 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImpostor: An Agent-Curated Benchmark for Realistic AIGC Manipulation Localization
Jun 03, 2026Recent advances in generative image editing have improved the realism and controllability of localized image manipulation, raising new challenges for image manipulation detection and localization (IMDL). However, existing IMDL benchmarks still have limitations in visual realism, manipulation diversity, and generator coverage, making it difficult to reflect recent trends in image manipulation. To address these limitations, we introduce Impostor, a high-quality AI-edited image manipulation localization dataset containing 100K manipulated images. Impostor is constructed by CraftAgent, a closed-loop agent framework that integrates scene perception, editing planning, manipulation execution, quality validation, and iterative reflection to automatically generate diverse and visually realistic manipulated images. Moreover, Impostor contains images generated by seven recent AIGC models across three manipulation types and includes multiple manipulated regions, providing a more comprehensive benchmark for AIGC-based IMDL. Furthermore, we propose PhaseAware-Net (PANet), a semantic-forensic framework that introduces local phase modeling and semantic-forensic consistency learning to better localize semantically plausible yet forensically disrupted manipulated regions. Extensive experiments show that Impostor poses significant challenges to existing large vision-language models (LVLMs) and specialized IMDL methods, while PANet achieves superior performance on Impostor and multiple public benchmarks.
Preference-Aware Rubric Learning for Personalized Evaluation
May 29, 2026As Large Language Models (LLMs) evolve from general-purpose assistants to user-centric agents, personalization has become central to aligning model behavior with individual preferences, making the evaluation of personalized alignment a critical bottleneck. Existing evaluation methods-ranging from automatic metrics to LLM-as-a-judge approaches-fail to capture subjective, user-specific preferences embedded in long-term interaction histories. We identify three essential principles for reliable and effective personalized evaluation: Representativeness, User-Consistency, and Discriminativeness. To address these principles, we introduce Personalized Evaluation as Learning, a paradigm that formulates personalized evaluation as a learning problem rather than a static judgment. Under this paradigm, we propose PARL (Preference-Aware Rubric Learning for Personalized Evaluation), a framework that learns to induce preference-aware evaluation rubrics directly from raw user histories and performs a self-validation mechanism to ensure consistency with the user's preferences. PARL integrates rubric induction with a discriminative reinforcement learning objective that contrasts user-authored responses against competitive personalized model outputs, enabling the learned rubrics to capture precise, user-specific decision boundaries. Experiments on real-world personalized text generation tasks show that PARL consistently induces high-fidelity rubrics that reliably identify user-aligned responses and generalize across users and tasks, while capturing stable stylistic preferences and fine-grained evaluative patterns. To ensure reproducibility, our code is available at https://github.com/SnowCharmQ/PARL.
AgentCVR: Active Multi-Agent Cross-Video Reasoning via Script-Simulated Reinforcement Learning
May 28, 2026Cross-Video Reasoning (CVR) has emerged as a critical frontier in multimodal intelligence, requiring models to retrieve, align, and aggregate evidence distributed across multiple videos. Current Multimodal Large Language Models (MLLMs) often struggle with CVR, as simple single-pass strategies encode multiple videos into a shared compressed context, potentially obscuring rare but critical evidence. In this paper, we propose AgentCVR, a multi-agent framework that treats CVR as an active evidence-acquisition task. AgentCVR employs a Master Agent to iteratively coordinate specialized Visual and Audio Agents for targeted evidence extraction. To ensure efficient training, we introduce Script-Simulated RL, which optimizes the agent's policy with LLM-generated semantic scripts and a lightweight text-based simulator, bypassing costly multimodal inference during online exploration. Experimental results on a comprehensive CVR benchmark show that AgentCVR outperforms single-pass baselines and achieves comparable performance to state-of-the-art closed-source systems, particularly in complex cross-video alignment and localization. To ensure reproducibility, our code is available at https://github.com/wang-jh24/AgentCVR.
