation is crucial for a wide range of online ML applications. Typically, feature computation is divided into two distinct phases, i.e., offline stage for model training and online stage for model serving. These phases often rely on execution engines with different interface languages and function implementations, causing significant inconsistencies. Moreover, many online ML features involve complex time-series computations (e.g., functions over varied-length table windows) that differ from standard streaming and analytical queries. Existing data processing systems (e.g., Spark, Flink, DuckDB) often incur multi-second latencies for these computations, making them unsuitable for real-time online ML applications that demand timely feature updates. This paper presents OpenMLDB, a feature computation system deployed in 4Paradigm's SageOne platform and over 100 real scenarios. Technically, OpenMLDB first employs a unified query plan generator for consistent computation results across the offline and online stages, significantly reducing feature deployment overhead. Second, OpenMLDB provides an online execution engine that resolves performance bottlenecks caused by long window computations (via pre-aggregation) and multi-table window unions (via data self-adjusting). It also provides a high-performance offline execution engine with window parallel optimization and time-aware data skew resolving. Third, OpenMLDB features a compact data format and stream-focused indexing to maximize memory usage and accelerate data access. Evaluations in testing and real workloads reveal significant performance improvements and resource savings compared to the baseline systems. The open community of OpenMLDB now has over 150 contributors and gained 1.6k stars on GitHub.
IIP-Mixer:Intra-Inter Patch Mixing Architecture for Battery Remaining Useful Life Prediction
Mar 27, 2024



Accurately estimating the Remaining Useful Life (RUL) of lithium-ion batteries is crucial for maintaining the safe and stable operation of rechargeable battery management systems. However, this task is often challenging due to the complex temporal dynamics involved. Recently, attention-based networks, such as Transformers and Informer, have been the popular architecture in time series forecasting. Despite their effectiveness, these models with abundant parameters necessitate substantial training time to unravel temporal patterns. To tackle these challenges, we propose a simple MLP-Mixer-based architecture named 'Intra-Inter Patch Mixer' (IIP-Mixer), which is an architecture based exclusively on multi-layer perceptrons (MLPs), extracting information by mixing operations along both intra-patch and inter-patch dimensions for battery RUL prediction. The proposed IIP-Mixer comprises parallel dual-head mixer layers: the intra-patch mixing MLP, capturing local temporal patterns in the short-term period, and the inter-patch mixing MLP, capturing global temporal patterns in the long-term period. Notably, to address the varying importance of features in RUL prediction, we introduce a weighted loss function in the MLP-Mixer-based architecture, marking the first time such an approach has been employed. Our experiments demonstrate that IIP-Mixer achieves competitive performance in battery RUL prediction, outperforming other popular time-series frameworks
Network On Network for Tabular Data Classification in Real-world Applications
May 29, 2020
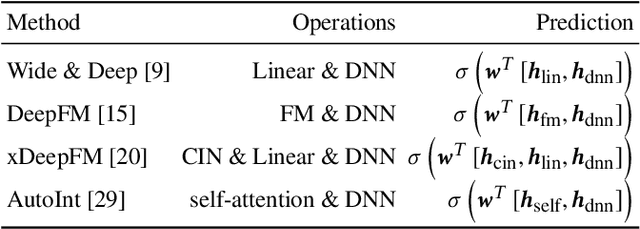
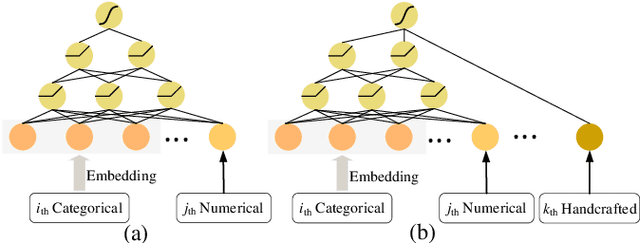
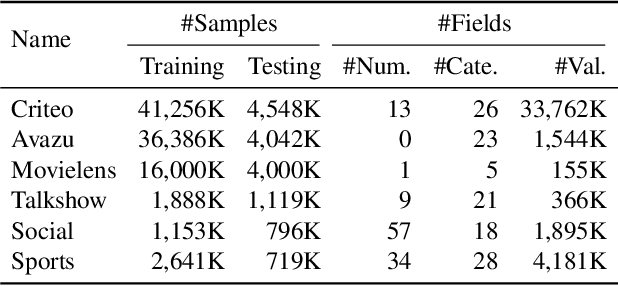
Tabular data is the most common data format adopted by our customers ranging from retail, finance to E-commerce, and tabular data classification plays an essential role to their businesses. In this paper, we present Network On Network (NON), a practical tabular data classification model based on deep neural network to provide accurate predictions. Various deep methods have been proposed and promising progress has been made. However, most of them use operations like neural network and factorization machines to fuse the embeddings of different features directly, and linearly combine the outputs of those operations to get the final prediction. As a result, the intra-field information and the non-linear interactions between those operations (e.g. neural network and factorization machines) are ignored. Intra-field information is the information that features inside each field belong to the same field. NON is proposed to take full advantage of intra-field information and non-linear interactions. It consists of three components: field-wise network at the bottom to capture the intra-field information, across field network in the middle to choose suitable operations data-drivenly, and operation fusion network on the top to fuse outputs of the chosen operations deeply. Extensive experiments on six real-world datasets demonstrate NON can outperform the state-of-the-art models significantly. Furthermore, both qualitative and quantitative study of the features in the embedding space show NON can capture intra-field information effectively.
AutoML @ NeurIPS 2018 challenge: Design and Results
Mar 14, 2019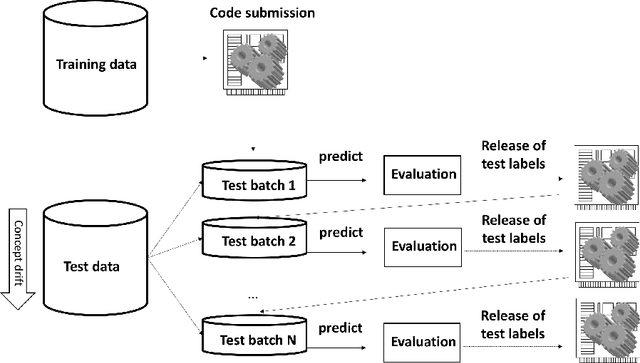
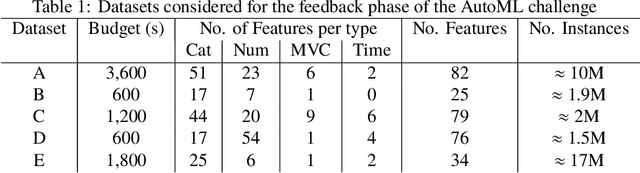

