 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTriSpec: Ternary Speculative Decoding via Lightweight Proxy Verification
Jan 30, 2026Inference efficiency in Large Language Models (LLMs) is fundamentally limited by their serial, autoregressive generation, especially as reasoning becomes a key capability and response sequences grow longer. Speculative decoding (SD) offers a powerful solution, providing significant speed-ups through its lightweight drafting and parallel verification mechanism. While existing work has nearly saturated improvements in draft effectiveness and efficiency, this paper advances SD from a new yet critical perspective: the verification cost. We propose TriSpec, a novel ternary SD framework that, at its core, introduces a lightweight proxy to significantly reduce computational cost by approving easily verifiable draft sequences and engaging the full target model only when encountering uncertain tokens. TriSpec can be integrated with state-of-the-art SD methods like EAGLE-3 to further reduce verification costs, achieving greater acceleration. Extensive experiments on the Qwen3 and DeepSeek-R1-Distill-Qwen/LLaMA families show that TriSpec achieves up to 35\% speedup over standard SD, with up to 50\% fewer target model invocations while maintaining comparable accuracy.
Per-parameter Task Arithmetic for Unlearning in Large Language Models
Jan 29, 2026In large language model (LLM) unlearning, private information is required to be removed. Task arithmetic unlearns by subtracting a specific task vector (TV)--defined as the parameter difference between a privacy-information-tuned model and the original model. While efficient, it can cause over-forgetting by disrupting parameters essential for retaining other information. Motivated by the observation that each parameter exhibits different importance for forgetting versus retention, we propose a per-parameter task arithmetic (PerTA) mechanism to rescale the TV, allowing per-parameter adjustment. These weights quantify the relative importance of each parameter for forgetting versus retention, estimated via gradients (i.e., PerTA-grad) or the diagonal Fisher information approximation (i.e., PerTA-fisher). Moreover, we discuss the effectiveness of PerTA, extend it to a more general form, and provide further analysis. Extensive experiments demonstrate that PerTA consistently improves upon standard TV, and in many cases surpasses widely used training-based unlearning methods in both forgetting effectiveness and overall model utility. By retaining the efficiency of task arithmetic while mitigating over-forgetting, PerTA offers a principled and practical framework for LLM unlearning.
Innovator-VL: A Multimodal Large Language Model for Scientific Discovery
Jan 27, 2026We present Innovator-VL, a scientific multimodal large language model designed to advance understanding and reasoning across diverse scientific domains while maintaining excellent performance on general vision tasks. Contrary to the trend of relying on massive domain-specific pretraining and opaque pipelines, our work demonstrates that principled training design and transparent methodology can yield strong scientific intelligence with substantially reduced data requirements. (i) First, we provide a fully transparent, end-to-end reproducible training pipeline, covering data collection, cleaning, preprocessing, supervised fine-tuning, reinforcement learning, and evaluation, along with detailed optimization recipes. This facilitates systematic extension by the community. (ii) Second, Innovator-VL exhibits remarkable data efficiency, achieving competitive performance on various scientific tasks using fewer than five million curated samples without large-scale pretraining. These results highlight that effective reasoning can be achieved through principled data selection rather than indiscriminate scaling. (iii) Third, Innovator-VL demonstrates strong generalization, achieving competitive performance on general vision, multimodal reasoning, and scientific benchmarks. This indicates that scientific alignment can be integrated into a unified model without compromising general-purpose capabilities. Our practices suggest that efficient, reproducible, and high-performing scientific multimodal models can be built even without large-scale data, providing a practical foundation for future research.
