 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRewardFlow: Topology-Aware Reward Propagation on State Graphs for Agentic RL with Large Language Models
Mar 19, 2026Reinforcement learning (RL) holds significant promise for enhancing the agentic reasoning capabilities of large language models (LLMs) with external environments. However, the inherent sparsity of terminal rewards hinders fine-grained, state-level optimization. Although process reward modeling offers a promising alternative, training dedicated reward models often entails substantial computational costs and scaling difficulties. To address these challenges, we introduce RewardFlow, a lightweight method for estimating state-level rewards tailored to agentic reasoning tasks. RewardFlow leverages the intrinsic topological structure of states within reasoning trajectories by constructing state graphs. This enables an analysis of state-wise contributions to success, followed by topology-aware graph propagation to quantify contributions and yield objective, state-level rewards. When integrated as dense rewards for RL optimization, RewardFlow substantially outperforms prior RL baselines across four agentic reasoning benchmarks, demonstrating superior performance, robustness, and training efficiency. The implementation of RewardFlow is publicly available at https://github.com/tmlr-group/RewardFlow.
From Passive to Active Reasoning: Can Large Language Models Ask the Right Questions under Incomplete Information?
Jun 09, 2025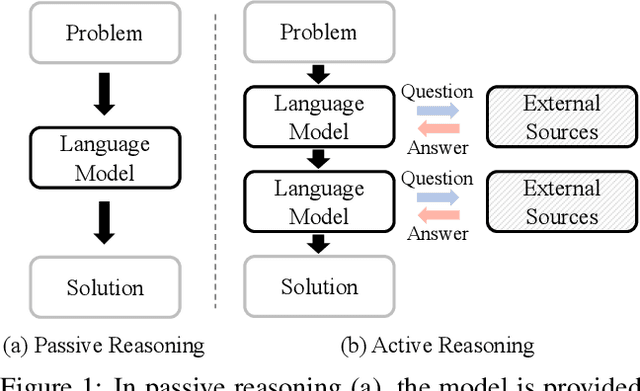
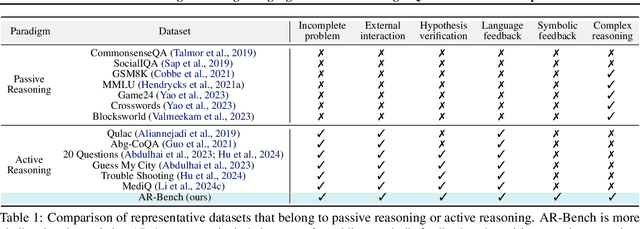
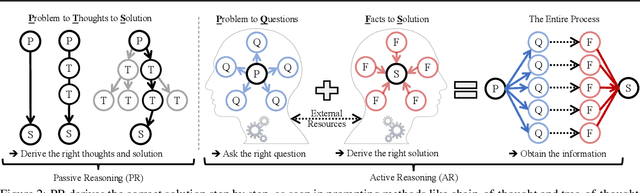

While existing benchmarks probe the reasoning abilities of large language models (LLMs) across diverse domains, they predominantly assess passive reasoning, providing models with all the information needed to reach a solution. By contrast, active reasoning-where an LLM must interact with external systems to acquire missing evidence or data-has received little systematic attention. To address this shortfall, we present AR-Bench, a novel benchmark designed explicitly to evaluate an LLM's active reasoning skills. AR-Bench comprises three task families-detective cases, situation puzzles, and guessing numbers-that together simulate real-world, agentic scenarios and measure performance across commonsense, logical, and symbolic reasoning challenges. Empirical evaluation on AR-Bench demonstrates that contemporary LLMs exhibit pronounced difficulties with active reasoning: they frequently fail to acquire or leverage the information needed to solve tasks. This gap highlights a stark divergence between their passive and active reasoning abilities. Moreover, ablation studies indicate that even advanced strategies, such as tree-based searching or post-training approaches, yield only modest gains and fall short of the levels required for real-world deployment. Collectively, these findings highlight the critical need to advance methodology for active reasoning, e.g., incorporating interactive learning, real-time feedback loops, and environment-aware objectives for training. The benchmark is publicly available at: https://github.com/tmlr-group/AR-Bench.
