 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Streaming Video Representation via Multitask Training
Apr 28, 2025
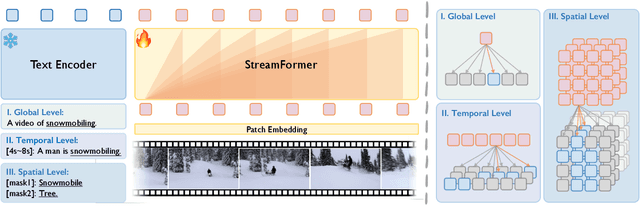
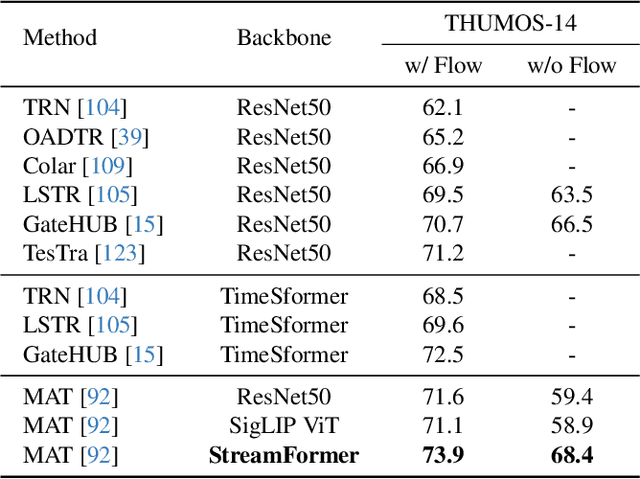
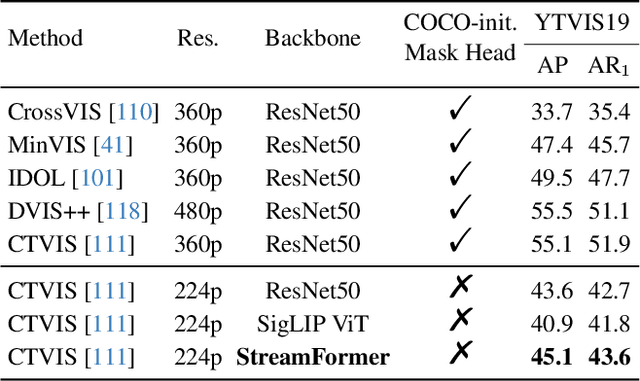
Understanding continuous video streams plays a fundamental role in real-time applications including embodied AI and autonomous driving. Unlike offline video understanding, streaming video understanding requires the ability to process video streams frame by frame, preserve historical information, and make low-latency decisions.To address these challenges, our main contributions are three-fold. (i) We develop a novel streaming video backbone, termed as StreamFormer, by incorporating causal temporal attention into a pre-trained vision transformer. This enables efficient streaming video processing while maintaining image representation capability.(ii) To train StreamFormer, we propose to unify diverse spatial-temporal video understanding tasks within a multitask visual-language alignment framework. Hence, StreamFormer learns global semantics, temporal dynamics, and fine-grained spatial relationships simultaneously. (iii) We conduct extensive experiments on online action detection, online video instance segmentation, and video question answering. StreamFormer achieves competitive results while maintaining efficiency, demonstrating its potential for real-time applications.