Wide-In, Narrow-Out: Revokable Decoding for Efficient and Effective DLLMs
Jul 24, 2025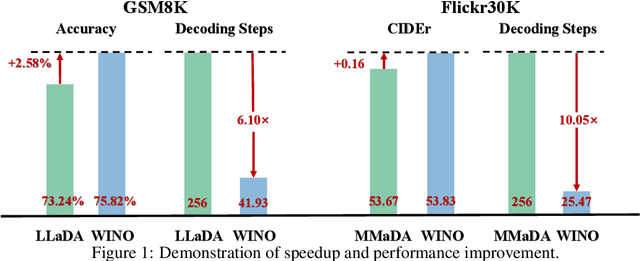
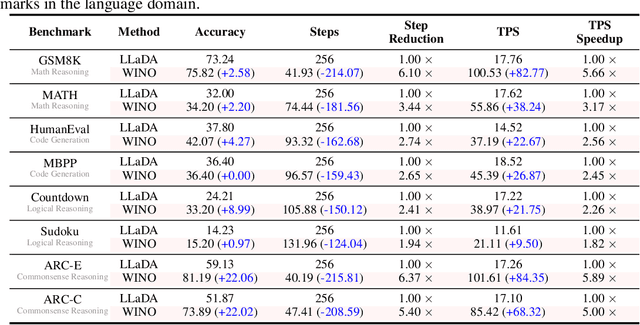
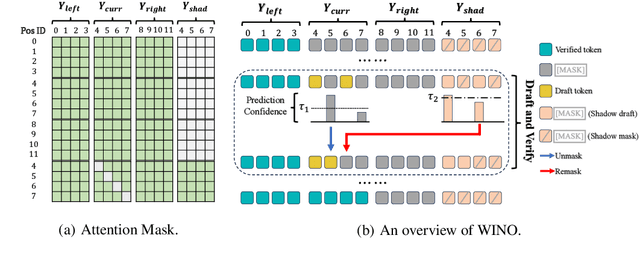
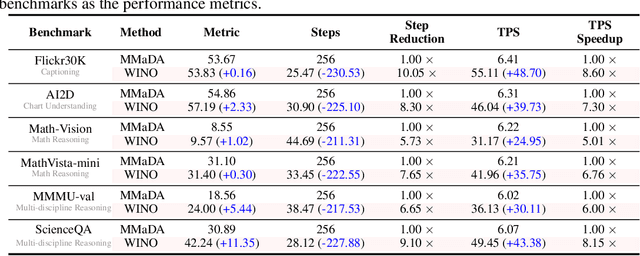
Diffusion Large Language Models (DLLMs) have emerged as a compelling alternative to Autoregressive models, designed for fast parallel generation. However, existing DLLMs are plagued by a severe quality-speed trade-off, where faster parallel decoding leads to significant performance degradation. We attribute this to the irreversibility of standard decoding in DLLMs, which is easily polarized into the wrong decoding direction along with early error context accumulation. To resolve this, we introduce Wide-In, Narrow-Out (WINO), a training-free decoding algorithm that enables revokable decoding in DLLMs. WINO employs a parallel draft-and-verify mechanism, aggressively drafting multiple tokens while simultaneously using the model's bidirectional context to verify and re-mask suspicious ones for refinement. Verified in open-source DLLMs like LLaDA and MMaDA, WINO is shown to decisively improve the quality-speed trade-off. For instance, on the GSM8K math benchmark, it accelerates inference by 6$\times$ while improving accuracy by 2.58%; on Flickr30K captioning, it achieves a 10$\times$ speedup with higher performance. More comprehensive experiments are conducted to demonstrate the superiority and provide an in-depth understanding of WINO.