From Debate to Equilibrium: Belief-Driven Multi-Agent LLM Reasoning via Bayesian Nash Equilibrium
Jun 09, 2025Multi-agent frameworks can substantially boost the reasoning power of large language models (LLMs), but they typically incur heavy computational costs and lack convergence guarantees. To overcome these challenges, we recast multi-LLM coordination as an incomplete-information game and seek a Bayesian Nash equilibrium (BNE), in which each agent optimally responds to its probabilistic beliefs about the strategies of others. We introduce Efficient Coordination via Nash Equilibrium (ECON), a hierarchical reinforcement-learning paradigm that marries distributed reasoning with centralized final output. Under ECON, each LLM independently selects responses that maximize its expected reward, conditioned on its beliefs about co-agents, without requiring costly inter-agent exchanges. We mathematically prove that ECON attains a markedly tighter regret bound than non-equilibrium multi-agent schemes. Empirically, ECON outperforms existing multi-LLM approaches by 11.2% on average across six benchmarks spanning complex reasoning and planning tasks. Further experiments demonstrate ECON's ability to flexibly incorporate additional models, confirming its scalability and paving the way toward larger, more powerful multi-LLM ensembles. The code is publicly available at: https://github.com/tmlr-group/ECON.
SATBench: Benchmarking LLMs' Logical Reasoning via Automated Puzzle Generation from SAT Formulas
May 20, 2025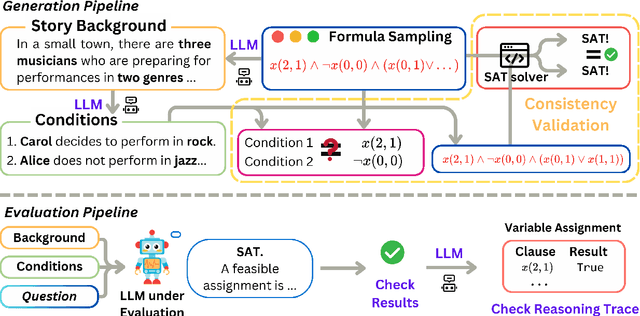



We introduce SATBench, a benchmark for evaluating the logical reasoning capabilities of large language models (LLMs) through logical puzzles derived from Boolean satisfiability (SAT) problems. Unlike prior work that focuses on inference rule-based reasoning, which often involves deducing conclusions from a set of premises, our approach leverages the search-based nature of SAT problems, where the objective is to find a solution that fulfills a specified set of logical constraints. Each instance in SATBench is generated from a SAT formula, then translated into a story context and conditions using LLMs. The generation process is fully automated and allows for adjustable difficulty by varying the number of clauses. All 2100 puzzles are validated through both LLM-assisted and solver-based consistency checks, with human validation on a subset. Experimental results show that even the strongest model, o4-mini, achieves only 65.0% accuracy on hard UNSAT problems, close to the random baseline of 50%. SATBench exposes fundamental limitations in the search-based logical reasoning abilities of current LLMs and provides a scalable testbed for future research in logical reasoning.
