 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombating Bilateral Edge Noise for Robust Link Prediction
Nov 02, 2023


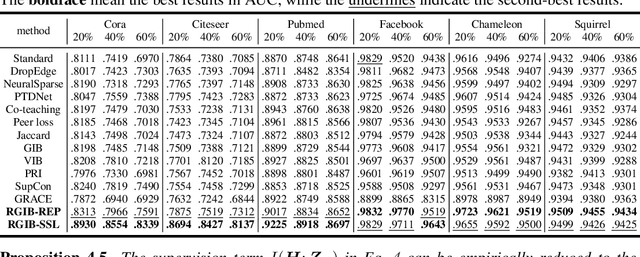
Although link prediction on graphs has achieved great success with the development of graph neural networks (GNNs), the potential robustness under the edge noise is still less investigated. To close this gap, we first conduct an empirical study to disclose that the edge noise bilaterally perturbs both input topology and target label, yielding severe performance degradation and representation collapse. To address this dilemma, we propose an information-theory-guided principle, Robust Graph Information Bottleneck (RGIB), to extract reliable supervision signals and avoid representation collapse. Different from the basic information bottleneck, RGIB further decouples and balances the mutual dependence among graph topology, target labels, and representation, building new learning objectives for robust representation against the bilateral noise. Two instantiations, RGIB-SSL and RGIB-REP, are explored to leverage the merits of different methodologies, i.e., self-supervised learning and data reparameterization, for implicit and explicit data denoising, respectively. Extensive experiments on six datasets and three GNNs with diverse noisy scenarios verify the effectiveness of our RGIB instantiations. The code is publicly available at: https://github.com/tmlr-group/RGIB.
Exploring Model Dynamics for Accumulative Poisoning Discovery
Jun 06, 2023Adversarial poisoning attacks pose huge threats to various machine learning applications. Especially, the recent accumulative poisoning attacks show that it is possible to achieve irreparable harm on models via a sequence of imperceptible attacks followed by a trigger batch. Due to the limited data-level discrepancy in real-time data streaming, current defensive methods are indiscriminate in handling the poison and clean samples. In this paper, we dive into the perspective of model dynamics and propose a novel information measure, namely, Memorization Discrepancy, to explore the defense via the model-level information. By implicitly transferring the changes in the data manipulation to that in the model outputs, Memorization Discrepancy can discover the imperceptible poison samples based on their distinct dynamics from the clean samples. We thoroughly explore its properties and propose Discrepancy-aware Sample Correction (DSC) to defend against accumulative poisoning attacks. Extensive experiments comprehensively characterized Memorization Discrepancy and verified its effectiveness. The code is publicly available at: https://github.com/tmlr-group/Memorization-Discrepancy.
TabGNN: Multiplex Graph Neural Network for Tabular Data Prediction
Aug 20, 2021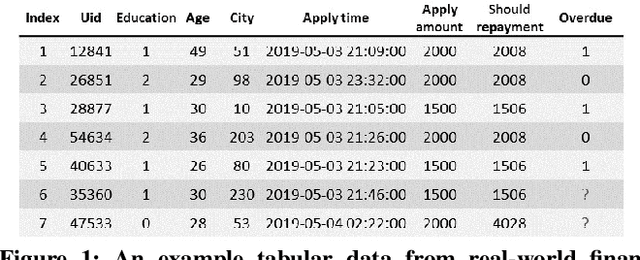

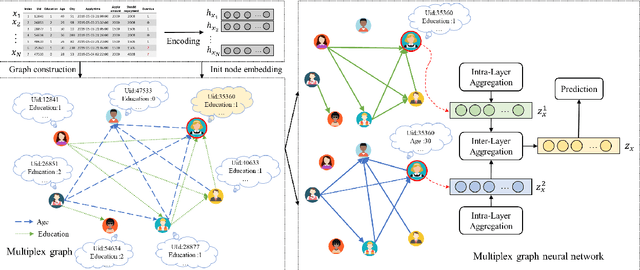
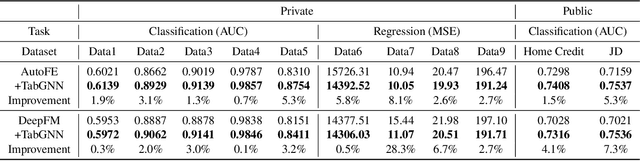
Tabular data prediction (TDP) is one of the most popular industrial applications, and various methods have been designed to improve the prediction performance. However, existing works mainly focus on feature interactions and ignore sample relations, e.g., users with the same education level might have a similar ability to repay the debt. In this work, by explicitly and systematically modeling sample relations, we propose a novel framework TabGNN based on recently popular graph neural networks (GNN). Specifically, we firstly construct a multiplex graph to model the multifaceted sample relations, and then design a multiplex graph neural network to learn enhanced representation for each sample. To integrate TabGNN with the tabular solution in our company, we concatenate the learned embeddings and the original ones, which are then fed to prediction models inside the solution. Experiments on eleven TDP datasets from various domains, including classification and regression ones, show that TabGNN can consistently improve the performance compared to the tabular solution AutoFE in 4Paradigm.
