 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNetwork On Network for Tabular Data Classification in Real-world Applications
May 29, 2020
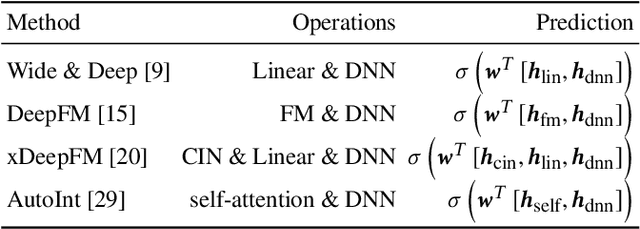
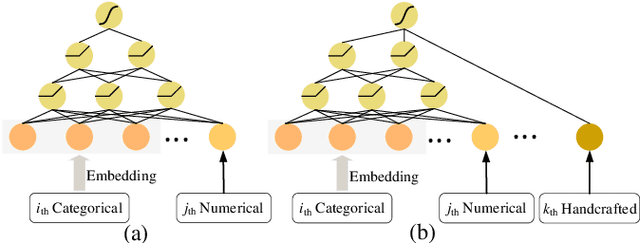
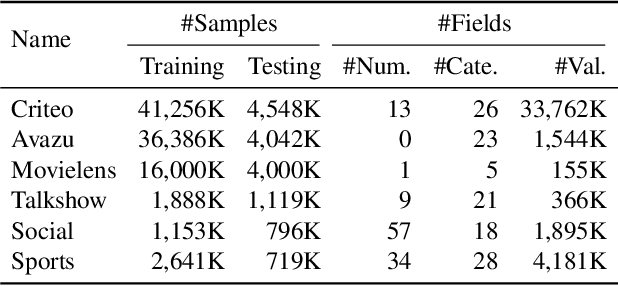
Tabular data is the most common data format adopted by our customers ranging from retail, finance to E-commerce, and tabular data classification plays an essential role to their businesses. In this paper, we present Network On Network (NON), a practical tabular data classification model based on deep neural network to provide accurate predictions. Various deep methods have been proposed and promising progress has been made. However, most of them use operations like neural network and factorization machines to fuse the embeddings of different features directly, and linearly combine the outputs of those operations to get the final prediction. As a result, the intra-field information and the non-linear interactions between those operations (e.g. neural network and factorization machines) are ignored. Intra-field information is the information that features inside each field belong to the same field. NON is proposed to take full advantage of intra-field information and non-linear interactions. It consists of three components: field-wise network at the bottom to capture the intra-field information, across field network in the middle to choose suitable operations data-drivenly, and operation fusion network on the top to fuse outputs of the chosen operations deeply. Extensive experiments on six real-world datasets demonstrate NON can outperform the state-of-the-art models significantly. Furthermore, both qualitative and quantitative study of the features in the embedding space show NON can capture intra-field information effectively.
AutoKGE: Searching Scoring Functions for Knowledge Graph Embedding
Jun 03, 2019


Scoring functions (SFs), which measure the plausibility of links between entities based on a given relation, have become the crux of knowledge graph embedding (KGE). Lots of SFs have been designed by humans in recent years. However, the improvements are getting marginal and none of them consistently achieve the best performance over various datasets. Inspired by the recent success of automated machine learning (AutoML), we propose the automated KGE (AutoKGE) in this paper to automatically design SFs for distinct KGs. We firstly identify a unified representation over popularly used SFs, which helps to set up a search space for AutoKGE. Then, we propose a greedy algorithm, which is enhanced by a filter and a predictor, to efficiently search in such a space. Extensive experiments on benchmark datasets demonstrate the effectiveness and efficiency of the proposed AutoKGE. The SFs, searched by our method, are KG dependent, new to the literature, and outperform the state-of-the-art SFs designed by humans.
AutoML @ NeurIPS 2018 challenge: Design and Results
Mar 14, 2019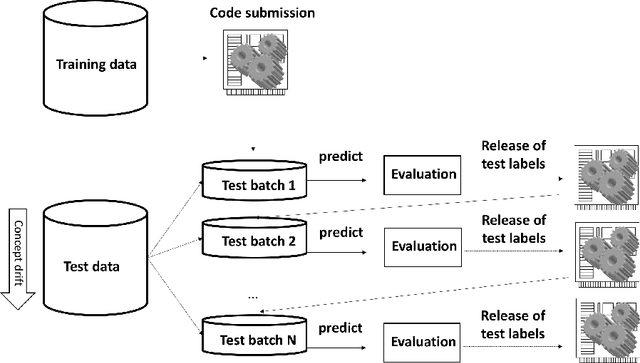
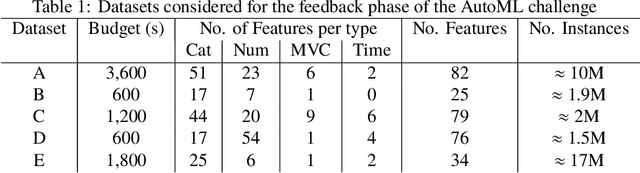