Landscape of Thoughts: Visualizing the Reasoning Process of Large Language Models
Mar 28, 2025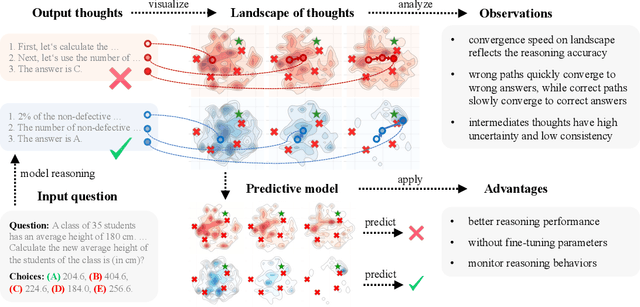
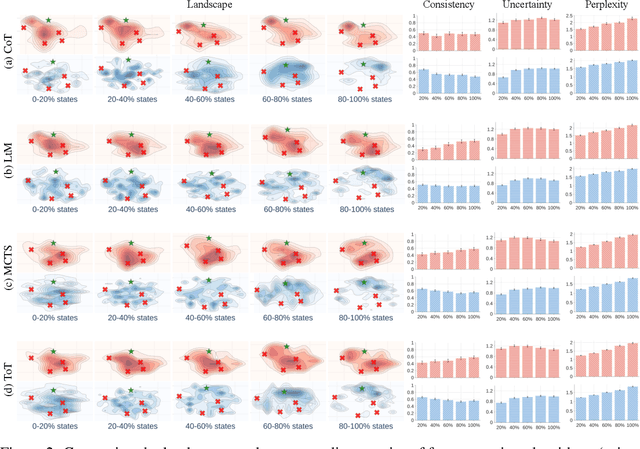
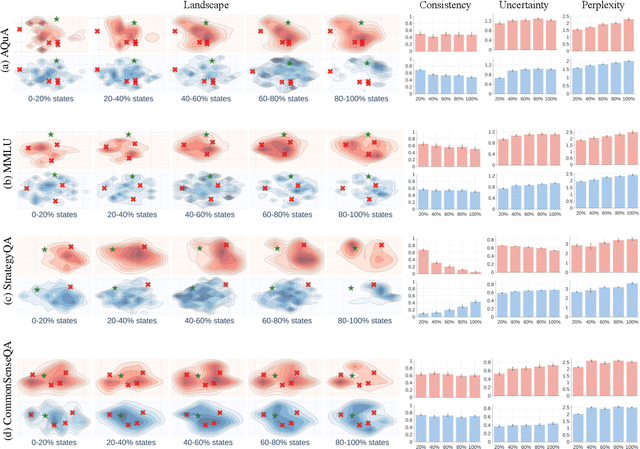
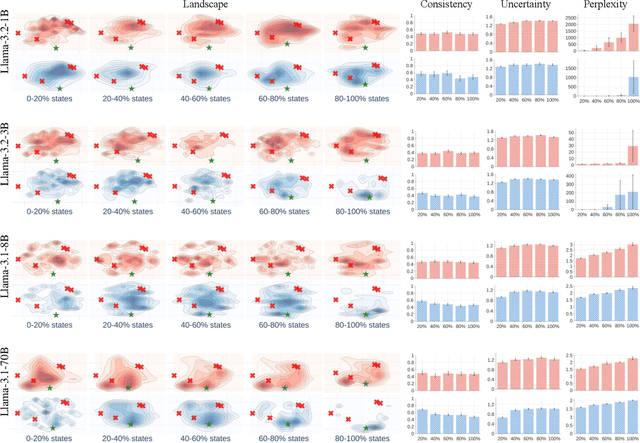
Numerous applications of large language models (LLMs) rely on their ability to perform step-by-step reasoning. However, the reasoning behavior of LLMs remains poorly understood, posing challenges to research, development, and safety. To address this gap, we introduce landscape of thoughts-the first visualization tool for users to inspect the reasoning paths of chain-of-thought and its derivatives on any multi-choice dataset. Specifically, we represent the states in a reasoning path as feature vectors that quantify their distances to all answer choices. These features are then visualized in two-dimensional plots using t-SNE. Qualitative and quantitative analysis with the landscape of thoughts effectively distinguishes between strong and weak models, correct and incorrect answers, as well as different reasoning tasks. It also uncovers undesirable reasoning patterns, such as low consistency and high uncertainty. Additionally, users can adapt our tool to a model that predicts the property they observe. We showcase this advantage by adapting our tool to a lightweight verifier that evaluates the correctness of reasoning paths. The code is publicly available at: https://github.com/tmlr-group/landscape-of-thoughts.
Rethinking LLM Unlearning Objectives: A Gradient Perspective and Go Beyond
Feb 26, 2025



Large language models (LLMs) should undergo rigorous audits to identify potential risks, such as copyright and privacy infringements. Once these risks emerge, timely updates are crucial to remove undesirable responses, ensuring legal and safe model usage. It has spurred recent research into LLM unlearning, focusing on erasing targeted undesirable knowledge without compromising the integrity of other, non-targeted responses. Existing studies have introduced various unlearning objectives to pursue LLM unlearning without necessitating complete retraining. However, each of these objectives has unique properties, and no unified framework is currently available to comprehend them thoroughly. To fill the gap, we propose a toolkit of the gradient effect (G-effect), quantifying the impacts of unlearning objectives on model performance from a gradient perspective. A notable advantage is its broad ability to detail the unlearning impacts from various aspects across instances, updating steps, and LLM layers. Accordingly, the G-effect offers new insights into identifying drawbacks of existing unlearning objectives, further motivating us to explore a series of new solutions for their mitigation and improvements. Finally, we outline promising directions that merit further studies, aiming at contributing to the community to advance this important field.