Task-wise Split Gradient Boosting Trees for Multi-center Diabetes Prediction
Aug 16, 2021



Diabetes prediction is an important data science application in the social healthcare domain. There exist two main challenges in the diabetes prediction task: data heterogeneity since demographic and metabolic data are of different types, data insufficiency since the number of diabetes cases in a single medical center is usually limited. To tackle the above challenges, we employ gradient boosting decision trees (GBDT) to handle data heterogeneity and introduce multi-task learning (MTL) to solve data insufficiency. To this end, Task-wise Split Gradient Boosting Trees (TSGB) is proposed for the multi-center diabetes prediction task. Specifically, we firstly introduce task gain to evaluate each task separately during tree construction, with a theoretical analysis of GBDT's learning objective. Secondly, we reveal a problem when directly applying GBDT in MTL, i.e., the negative task gain problem. Finally, we propose a novel split method for GBDT in MTL based on the task gain statistics, named task-wise split, as an alternative to standard feature-wise split to overcome the mentioned negative task gain problem. Extensive experiments on a large-scale real-world diabetes dataset and a commonly used benchmark dataset demonstrate TSGB achieves superior performance against several state-of-the-art methods. Detailed case studies further support our analysis of negative task gain problems and provide insightful findings. The proposed TSGB method has been deployed as an online diabetes risk assessment software for early diagnosis.
AutoSpeech 2020: The Second Automated Machine Learning Challenge for Speech Classification
Oct 25, 2020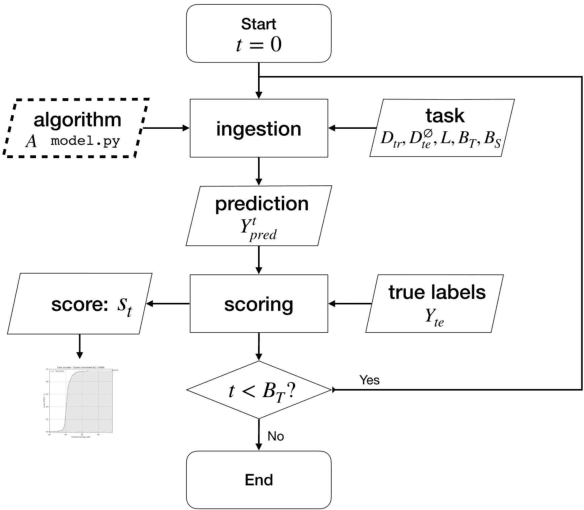
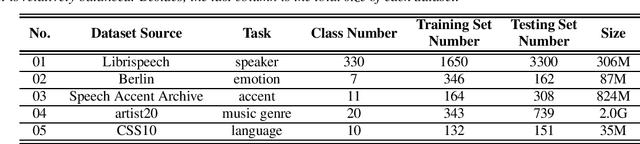
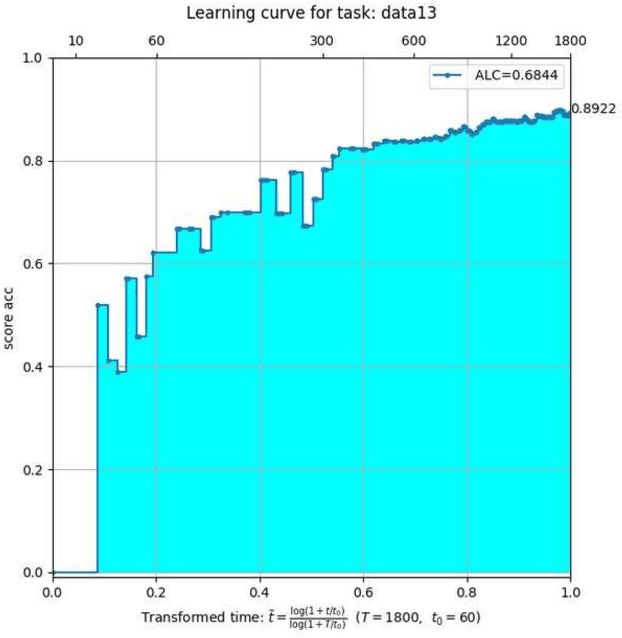
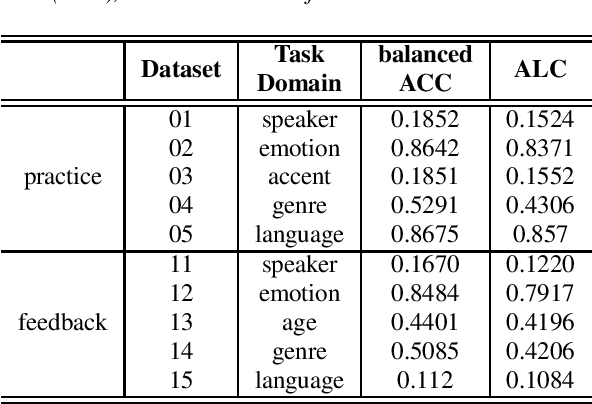