LamRA: Large Multimodal Model as Your Advanced Retrieval Assistant
Dec 02, 2024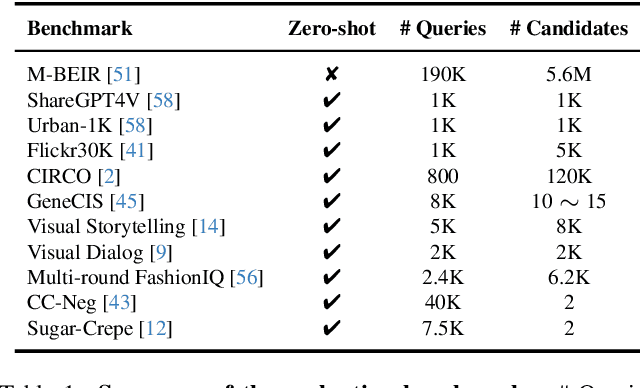
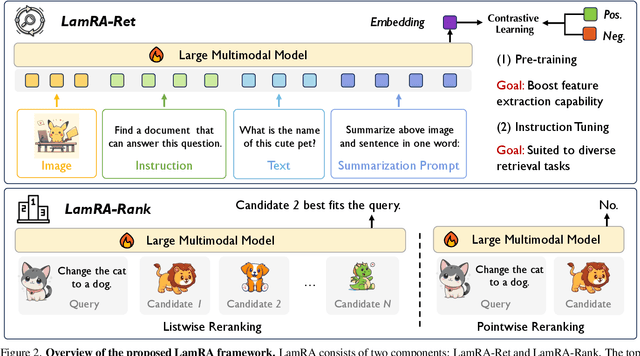
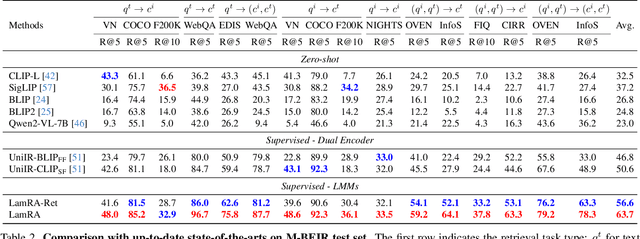
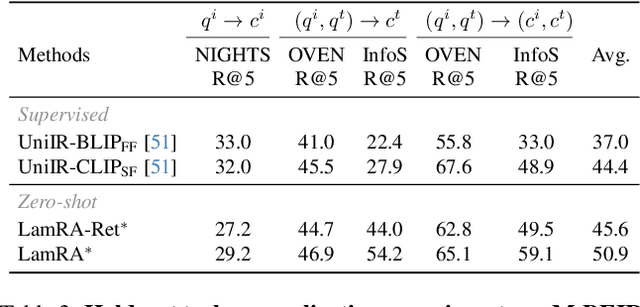
With the rapid advancement of multimodal information retrieval, increasingly complex retrieval tasks have emerged. Existing methods predominately rely on task-specific fine-tuning of vision-language models, often those trained with image-text contrastive learning. In this paper, we explore the possibility of re-purposing generative Large Multimodal Models (LMMs) for retrieval. This approach enables unifying all retrieval tasks under the same formulation and, more importantly, allows for extrapolation towards unseen retrieval tasks without additional training. Our contributions can be summarised in the following aspects: (i) We introduce LamRA, a versatile framework designed to empower LMMs with sophisticated retrieval and reranking capabilities. (ii) For retrieval, we adopt a two-stage training strategy comprising language-only pre-training and multimodal instruction tuning to progressively enhance LMM's retrieval performance. (iii) For reranking, we employ joint training for both pointwise and listwise reranking, offering two distinct ways to further boost the retrieval performance. (iv) Extensive experimental results underscore the efficacy of our method in handling more than ten retrieval tasks, demonstrating robust performance in both supervised and zero-shot settings, including scenarios involving previously unseen retrieval tasks.
Inhomogeneous illuminated image enhancement under extremely low visibility condition
Apr 26, 2024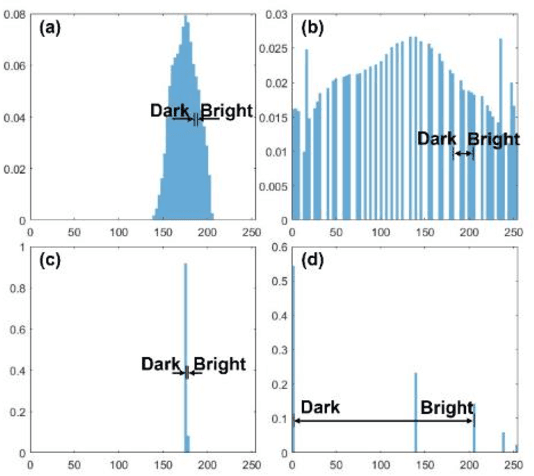
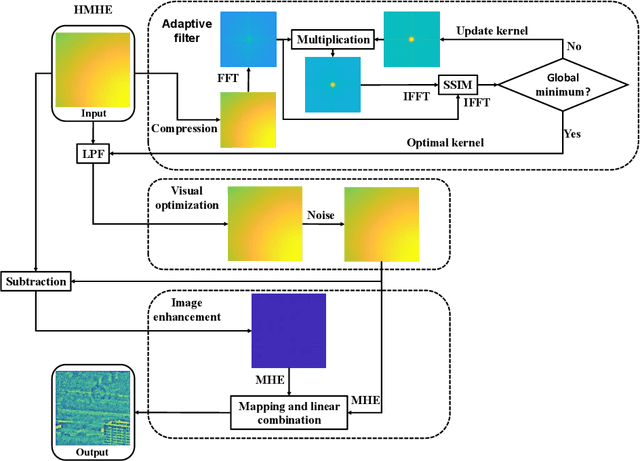

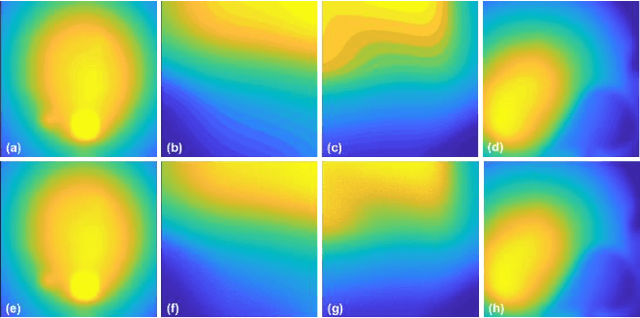
Imaging through fog significantly impacts fields such as object detection and recognition. In conditions of extremely low visibility, essential image information can be obscured, rendering standard extraction methods ineffective. Traditional digital processing techniques, such as histogram stretching, aim to mitigate fog effects by enhancing object light contrast diminished by atmospheric scattering. However, these methods often experience reduce effectiveness under inhomogeneous illumination. This paper introduces a novel approach that adaptively filters background illumination