Noisy Test-Time Adaptation in Vision-Language Models
Feb 20, 2025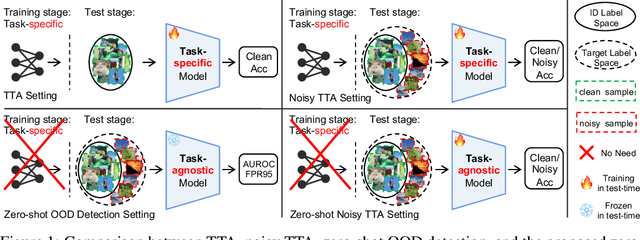
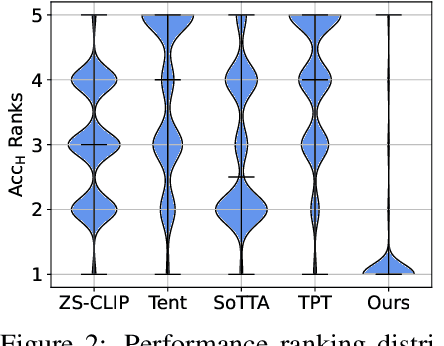
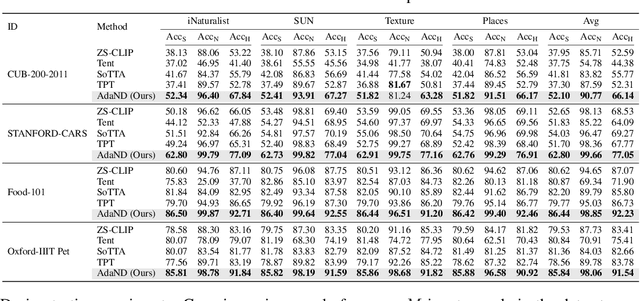
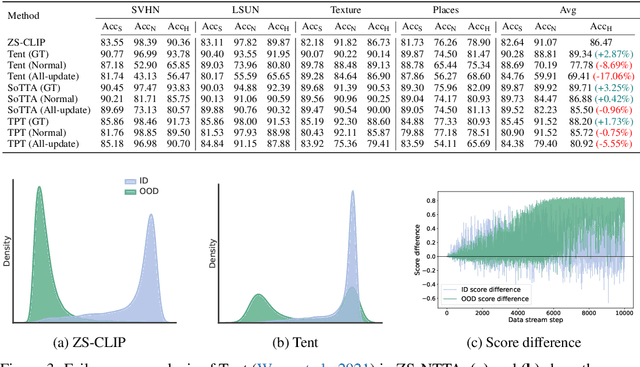
Test-time adaptation (TTA) aims to address distribution shifts between source and target data by relying solely on target data during testing. In open-world scenarios, models often encounter noisy samples, i.e., samples outside the in-distribution (ID) label space. Leveraging the zero-shot capability of pre-trained vision-language models (VLMs), this paper introduces Zero-Shot Noisy TTA (ZS-NTTA), focusing on adapting the model to target data with noisy samples during test-time in a zero-shot manner. We find existing TTA methods underperform under ZS-NTTA, often lagging behind even the frozen model. We conduct comprehensive experiments to analyze this phenomenon, revealing that the negative impact of unfiltered noisy data outweighs the benefits of clean data during model updating. Also, adapting a classifier for ID classification and noise detection hampers both sub-tasks. Built on this, we propose a framework that decouples the classifier and detector, focusing on developing an individual detector while keeping the classifier frozen. Technically, we introduce the Adaptive Noise Detector (AdaND), which utilizes the frozen model's outputs as pseudo-labels to train a noise detector. To handle clean data streams, we further inject Gaussian noise during adaptation, preventing the detector from misclassifying clean samples as noisy. Beyond the ZS-NTTA, AdaND can also improve the zero-shot out-of-distribution (ZS-OOD) detection ability of VLMs. Experiments show that AdaND outperforms in both ZS-NTTA and ZS-OOD detection. On ImageNet, AdaND achieves a notable improvement of $8.32\%$ in harmonic mean accuracy ($\text{Acc}_\text{H}$) for ZS-NTTA and $9.40\%$ in FPR95 for ZS-OOD detection, compared to SOTA methods. Importantly, AdaND is computationally efficient and comparable to the model-frozen method. The code is publicly available at: https://github.com/tmlr-group/ZS-NTTA.
