 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCopyright Detective: A Forensic System to Evidence LLMs Flickering Copyright Leakage Risks
Feb 05, 2026We present Copyright Detective, the first interactive forensic system for detecting, analyzing, and visualizing potential copyright risks in LLM outputs. The system treats copyright infringement versus compliance as an evidence discovery process rather than a static classification task due to the complex nature of copyright law. It integrates multiple detection paradigms, including content recall testing, paraphrase-level similarity analysis, persuasive jailbreak probing, and unlearning verification, within a unified and extensible framework. Through interactive prompting, response collection, and iterative workflows, our system enables systematic auditing of verbatim memorization and paraphrase-level leakage, supporting responsible deployment and transparent evaluation of LLM copyright risks even with black-box access.
DreaMontage: Arbitrary Frame-Guided One-Shot Video Generation
Dec 24, 2025The "one-shot" technique represents a distinct and sophisticated aesthetic in filmmaking. However, its practical realization is often hindered by prohibitive costs and complex real-world constraints. Although emerging video generation models offer a virtual alternative, existing approaches typically rely on naive clip concatenation, which frequently fails to maintain visual smoothness and temporal coherence. In this paper, we introduce DreaMontage, a comprehensive framework designed for arbitrary frame-guided generation, capable of synthesizing seamless, expressive, and long-duration one-shot videos from diverse user-provided inputs. To achieve this, we address the challenge through three primary dimensions. (i) We integrate a lightweight intermediate-conditioning mechanism into the DiT architecture. By employing an Adaptive Tuning strategy that effectively leverages base training data, we unlock robust arbitrary-frame control capabilities. (ii) To enhance visual fidelity and cinematic expressiveness, we curate a high-quality dataset and implement a Visual Expression SFT stage. In addressing critical issues such as subject motion rationality and transition smoothness, we apply a Tailored DPO scheme, which significantly improves the success rate and usability of the generated content. (iii) To facilitate the production of extended sequences, we design a Segment-wise Auto-Regressive (SAR) inference strategy that operates in a memory-efficient manner. Extensive experiments demonstrate that our approach achieves visually striking and seamlessly coherent one-shot effects while maintaining computational efficiency, empowering users to transform fragmented visual materials into vivid, cohesive one-shot cinematic experiences.
Model Inversion Attacks: A Survey of Approaches and Countermeasures
Nov 15, 2024The success of deep neural networks has driven numerous research studies and applications from Euclidean to non-Euclidean data. However, there are increasing concerns about privacy leakage, as these networks rely on processing private data. Recently, a new type of privacy attack, the model inversion attacks (MIAs), aims to extract sensitive features of private data for training by abusing access to a well-trained model. The effectiveness of MIAs has been demonstrated in various domains, including images, texts, and graphs. These attacks highlight the vulnerability of neural networks and raise awareness about the risk of privacy leakage within the research community. Despite the significance, there is a lack of systematic studies that provide a comprehensive overview and deeper insights into MIAs across different domains. This survey aims to summarize up-to-date MIA methods in both attacks and defenses, highlighting their contributions and limitations, underlying modeling principles, optimization challenges, and future directions. We hope this survey bridges the gap in the literature and facilitates future research in this critical area. Besides, we are maintaining a repository to keep track of relevant research at https://github.com/AndrewZhou924/Awesome-model-inversion-attack.