Weaver: End-to-End Agentic System Training for Video Interleaved Reasoning
Feb 05, 2026Video reasoning constitutes a comprehensive assessment of a model's capabilities, as it demands robust perceptual and interpretive skills, thereby serving as a means to explore the boundaries of model performance. While recent research has leveraged text-centric Chain-of-Thought reasoning to augment these capabilities, such approaches frequently suffer from representational mismatch and restricted by limited perceptual acuity. To address these limitations, we propose Weaver, a novel, end-to-end trainable multimodal reasoning agentic system. Weaver empowers its policy model to dynamically invoke diverse tools throughout the reasoning process, enabling progressive acquisition of crucial visual cues and construction of authentic multimodal reasoning trajectories. Furthermore, we integrate a reinforcement learning algorithm to allow the system to freely explore strategies for employing and combining these tools with trajectory-free data. Extensive experiments demonstrate that our system, Weaver, enhances performance on several complex video reasoning benchmarks, particularly those involving long videos.
CrossVid: A Comprehensive Benchmark for Evaluating Cross-Video Reasoning in Multimodal Large Language Models
Nov 15, 2025Cross-Video Reasoning (CVR) presents a significant challenge in video understanding, which requires simultaneous understanding of multiple videos to aggregate and compare information across groups of videos. Most existing video understanding benchmarks focus on single-video analysis, failing to assess the ability of multimodal large language models (MLLMs) to simultaneously reason over various videos. Recent benchmarks evaluate MLLMs' capabilities on multi-view videos that capture different perspectives of the same scene. However, their limited tasks hinder a thorough assessment of MLLMs in diverse real-world CVR scenarios. To this end, we introduce CrossVid, the first benchmark designed to comprehensively evaluate MLLMs' spatial-temporal reasoning ability in cross-video contexts. Firstly, CrossVid encompasses a wide spectrum of hierarchical tasks, comprising four high-level dimensions and ten specific tasks, thereby closely reflecting the complex and varied nature of real-world video understanding. Secondly, CrossVid provides 5,331 videos, along with 9,015 challenging question-answering pairs, spanning single-choice, multiple-choice, and open-ended question formats. Through extensive experiments on various open-source and closed-source MLLMs, we observe that Gemini-2.5-Pro performs best on CrossVid, achieving an average accuracy of 50.4%. Notably, our in-depth case study demonstrates that most current MLLMs struggle with CVR tasks, primarily due to their inability to integrate or compare evidence distributed across multiple videos for reasoning. These insights highlight the potential of CrossVid to guide future advancements in enhancing MLLMs' CVR capabilities.
Progressive Scaling Visual Object Tracking
May 26, 2025In this work, we propose a progressive scaling training strategy for visual object tracking, systematically analyzing the influence of training data volume, model size, and input resolution on tracking performance. Our empirical study reveals that while scaling each factor leads to significant improvements in tracking accuracy, naive training suffers from suboptimal optimization and limited iterative refinement. To address this issue, we introduce DT-Training, a progressive scaling framework that integrates small teacher transfer and dual-branch alignment to maximize model potential. The resulting scaled tracker consistently outperforms state-of-the-art methods across multiple benchmarks, demonstrating strong generalization and transferability of the proposed method. Furthermore, we validate the broader applicability of our approach to additional tasks, underscoring its versatility beyond tracking.