Eliciting Causal Abilities in Large Language Models for Reasoning Tasks
Dec 19, 2024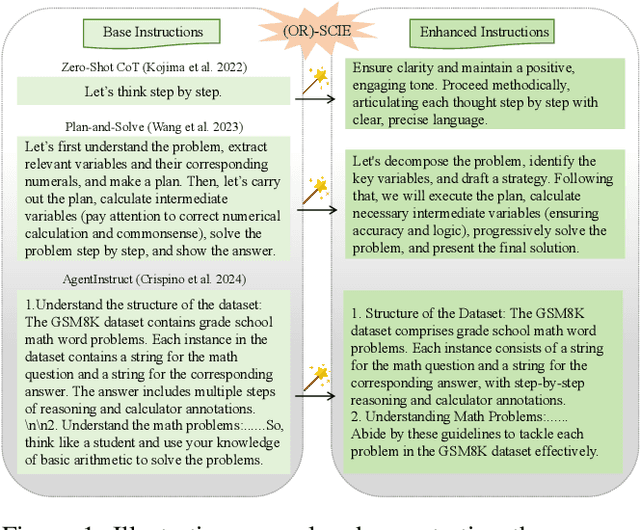
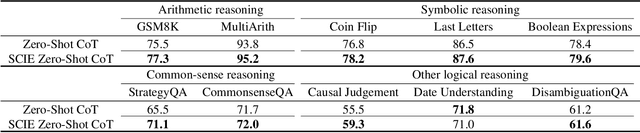
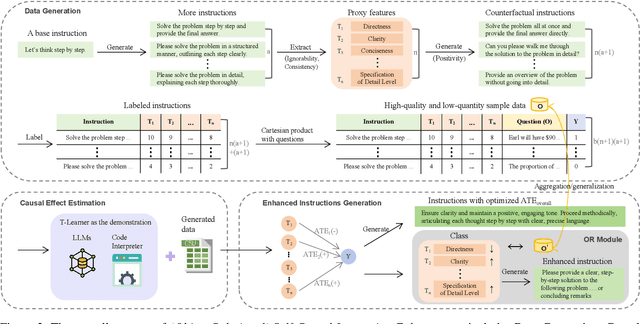

Prompt optimization automatically refines prompting expressions, unlocking the full potential of LLMs in downstream tasks. However, current prompt optimization methods are costly to train and lack sufficient interpretability. This paper proposes enhancing LLMs' reasoning performance by eliciting their causal inference ability from prompting instructions to correct answers. Specifically, we introduce the Self-Causal Instruction Enhancement (SCIE) method, which enables LLMs to generate high-quality, low-quantity observational data, then estimates the causal effect based on these data, and ultimately generates instructions with the optimized causal effect. In SCIE, the instructions are treated as the treatment, and textual features are used to process natural language, establishing causal relationships through treatments between instructions and downstream tasks. Additionally, we propose applying Object-Relational (OR) principles, where the uncovered causal relationships are treated as the inheritable class across task objects, ensuring low-cost reusability. Extensive experiments demonstrate that our method effectively generates instructions that enhance reasoning performance with reduced training cost of prompts, leveraging interpretable textual features to provide actionable insights.