Differential-informed Sample Selection Accelerates Multimodal Contrastive Learning
Jul 17, 2025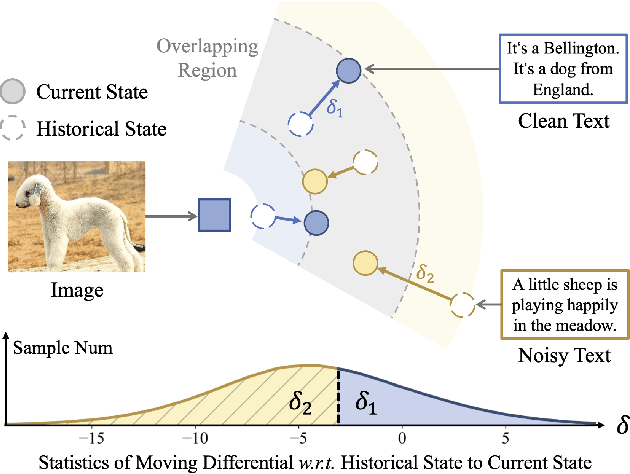
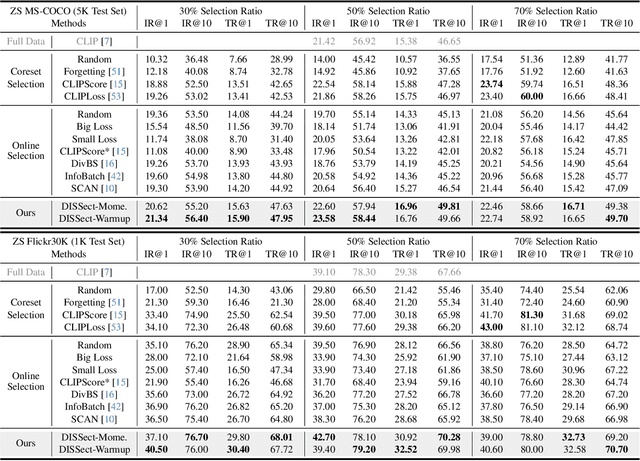
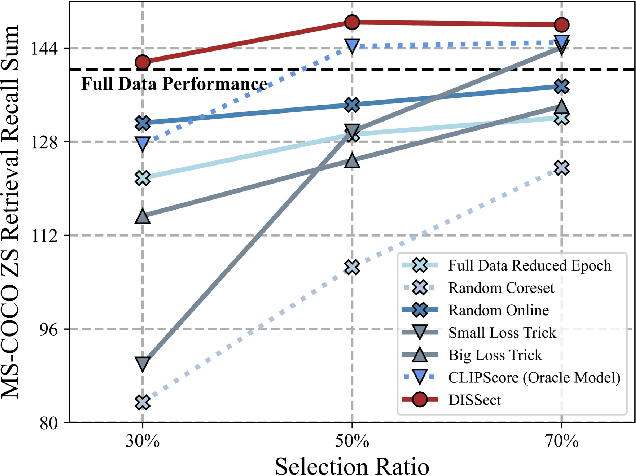
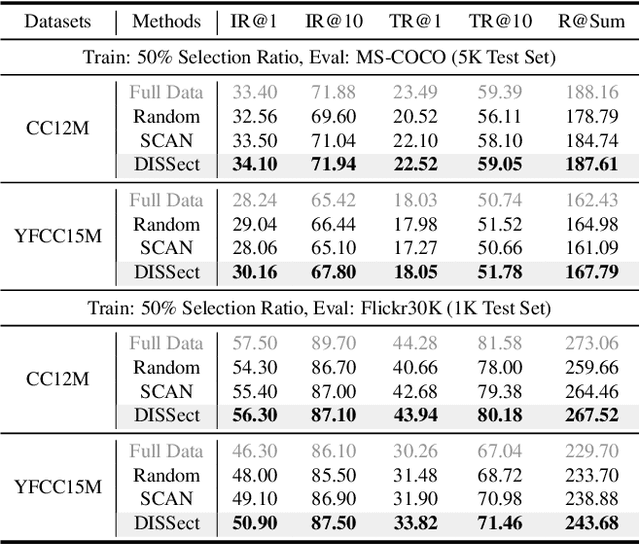
The remarkable success of contrastive-learning-based multimodal models has been greatly driven by training on ever-larger datasets with expensive compute consumption. Sample selection as an alternative efficient paradigm plays an important direction to accelerate the training process. However, recent advances on sample selection either mostly rely on an oracle model to offline select a high-quality coreset, which is limited in the cold-start scenarios, or focus on online selection based on real-time model predictions, which has not sufficiently or efficiently considered the noisy correspondence. To address this dilemma, we propose a novel Differential-Informed Sample Selection (DISSect) method, which accurately and efficiently discriminates the noisy correspondence for training acceleration. Specifically, we rethink the impact of noisy correspondence on contrastive learning and propose that the differential between the predicted correlation of the current model and that of a historical model is more informative to characterize sample quality. Based on this, we construct a robust differential-based sample selection and analyze its theoretical insights. Extensive experiments on three benchmark datasets and various downstream tasks demonstrate the consistent superiority of DISSect over current state-of-the-art methods. Source code is available at: https://github.com/MediaBrain-SJTU/DISSect.
