 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQiMeng-PRepair: Precise Code Repair via Edit-Aware Reward Optimization
Apr 07, 2026Large Language Models (LLMs) achieve strong program repair performance but often suffer from over-editing, where excessive modifications overwrite correct code and hinder bug localization. We systematically quantify its impact and introduce precise repair task, which maximizes reuse of correct code while fixing only buggy parts. Building on this insight, we propose PRepair, a framework that mitigates over-editing and improves repair accuracy. PRepair has two components: Self-Breaking, which generates diverse buggy programs via controlled bug injection and min-max sampling, and Self-Repairing, which trains models with Edit-Aware Group Relative Policy Optimization (EA-GRPO) using an edit-aware reward to encourage minimal yet correct edits. Experiments show that PRepair improves repair precision by up to 31.4% under $\mathrm{fix}_1@1$, a metric that jointly considers repair correctness and extent, and significantly increases decoding throughput when combined with speculative editing, demonstrating its potential for precise and practical code repair.
Model Inversion Attacks: A Survey of Approaches and Countermeasures
Nov 15, 2024The success of deep neural networks has driven numerous research studies and applications from Euclidean to non-Euclidean data. However, there are increasing concerns about privacy leakage, as these networks rely on processing private data. Recently, a new type of privacy attack, the model inversion attacks (MIAs), aims to extract sensitive features of private data for training by abusing access to a well-trained model. The effectiveness of MIAs has been demonstrated in various domains, including images, texts, and graphs. These attacks highlight the vulnerability of neural networks and raise awareness about the risk of privacy leakage within the research community. Despite the significance, there is a lack of systematic studies that provide a comprehensive overview and deeper insights into MIAs across different domains. This survey aims to summarize up-to-date MIA methods in both attacks and defenses, highlighting their contributions and limitations, underlying modeling principles, optimization challenges, and future directions. We hope this survey bridges the gap in the literature and facilitates future research in this critical area. Besides, we are maintaining a repository to keep track of relevant research at https://github.com/AndrewZhou924/Awesome-model-inversion-attack.
Bilateral Dependency Optimization: Defending Against Model-inversion Attacks
Jun 18, 2022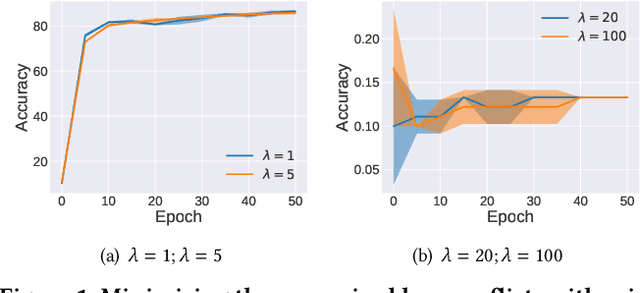
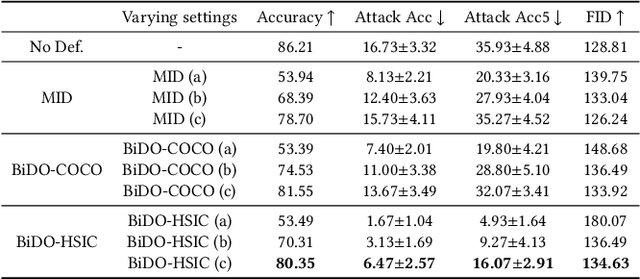
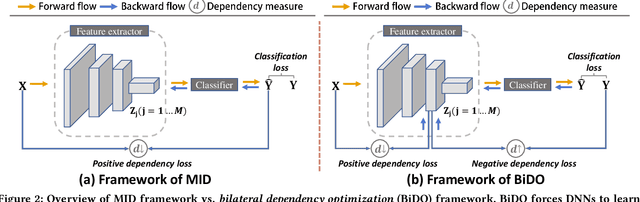
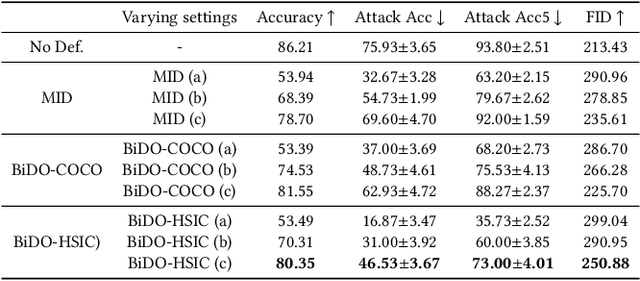
Through using only a well-trained classifier, model-inversion (MI) attacks can recover the data used for training the classifier, leading to the privacy leakage of the training data. To defend against MI attacks, previous work utilizes a unilateral dependency optimization strategy, i.e., minimizing the dependency between inputs (i.e., features) and outputs (i.e., labels) during training the classifier. However, such a minimization process conflicts with minimizing the supervised loss that aims to maximize the dependency between inputs and outputs, causing an explicit trade-off between model robustness against MI attacks and model utility on classification tasks. In this paper, we aim to minimize the dependency between the latent representations and the inputs while maximizing the dependency between latent representations and the outputs, named a bilateral dependency optimization (BiDO) strategy. In particular, we use the dependency constraints as a universally applicable regularizer in addition to commonly used losses for deep neural networks (e.g., cross-entropy), which can be instantiated with appropriate dependency criteria according to different tasks. To verify the efficacy of our strategy, we propose two implementations of BiDO, by using two different dependency measures: BiDO with constrained covariance (BiDO-COCO) and BiDO with Hilbert-Schmidt Independence Criterion (BiDO-HSIC). Experiments show that BiDO achieves the state-of-the-art defense performance for a variety of datasets, classifiers, and MI attacks while suffering a minor classification-accuracy drop compared to the well-trained classifier with no defense, which lights up a novel road to defend against MI attacks.
* Accepted to KDD 2022 (Research Track)