under extremely low visibility and preserve only the essential signal information. Additionally, we employ a visual optimization strategy based on image gradients to eliminate grayscale banding. Finally, the image is transformed to achieve high contrast and maintain fidelity to the original information through maximum histogram equalization. Our proposed method significantly enhances signal clarity in conditions of extremely low visibility and outperforms existing algorithms.
Harnessing Optical Imaging Limit through Atmospheric Scattering Media
Apr 23, 2024



Recording and identifying faint objects through atmospheric scattering media by an optical system are fundamentally interesting and technologically important. In this work, we introduce a comprehensive model that incorporates contributions from target characteristics, atmospheric effects, imaging system, digital processing, and visual perception to assess the ultimate perceptible limit of geometrical imaging, specifically the angular resolution at the boundary of visible distance. The model allows to reevaluate the effectiveness of conventional imaging recording, processing, and perception and to analyze the limiting factors that constrain image recognition capabilities in atmospheric media. The simulations were compared with the experimental results measured in a fog chamber and outdoor settings. The results reveal general good agreement between analysis and experimental, pointing out the way to harnessing the physical limit for optical imaging in scattering media. An immediate application of the study is the extension of the image range by an amount of 1.2 times with noise reduction via multi-frame averaging, hence greatly enhancing the capability of optical imaging in the atmosphere.
Audio-Visual Segmentation via Unlabeled Frame Exploitation
Mar 17, 2024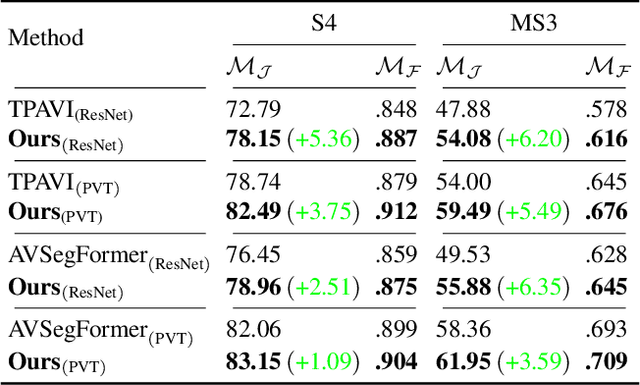
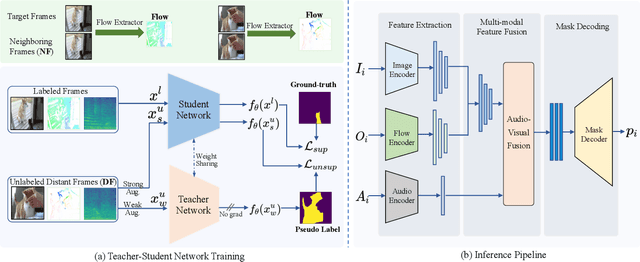
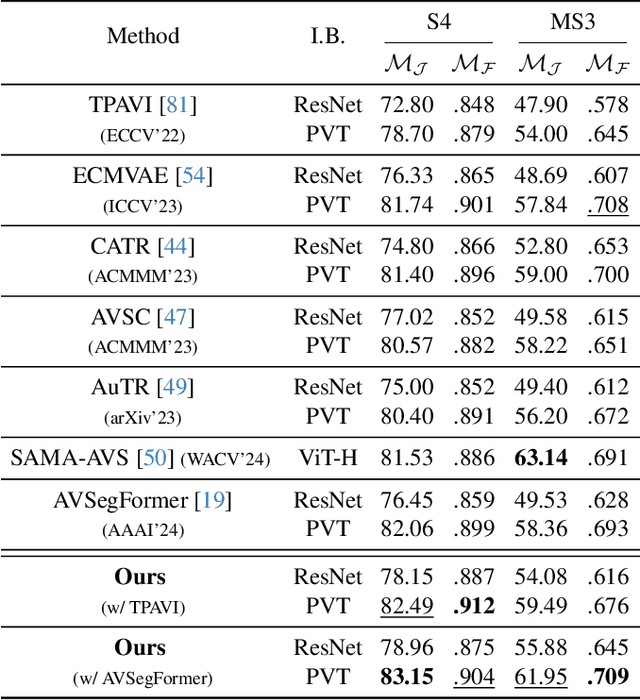
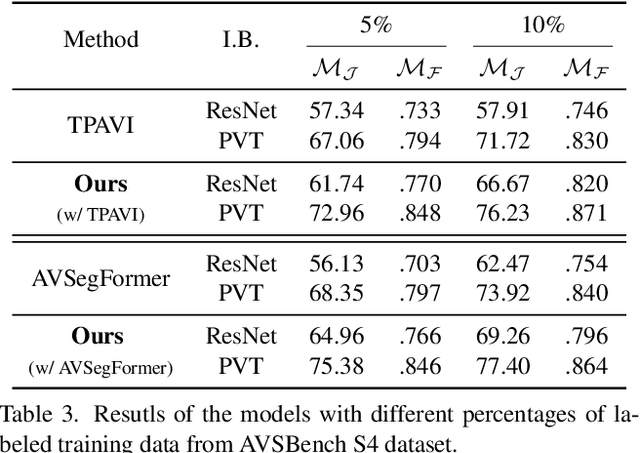
Audio-visual segmentation (AVS) aims to segment the sounding objects in video frames. Although great progress has been witnessed, we experimentally reveal that current methods reach marginal performance gain within the use of the unlabeled frames, leading to the underutilization issue. To fully explore the potential of the unlabeled frames for AVS, we explicitly divide them into two categories