From Passive to Active Reasoning: Can Large Language Models Ask the Right Questions under Incomplete Information?
Jun 09, 2025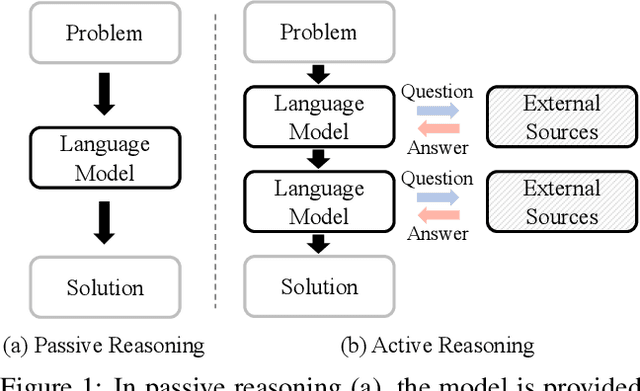
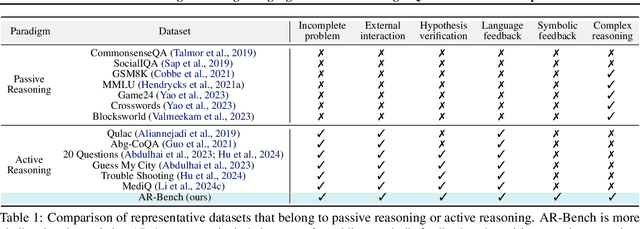
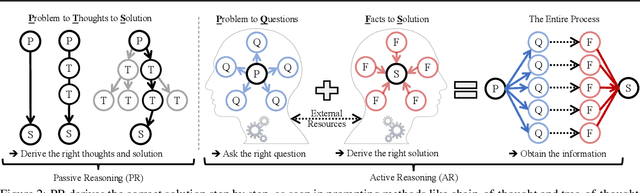

While existing benchmarks probe the reasoning abilities of large language models (LLMs) across diverse domains, they predominantly assess passive reasoning, providing models with all the information needed to reach a solution. By contrast, active reasoning-where an LLM must interact with external systems to acquire missing evidence or data-has received little systematic attention. To address this shortfall, we present AR-Bench, a novel benchmark designed explicitly to evaluate an LLM's active reasoning skills. AR-Bench comprises three task families-detective cases, situation puzzles, and guessing numbers-that together simulate real-world, agentic scenarios and measure performance across commonsense, logical, and symbolic reasoning challenges. Empirical evaluation on AR-Bench demonstrates that contemporary LLMs exhibit pronounced difficulties with active reasoning: they frequently fail to acquire or leverage the information needed to solve tasks. This gap highlights a stark divergence between their passive and active reasoning abilities. Moreover, ablation studies indicate that even advanced strategies, such as tree-based searching or post-training approaches, yield only modest gains and fall short of the levels required for real-world deployment. Collectively, these findings highlight the critical need to advance methodology for active reasoning, e.g., incorporating interactive learning, real-time feedback loops, and environment-aware objectives for training. The benchmark is publicly available at: https://github.com/tmlr-group/AR-Bench.