Self-Calibrated Tuning of Vision-Language Models for Out-of-Distribution Detection
Nov 05, 2024
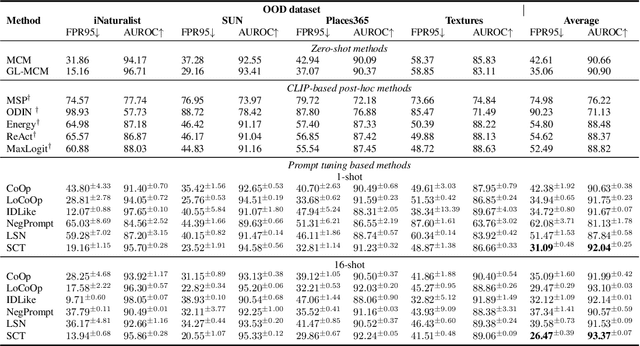
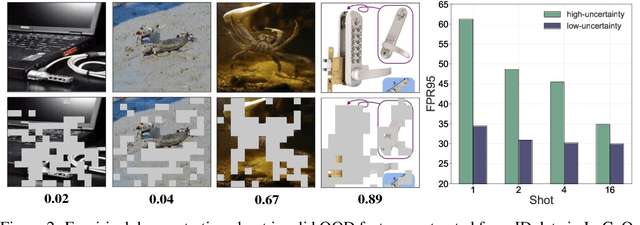
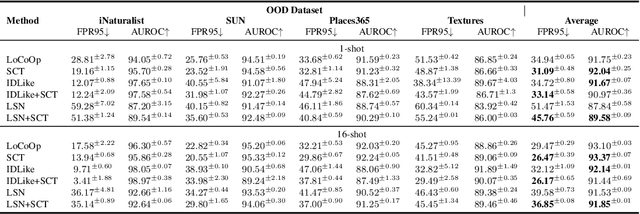
Out-of-distribution (OOD) detection is crucial for deploying reliable machine learning models in open-world applications. Recent advances in CLIP-based OOD detection have shown promising results via regularizing prompt tuning with OOD features extracted from ID data. However, the irrelevant context mined from ID data can be spurious due to the inaccurate foreground-background decomposition, thus limiting the OOD detection performance. In this work, we propose a novel framework, namely, Self-Calibrated Tuning (SCT), to mitigate this problem for effective OOD detection with only the given few-shot ID data. Specifically, SCT introduces modulating factors respectively on the two components of the original learning objective. It adaptively directs the optimization process between the two tasks during training on data with different prediction uncertainty to calibrate the influence of OOD regularization, which is compatible with many prompt tuning based OOD detection methods. Extensive experiments and analyses have been conducted to characterize and demonstrate the effectiveness of the proposed SCT. The code is publicly available.
Can Language Models Perform Robust Reasoning in Chain-of-thought Prompting with Noisy Rationales?
Oct 31, 2024

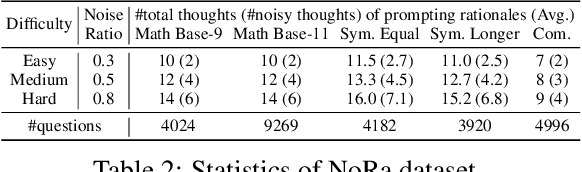
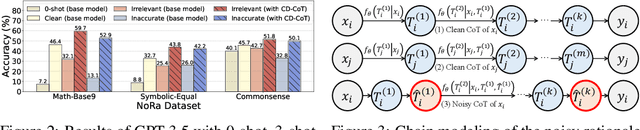
This paper investigates an under-explored challenge in large language models (LLMs): chain-of-thought prompting with noisy rationales, which include irrelevant or inaccurate reasoning thoughts within examples used for in-context learning. We construct NoRa dataset that is tailored to evaluate the robustness of reasoning in the presence of noisy rationales. Our findings on NoRa dataset reveal a prevalent vulnerability to such noise among current LLMs, with existing robust methods like self-correction and self-consistency showing limited efficacy. Notably, compared to prompting with clean rationales, base LLM drops by 1.4%-19.8% in accuracy with irrelevant thoughts and more drastically by 2.2%-40.4% with inaccurate thoughts. Addressing this challenge necessitates external supervision that should be accessible in practice. Here, we propose the method of contrastive denoising with noisy chain-of-thought (CD-CoT). It enhances LLMs' denoising-reasoning capabilities by contrasting noisy rationales with only one clean rationale, which can be the minimal requirement for denoising-purpose prompting. This method follows a principle of exploration and exploitation: (1) rephrasing and selecting rationales in the input space to achieve explicit denoising and (2) exploring diverse reasoning paths and voting on answers in the output space. Empirically, CD-CoT demonstrates an average improvement of 17.8% in accuracy over the base model and shows significantly stronger denoising capabilities than baseline methods. The source code is publicly available at: https://github.com/tmlr-group/NoisyRationales.
What If the Input is Expanded in OOD Detection?
Oct 24, 2024



Out-of-distribution (OOD) detection aims to identify OOD inputs from unknown classes, which is important for the reliable deployment of machine learning models in the open world. Various scoring functions are proposed to distinguish it from in-distribution (ID) data. However, existing methods generally focus on excavating the discriminative information from a single input, which implicitly limits its representation dimension. In this work, we introduce a novel perspective, i.e., employing different common corruptions on the input space, to expand that. We reveal an interesting phenomenon termed confidence mutation, where the confidence of OOD data can decrease significantly under the corruptions, while the ID data shows a higher confidence expectation considering the resistance of semantic features. Based on that, we formalize a new scoring method, namely, Confidence aVerage (CoVer), which can capture the dynamic differences by simply averaging the scores obtained from different corrupted inputs and the original ones, making the OOD and ID distributions more separable in detection tasks. Extensive experiments and analyses have been conducted to understand and verify the effectiveness of CoVer. The code is publicly available at: https://github.com/tmlr-group/CoVer.