The AutoSpeech challenge calls for automated machine learning (AutoML) solutions to automate the process of applying machine learning to speech processing tasks. These tasks, which cover a large variety of domains, will be shown to the automated system in a random order. Each time when the tasks are switched, the information of the new task will be hinted with its corresponding training set. Thus, every submitted solution should contain an adaptation routine which adapts the system to the new task. Compared to the first edition, the 2020 edition includes advances of 1) more speech tasks, 2) noisier data in each task, 3) a modified evaluation metric. This paper outlines the challenge and describe the competition protocol, datasets, evaluation metric, starting kit, and baseline systems.
Privacy-preserving Transfer Learning for Knowledge Sharing
Nov 23, 2018
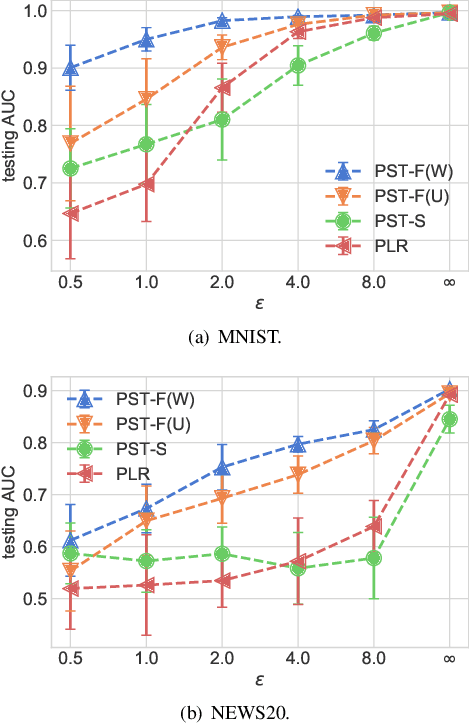
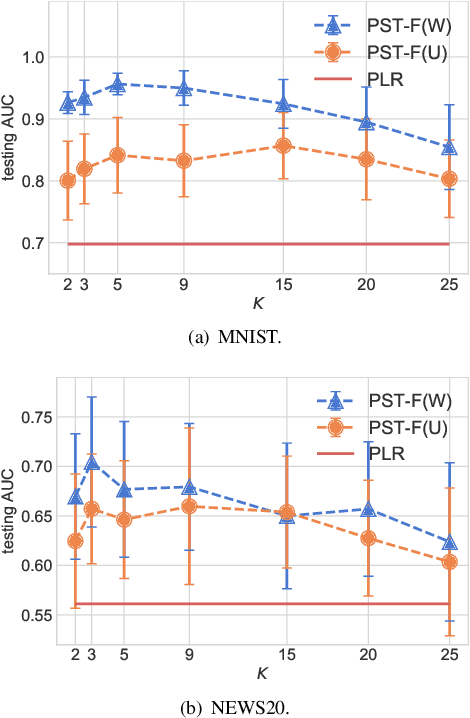

In many practical machine-learning applications, it is critical to allow knowledge to be transferred from external domains while preserving user privacy. Unfortunately, existing transfer-learning works do not have a privacy guarantee. In this paper, for the first time, we propose a method that can simultaneously transfer knowledge from external datasets while offering an $\epsilon$-differential privacy guarantee. First, we show that a simple combination of the hypothesis transfer learning and the privacy preserving logistic regression can address the problem. However, the performance of this approach can be poor as the sample size in the target domain may be small. To address this problem, we propose a new method which splits the feature set in source and target data into several subsets, and trains models on these subsets before finally aggregating the predictions by a stacked generalization. Feature importance can also be incorporated into the proposed method to further improve performance. We prove that the proposed method has an $\epsilon$-differential privacy guarantee, and further analysis shows that its performance is better than above simple combination given the same privacy budget. Finally, experiments on MINST and real-world RUIJIN datasets show that our proposed method achieves the start-of-the-art performance.