based on their temporal characteristics, i.e., neighboring frame (NF) and distant frame (DF). NFs, temporally adjacent to the labeled frame, often contain rich motion information that assists in the accurate localization of sounding objects. Contrary to NFs, DFs have long temporal distances from the labeled frame, which share semantic-similar objects with appearance variations. Considering their unique characteristics, we propose a versatile framework that effectively leverages them to tackle AVS. Specifically, for NFs, we exploit the motion cues as the dynamic guidance to improve the objectness localization. Besides, we exploit the semantic cues in DFs by treating them as valid augmentations to the labeled frames, which are then used to enrich data diversity in a self-training manner. Extensive experimental results demonstrate the versatility and superiority of our method, unleashing the power of the abundant unlabeled frames.
A Deep-Learning Method Using Auto-encoder and Generative Adversarial Network for Anomaly Detection on Ancient Stone Stele Surfaces
Aug 08, 2023



Accurate detection of natural deterioration and man-made damage on the surfaces of ancient stele in the first instance is essential for their preventive conservation. Existing methods for cultural heritage preservation are not able to achieve this goal perfectly due to the difficulty of balancing accuracy, efficiency, timeliness, and cost. This paper presents a deep-learning method to automatically detect above mentioned emergencies on ancient stone stele in real time, employing autoencoder (AE) and generative adversarial network (GAN). The proposed method overcomes the limitations of existing methods by requiring no extensive anomaly samples while enabling comprehensive detection of unpredictable anomalies. the method includes stages of monitoring, data acquisition, pre-processing, model structuring, and post-processing. Taking the Longmen Grottoes' stone steles as a case study, an unsupervised learning model based on AE and GAN architectures is proposed and validated with a reconstruction accuracy of 99.74\%. The method's evaluation revealed the proficient detection of seven artificially designed anomalies and demonstrated precision and reliability without false alarms. This research provides novel ideas and possibilities for the application of deep learning in the field of cultural heritage.