Unlearning with Control: Assessing Real-world Utility for Large Language Model Unlearning
Jun 13, 2024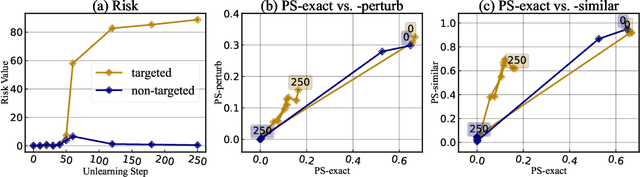

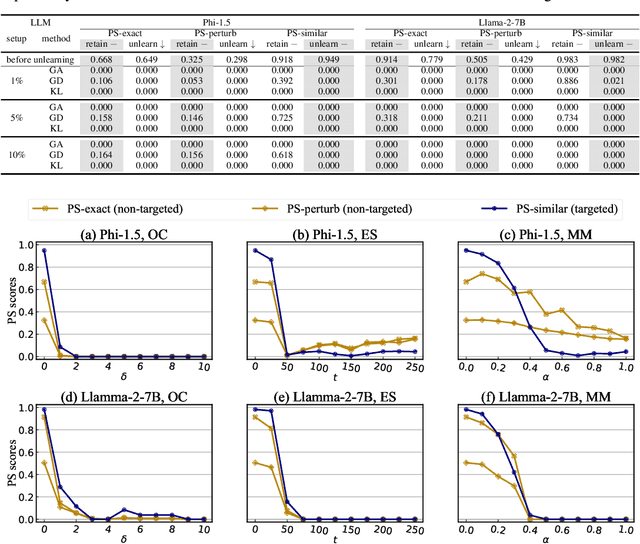
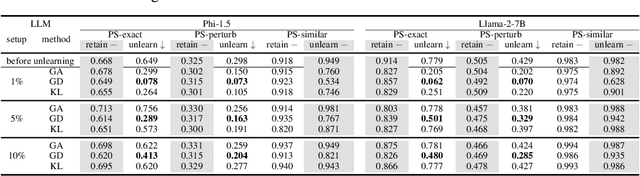
The compelling goal of eradicating undesirable data behaviors, while preserving usual model functioning, underscores the significance of machine unlearning within the domain of large language models (LLMs). Recent research has begun to approach LLM unlearning via gradient ascent (GA) -- increasing the prediction risk for those training strings targeted to be unlearned, thereby erasing their parameterized responses. Despite their simplicity and efficiency, we suggest that GA-based methods face the propensity towards excessive unlearning, resulting in various undesirable model behaviors, such as catastrophic forgetting, that diminish their practical utility. In this paper, we suggest a set of metrics that can capture multiple facets of real-world utility and propose several controlling methods that can regulate the extent of excessive unlearning. Accordingly, we suggest a general framework to better reflect the practical efficacy of various unlearning methods -- we begin by controlling the unlearning procedures/unlearned models such that no excessive unlearning occurs and follow by the evaluation for unlearning efficacy. Our experimental analysis on established benchmarks revealed that GA-based methods are far from perfect in practice, as strong unlearning is at the high cost of hindering the model utility. We conclude that there is still a long way towards practical and effective LLM unlearning, and more efforts are required in this field.
Decoupling the Class Label and the Target Concept in Machine Unlearning
Jun 12, 2024



Machine unlearning as an emerging research topic for data regulations, aims to adjust a trained model to approximate a retrained one that excludes a portion of training data. Previous studies showed that class-wise unlearning is successful in forgetting the knowledge of a target class, through gradient ascent on the forgetting data or fine-tuning with the remaining data. However, while these methods are useful, they are insufficient as the class label and the target concept are often considered to coincide. In this work, we decouple them by considering the label domain mismatch and investigate three problems beyond the conventional all matched forgetting, e.g., target mismatch, model mismatch, and data mismatch forgetting. We systematically analyze the new challenges in restrictively forgetting the target concept and also reveal crucial forgetting dynamics in the representation level to realize these tasks. Based on that, we propose a general framework, namely, TARget-aware Forgetting (TARF). It enables the additional tasks to actively forget the target concept while maintaining the rest part, by simultaneously conducting annealed gradient ascent on the forgetting data and selected gradient descent on the hard-to-affect remaining data. Empirically, various experiments under the newly introduced settings are conducted to demonstrate the effectiveness of our TARF.