We organized a competition on Autonomous Lifelong Machine Learning with Drift that was part of the competition program of NeurIPS 2018. This data driven competition asked participants to develop computer programs capable of solving supervised learning problems where the i.i.d. assumption did not hold. Large data sets were arranged in a lifelong learning and evaluation scenario and CodaLab was used as the challenge platform. The challenge attracted more than 300 participants in its two month duration. This chapter describes the design of the challenge and summarizes its main results.
Privacy-preserving Transfer Learning for Knowledge Sharing
Nov 23, 2018
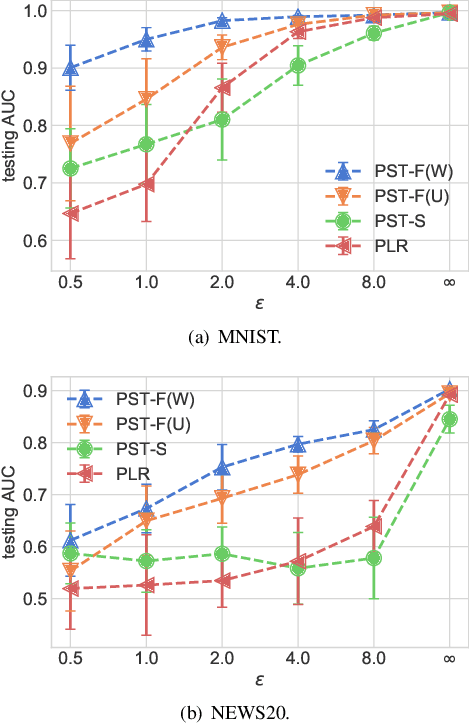
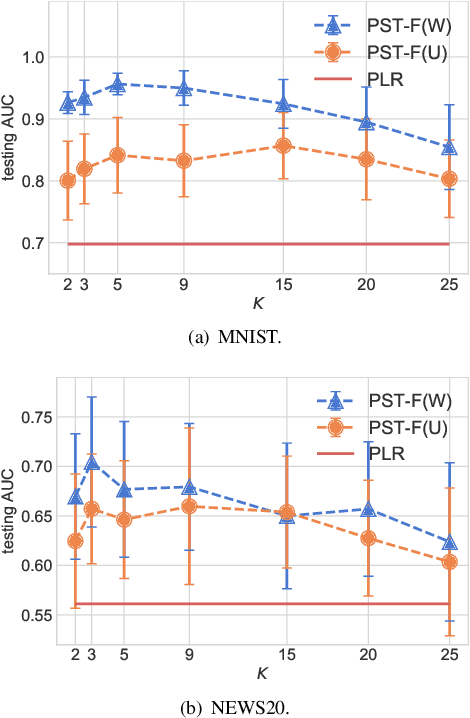

In many practical machine-learning applications, it is critical to allow knowledge to be transferred from external domains while preserving user privacy. Unfortunately, existing transfer-learning works do not have a privacy guarantee. In this paper, for the first time, we propose a method that can simultaneously transfer knowledge from external datasets while offering an $\epsilon$-differential privacy guarantee. First, we show that a simple combination of the hypothesis transfer learning and the privacy preserving logistic regression can address the problem. However, the performance of this approach can be poor as the sample size in the target domain may be small. To address this problem, we propose a new method which splits the feature set in source and target data into several subsets, and trains models on these subsets before finally aggregating the predictions by a stacked generalization. Feature importance can also be incorporated into the proposed method to further improve performance. We prove that the proposed method has an $\epsilon$-differential privacy guarantee, and further analysis shows that its performance is better than above simple combination given the same privacy budget. Finally, experiments on MINST and real-world RUIJIN datasets show that our proposed method achieves the start-of-the-art performance.