Learning to Instruct for Visual Instruction Tuning
Mar 28, 2025We propose LIT, an advancement of visual instruction tuning (VIT). While VIT equips Multimodal LLMs (MLLMs) with promising multimodal capabilities, the current design choices for VIT often result in overfitting and shortcut learning, potentially degrading performance. This gap arises from an overemphasis on instruction-following abilities, while neglecting the proactive understanding of visual information. Inspired by this, LIT adopts a simple yet effective approach by incorporating the loss function into both the instruction and response sequences. It seamlessly expands the training data, and regularizes the MLLMs from overly relying on language priors. Based on this merit, LIT achieves a significant relative improvement of up to 9% on comprehensive multimodal benchmarks, requiring no additional training data and incurring negligible computational overhead. Surprisingly, LIT attains exceptional fundamental visual capabilities, yielding up to an 18% improvement in captioning performance, while simultaneously alleviating hallucination in MLLMs.
Fast and Accurate Blind Flexible Docking
Feb 20, 2025Molecular docking that predicts the bound structures of small molecules (ligands) to their protein targets, plays a vital role in drug discovery. However, existing docking methods often face limitations: they either overlook crucial structural changes by assuming protein rigidity or suffer from low computational efficiency due to their reliance on generative models for structure sampling. To address these challenges, we propose FABFlex, a fast and accurate regression-based multi-task learning model designed for realistic blind flexible docking scenarios, where proteins exhibit flexibility and binding pocket sites are unknown (blind). Specifically, FABFlex's architecture comprises three specialized modules working in concert: (1) A pocket prediction module that identifies potential binding sites, addressing the challenges inherent in blind docking scenarios. (2) A ligand docking module that predicts the bound (holo) structures of ligands from their unbound (apo) states. (3) A pocket docking module that forecasts the holo structures of protein pockets from their apo conformations. Notably, FABFlex incorporates an iterative update mechanism that serves as a conduit between the ligand and pocket docking modules, enabling continuous structural refinements. This approach effectively integrates the three subtasks of blind flexible docking-pocket identification, ligand conformation prediction, and protein flexibility modeling-into a unified, coherent framework. Extensive experiments on public benchmark datasets demonstrate that FABFlex not only achieves superior effectiveness in predicting accurate binding modes but also exhibits a significant speed advantage (208 $\times$) compared to existing state-of-the-art methods. Our code is released at https://github.com/tmlr-group/FABFlex.
MetaNeRV: Meta Neural Representations for Videos with Spatial-Temporal Guidance
Jan 05, 2025



Neural Representations for Videos (NeRV) has emerged as a promising implicit neural representation (INR) approach for video analysis, which represents videos as neural networks with frame indexes as inputs. However, NeRV-based methods are time-consuming when adapting to a large number of diverse videos, as each video requires a separate NeRV model to be trained from scratch. In addition, NeRV-based methods spatially require generating a high-dimension signal (i.e., an entire image) from the input of a low-dimension timestamp, and a video typically consists of tens of frames temporally that have a minor change between adjacent frames. To improve the efficiency of video representation, we propose Meta Neural Representations for Videos, named MetaNeRV, a novel framework for fast NeRV representation for unseen videos. MetaNeRV leverages a meta-learning framework to learn an optimal parameter initialization, which serves as a good starting point for adapting to new videos. To address the unique spatial and temporal characteristics of video modality, we further introduce spatial-temporal guidance to improve the representation capabilities of MetaNeRV. Specifically, the spatial guidance with a multi-resolution loss aims to capture the information from different resolution stages, and the temporal guidance with an effective progressive learning strategy could gradually refine the number of fitted frames during the meta-learning process. Extensive experiments conducted on multiple datasets demonstrate the superiority of MetaNeRV for video representations and video compression.