DeepInception: Hypnotize Large Language Model to Be Jailbreaker
Nov 06, 2023Despite remarkable success in various applications, large language models (LLMs) are vulnerable to adversarial jailbreaks that make the safety guardrails void. However, previous studies for jailbreaks usually resort to brute-force optimization or extrapolations of a high computation cost, which might not be practical or effective. In this paper, inspired by the Milgram experiment that individuals can harm another person if they are told to do so by an authoritative figure, we disclose a lightweight method, termed as DeepInception, which can easily hypnotize LLM to be a jailbreaker and unlock its misusing risks. Specifically, DeepInception leverages the personification ability of LLM to construct a novel nested scene to behave, which realizes an adaptive way to escape the usage control in a normal scenario and provides the possibility for further direct jailbreaks. Empirically, we conduct comprehensive experiments to show its efficacy. Our DeepInception can achieve competitive jailbreak success rates with previous counterparts and realize a continuous jailbreak in subsequent interactions, which reveals the critical weakness of self-losing on both open/closed-source LLMs like Falcon, Vicuna, Llama-2, and GPT-3.5/4/4V. Our investigation appeals that people should pay more attention to the safety aspects of LLMs and a stronger defense against their misuse risks. The code is publicly available at: https://github.com/tmlr-group/DeepInception.
Diversified Outlier Exposure for Out-of-Distribution Detection via Informative Extrapolation
Oct 26, 2023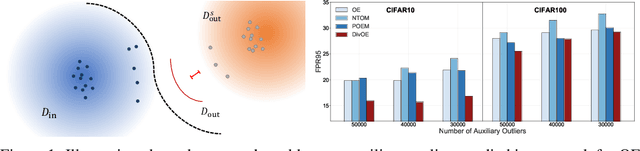
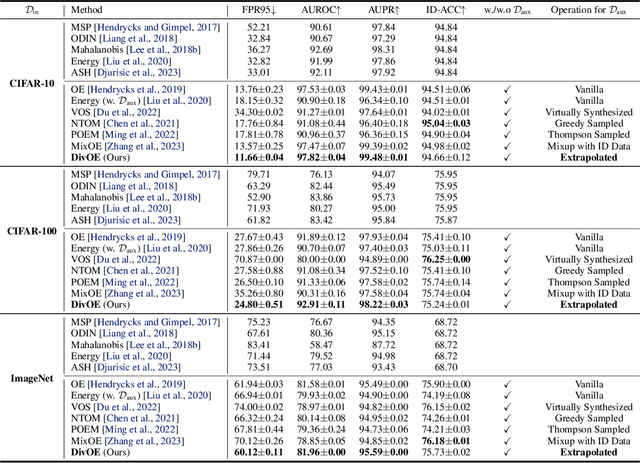
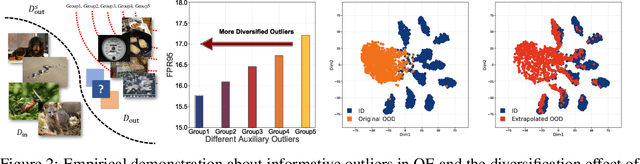
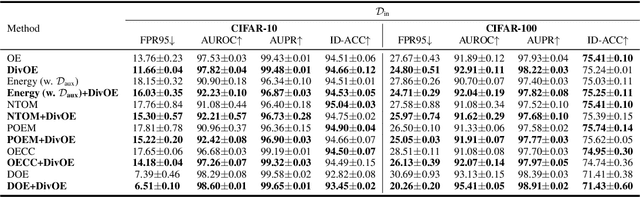
Out-of-distribution (OOD) detection is important for deploying reliable machine learning models on real-world applications. Recent advances in outlier exposure have shown promising results on OOD detection via fine-tuning model with informatively sampled auxiliary outliers. However, previous methods assume that the collected outliers can be sufficiently large and representative to cover the boundary between ID and OOD data, which might be impractical and challenging. In this work, we propose a novel framework, namely, Diversified Outlier Exposure (DivOE), for effective OOD detection via informative extrapolation based on the given auxiliary outliers. Specifically, DivOE introduces a new learning objective, which diversifies the auxiliary distribution by explicitly synthesizing more informative outliers for extrapolation during training. It leverages a multi-step optimization method to generate novel outliers beyond the original ones, which is compatible with many variants of outlier exposure. Extensive experiments and analyses have been conducted to characterize and demonstrate the effectiveness of the proposed DivOE. The code is publicly available at: https://github.com/tmlr-group/DivOE.