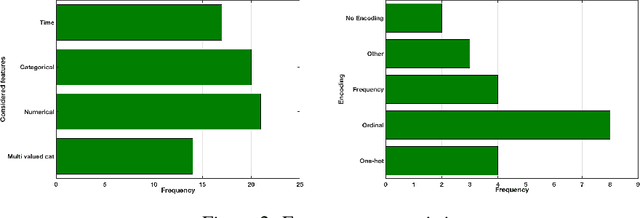
We organized a competition on Autonomous Lifelong Machine Learning with Drift that was part of the competition program of NeurIPS 2018. This data driven competition asked participants to develop computer programs capable of solving supervised learning problems where the i.i.d. assumption did not hold. Large data sets were arranged in a lifelong learning and evaluation scenario and CodaLab was used as the challenge platform. The challenge attracted more than 300 participants in its two month duration. This chapter describes the design of the challenge and summarizes its main results.
Privacy-preserving Transfer Learning for Knowledge Sharing
Nov 23, 2018
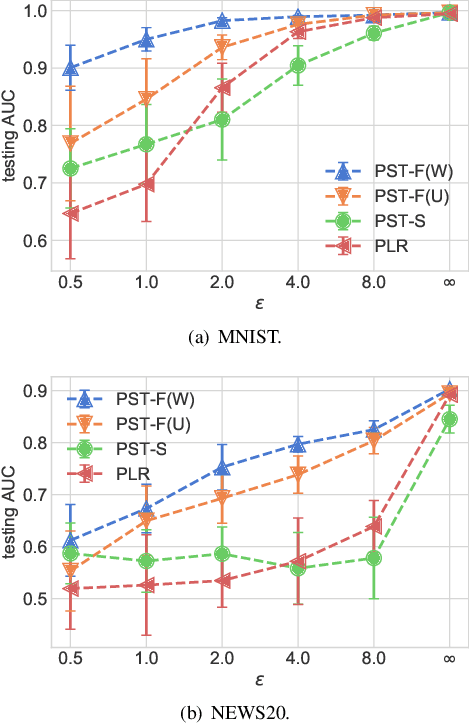
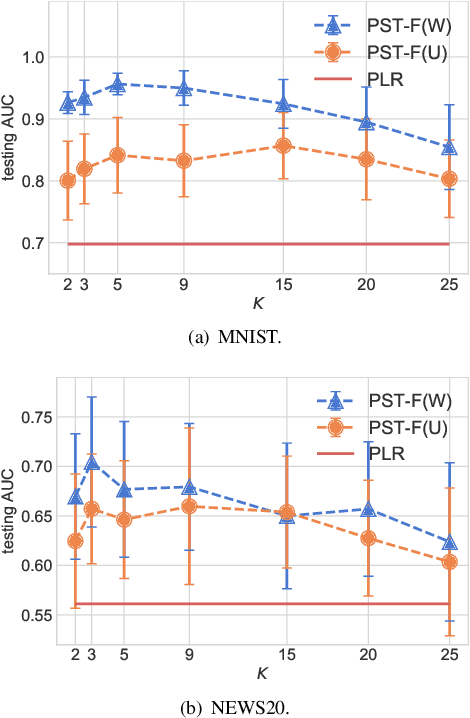

In many practical machine-learning applications, it is critical to allow knowledge to be transferred from external domains while preserving user privacy. Unfortunately, existing transfer-learning works do not have a privacy guarantee. In this paper, for the first time, we propose a method that can simultaneously transfer knowledge from external datasets while offering an $\epsilon$-differential privacy guarantee. First, we show that a simple combination of the hypothesis transfer learning and the privacy preserving logistic regression can address the problem. However, the performance of this approach can be poor as the sample size in the target domain may be small. To address this problem, we propose a new method which splits the feature set in source and target data into several subsets, and trains models on these subsets before finally aggregating the predictions by a stacked generalization. Feature importance can also be incorporated into the proposed method to further improve performance. We prove that the proposed method has an $\epsilon$-differential privacy guarantee, and further analysis shows that its performance is better than above simple combination given the same privacy budget. Finally, experiments on MINST and real-world RUIJIN datasets show that our proposed method achieves the start-of-the-art performance.