LamRA: Large Multimodal Model as Your Advanced Retrieval Assistant
Dec 02, 2024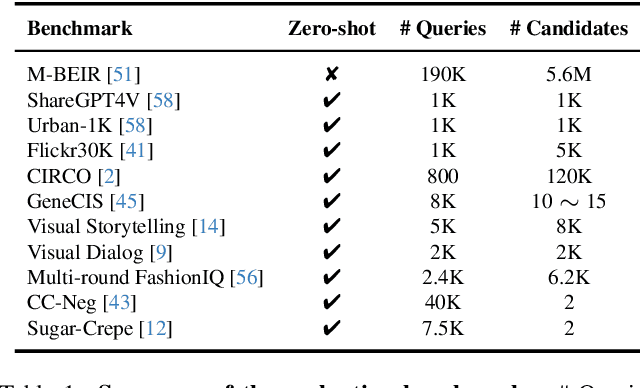
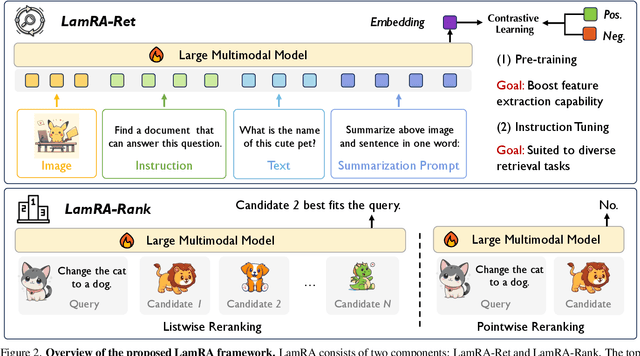
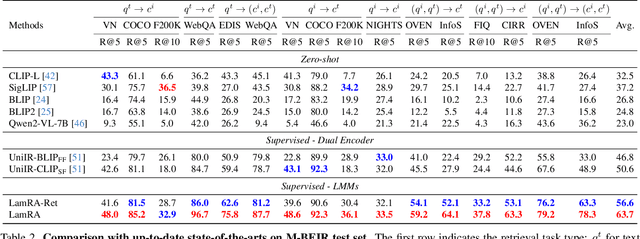
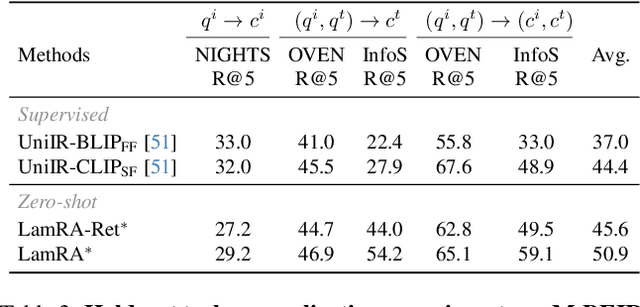
With the rapid advancement of multimodal information retrieval, increasingly complex retrieval tasks have emerged. Existing methods predominately rely on task-specific fine-tuning of vision-language models, often those trained with image-text contrastive learning. In this paper, we explore the possibility of re-purposing generative Large Multimodal Models (LMMs) for retrieval. This approach enables unifying all retrieval tasks under the same formulation and, more importantly, allows for extrapolation towards unseen retrieval tasks without additional training. Our contributions can be summarised in the following aspects: (i) We introduce LamRA, a versatile framework designed to empower LMMs with sophisticated retrieval and reranking capabilities. (ii) For retrieval, we adopt a two-stage training strategy comprising language-only pre-training and multimodal instruction tuning to progressively enhance LMM's retrieval performance. (iii) For reranking, we employ joint training for both pointwise and listwise reranking, offering two distinct ways to further boost the retrieval performance. (iv) Extensive experimental results underscore the efficacy of our method in handling more than ten retrieval tasks, demonstrating robust performance in both supervised and zero-shot settings, including scenarios involving previously unseen retrieval tasks.