WorldSense: Evaluating Real-world Omnimodal Understanding for Multimodal LLMs
Feb 06, 2025



In this paper, we introduce WorldSense, the first benchmark to assess the multi-modal video understanding, that simultaneously encompasses visual, audio, and text inputs. In contrast to existing benchmarks, our WorldSense has several features: (i) collaboration of omni-modality, we design the evaluation tasks to feature a strong coupling of audio and video, requiring models to effectively utilize the synergistic perception of omni-modality; (ii) diversity of videos and tasks, WorldSense encompasses a diverse collection of 1,662 audio-visual synchronised videos, systematically categorized into 8 primary domains and 67 fine-grained subcategories to cover the broad scenarios, and 3,172 multi-choice QA pairs across 26 distinct tasks to enable the comprehensive evaluation; (iii) high-quality annotations, all the QA pairs are manually labeled by 80 expert annotators with multiple rounds of correction to ensure quality. Based on our WorldSense, we extensively evaluate various state-of-the-art models. The experimental results indicate that existing models face significant challenges in understanding real-world scenarios (48.0% best accuracy). We hope our WorldSense can provide a platform for evaluating the ability in constructing and understanding coherent contexts from omni-modality.
LamRA: Large Multimodal Model as Your Advanced Retrieval Assistant
Dec 02, 2024
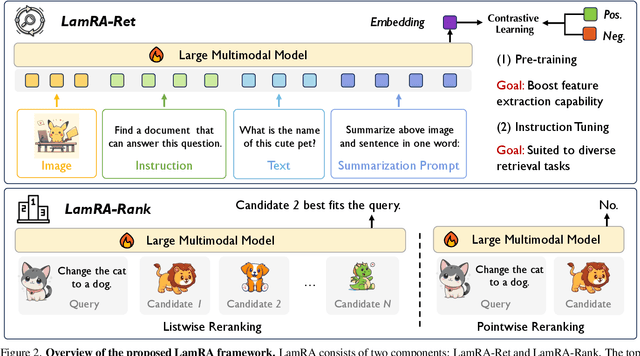
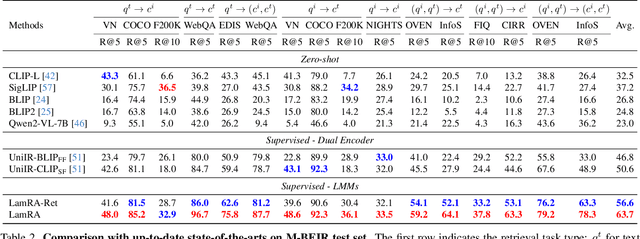
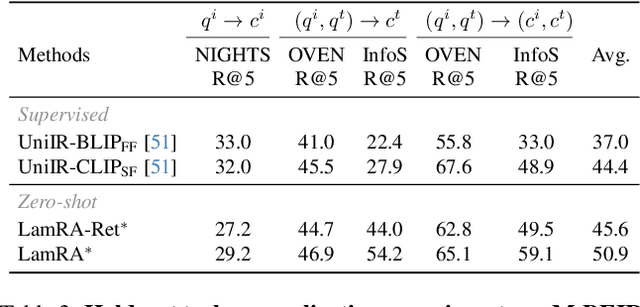
With the rapid advancement of multimodal information retrieval, increasingly complex retrieval tasks have emerged. Existing methods predominately rely on task-specific fine-tuning of vision-language models, often those trained with image-text contrastive learning. In this paper, we explore the possibility of re-purposing generative Large Multimodal Models (LMMs) for retrieval. This approach enables unifying all retrieval tasks under the same formulation and, more importantly, allows for extrapolation towards unseen retrieval tasks without additional training. Our contributions can be summarised in the following aspects: (i) We introduce LamRA, a versatile framework designed to empower LMMs with sophisticated retrieval and reranking capabilities. (ii) For retrieval, we adopt a two-stage training strategy comprising language-only pre-training and multimodal instruction tuning to progressively enhance LMM's retrieval performance. (iii) For reranking, we employ joint training for both pointwise and listwise reranking, offering two distinct ways to further boost the retrieval performance. (iv) Extensive experimental results underscore the efficacy of our method in handling more than ten retrieval tasks, demonstrating robust performance in both supervised and zero-shot settings, including scenarios involving previously unseen retrieval tasks.
