 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLamRA: Large Multimodal Model as Your Advanced Retrieval Assistant
Paper and Code
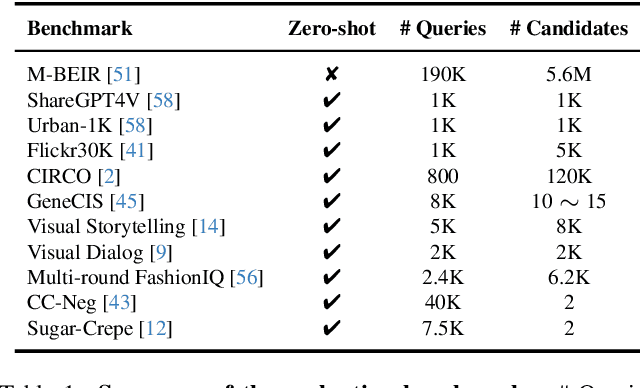
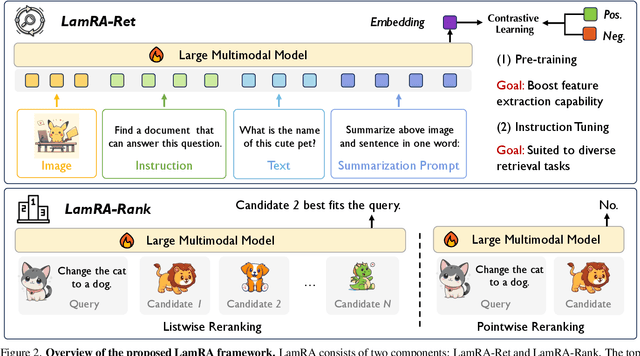
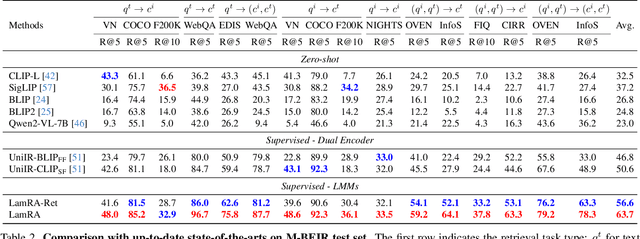
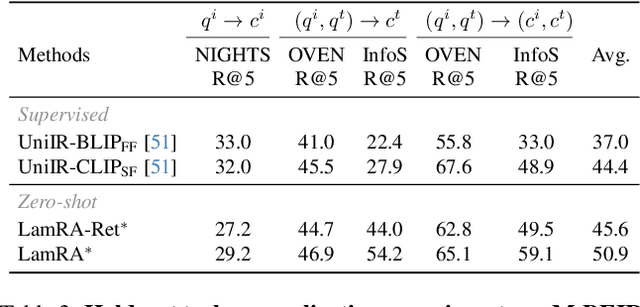
With the rapid advancement of multimodal information retrieval, increasingly complex retrieval tasks have emerged. Existing methods predominately rely on task-specific fine-tuning of vision-language models, often those trained with image-text contrastive learning. In this paper, we explore the possibility of re-purposing generative Large Multimodal Models (LMMs) for retrieval. This approach enables unifying all retrieval tasks under the same formulation and, more importantly, allows for extrapolation towards unseen retrieval tasks without additional training. Our contributions can be summarised in the following aspects: (i) We introduce LamRA, a versatile framework designed to empower LMMs with sophisticated retrieval and reranking capabilities. (ii) For retrieval, we adopt a two-stage training strategy comprising language-only pre-training and multimodal instruction tuning to progressively enhance LMM's retrieval performance. (iii) For reranking, we employ joint training for both pointwise and listwise reranking, offering two distinct ways to further boost the retrieval performance. (iv) Extensive experimental results underscore the efficacy of our method in handling more than ten retrieval tasks, demonstrating robust performance in both supervised and zero-shot settings, including scenarios involving previously unseen retrieval tasks.