Fast Learning with Nonconvex L1-2 Regularization
Jun 20, 2017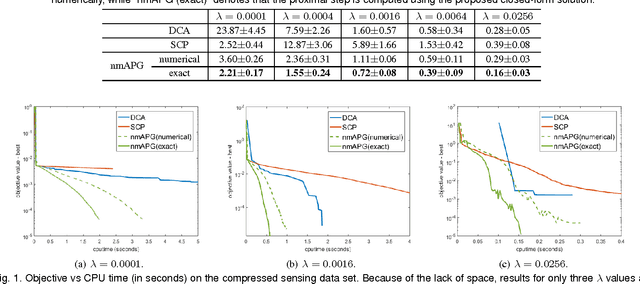
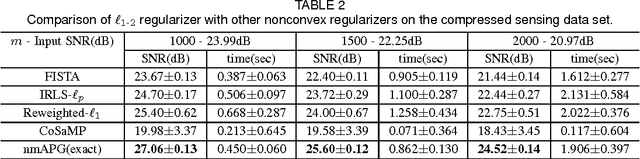
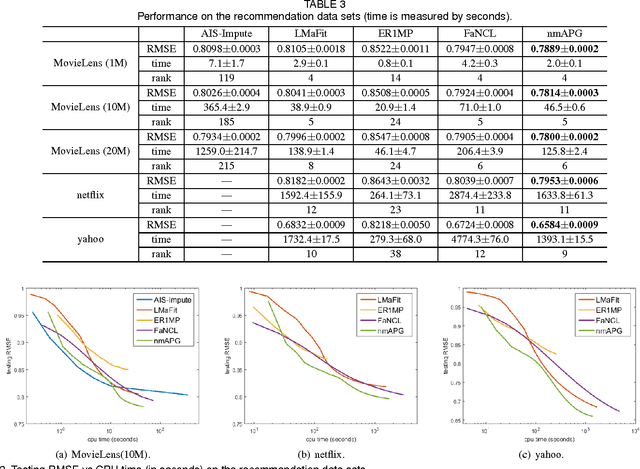
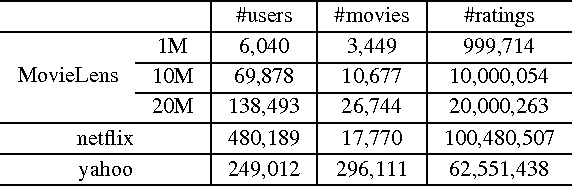
Convex regularizers are often used for sparse learning. They are easy to optimize, but can lead to inferior prediction performance. The difference of $\ell_1$ and $\ell_2$ ($\ell_{1-2}$) regularizer has been recently proposed as a nonconvex regularizer. It yields better recovery than both $\ell_0$ and $\ell_1$ regularizers on compressed sensing. However, how to efficiently optimize its learning problem is still challenging. The main difficulty is that both the $\ell_1$ and $\ell_2$ norms in $\ell_{1-2}$ are not differentiable, and existing optimization algorithms cannot be applied. In this paper, we show that a closed-form solution can be derived for the proximal step associated with this regularizer. We further extend the result for low-rank matrix learning and the total variation model. Experiments on both synthetic and real data sets show that the resultant accelerated proximal gradient algorithm is more efficient than other noncovex optimization algorithms.