Zero-shot Composed Text-Image Retrieval
Jun 12, 2023In this paper, we consider the problem of composed image retrieval (CIR), it aims to train a model that can fuse multi-modal information, e.g., text and images, to accurately retrieve images that match the query, extending the user's expression ability. We make the following contributions: (i) we initiate a scalable pipeline to automatically construct datasets for training CIR model, by simply exploiting a large-scale dataset of image-text pairs, e.g., a subset of LAION-5B; (ii) we introduce a transformer-based adaptive aggregation model, TransAgg, which employs a simple yet efficient fusion mechanism, to adaptively combine information from diverse modalities; (iii) we conduct extensive ablation studies to investigate the usefulness of our proposed data construction procedure, and the effectiveness of core components in TransAgg; (iv) when evaluating on the publicly available benckmarks under the zero-shot scenario, i.e., training on the automatically constructed datasets, then directly conduct inference on target downstream datasets, e.g., CIRR and FashionIQ, our proposed approach either performs on par with or significantly outperforms the existing state-of-the-art (SOTA) models. Project page: https://code-kunkun.github.io/ZS-CIR/
Local-Global Transformer Enhanced Unfolding Network for Pan-sharpening
Apr 28, 2023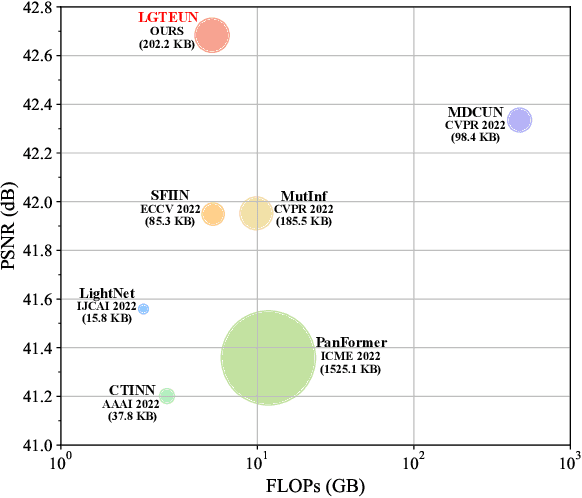

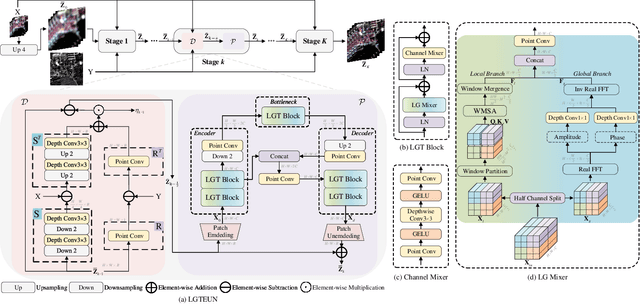

Pan-sharpening aims to increase the spatial resolution of the low-resolution multispectral (LrMS) image with the guidance of the corresponding panchromatic (PAN) image. Although deep learning (DL)-based pan-sharpening methods have achieved promising performance, most of them have a two-fold deficiency. For one thing, the universally adopted black box principle limits the model interpretability. For another thing, existing DL-based methods fail to efficiently capture local and global dependencies at the same time, inevitably limiting the overall performance. To address these mentioned issues, we first formulate the degradation process of the high-resolution multispectral (HrMS) image as a unified variational optimization problem, and alternately solve its data and prior subproblems by the designed iterative proximal gradient descent (PGD) algorithm. Moreover, we customize a Local-Global Transformer (LGT) to simultaneously model local and global dependencies, and further formulate an LGT-based prior module for image denoising. Besides the prior module, we also design a lightweight data module. Finally, by serially integrating the data and prior modules in each iterative stage, we unfold the iterative algorithm into a stage-wise unfolding network, Local-Global Transformer Enhanced Unfolding Network (LGTEUN), for the interpretable MS pan-sharpening. Comprehensive experimental results on three satellite data sets demonstrate the effectiveness and efficiency of LGTEUN compared with state-of-the-art (SOTA) methods. The source code is available at https://github.com/lms-07/LGTEUN.