Physics Reasoner: Knowledge-Augmented Reasoning for Solving Physics Problems with Large Language Models
Dec 18, 2024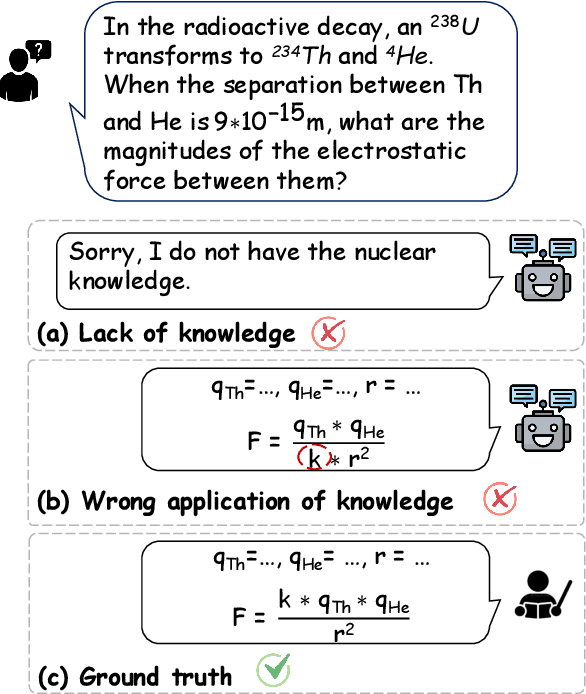
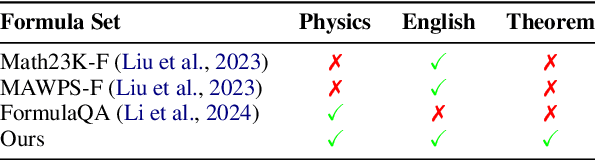
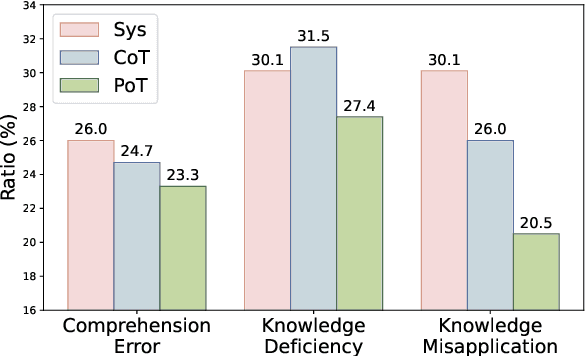

Physics problems constitute a significant aspect of reasoning, necessitating complicated reasoning ability and abundant physics knowledge. However, existing large language models (LLMs) frequently fail due to a lack of knowledge or incorrect knowledge application. To mitigate these issues, we propose Physics Reasoner, a knowledge-augmented framework to solve physics problems with LLMs. Specifically, the proposed framework constructs a comprehensive formula set to provide explicit physics knowledge and utilizes checklists containing detailed instructions to guide effective knowledge application. Namely, given a physics problem, Physics Reasoner solves it through three stages: problem analysis, formula retrieval, and guided reasoning. During the process, checklists are employed to enhance LLMs' self-improvement in the analysis and reasoning stages. Empirically, Physics Reasoner mitigates the issues of insufficient knowledge and incorrect application, achieving state-of-the-art performance on SciBench with an average accuracy improvement of 5.8%.
Model Inversion Attacks: A Survey of Approaches and Countermeasures
Nov 15, 2024The success of deep neural networks has driven numerous research studies and applications from Euclidean to non-Euclidean data. However, there are increasing concerns about privacy leakage, as these networks rely on processing private data. Recently, a new type of privacy attack, the model inversion attacks (MIAs), aims to extract sensitive features of private data for training by abusing access to a well-trained model. The effectiveness of MIAs has been demonstrated in various domains, including images, texts, and graphs. These attacks highlight the vulnerability of neural networks and raise awareness about the risk of privacy leakage within the research community. Despite the significance, there is a lack of systematic studies that provide a comprehensive overview and deeper insights into MIAs across different domains. This survey aims to summarize up-to-date MIA methods in both attacks and defenses, highlighting their contributions and limitations, underlying modeling principles, optimization challenges, and future directions. We hope this survey bridges the gap in the literature and facilitates future research in this critical area. Besides, we are maintaining a repository to keep track of relevant research at https://github.com/AndrewZhou924/Awesome-model-inversion-attack.