P4Q: Learning to Prompt for Quantization in Visual-language Models
Sep 26, 2024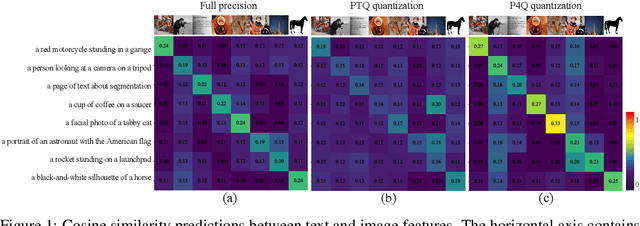
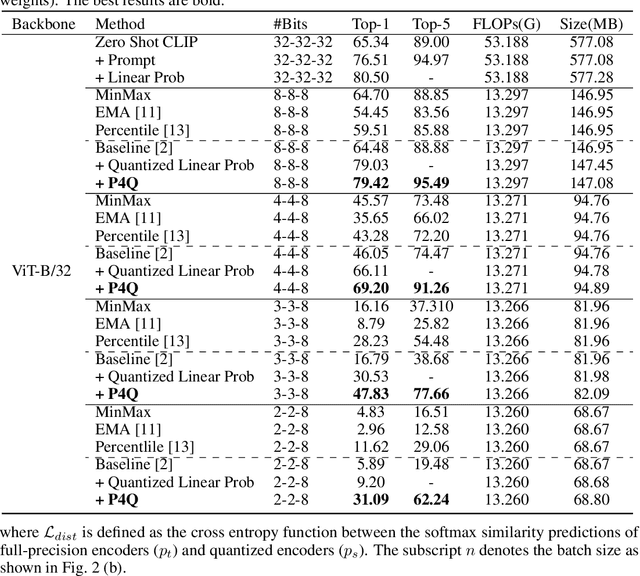
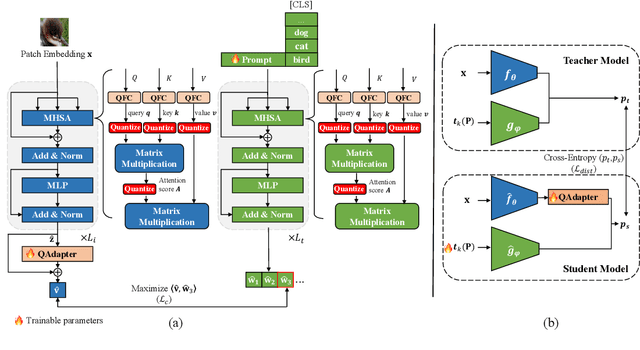
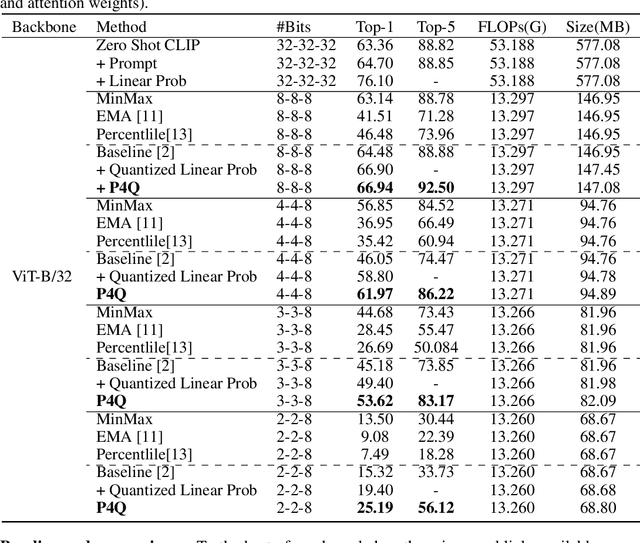
Large-scale pre-trained Vision-Language Models (VLMs) have gained prominence in various visual and multimodal tasks, yet the deployment of VLMs on downstream application platforms remains challenging due to their prohibitive requirements of training samples and computing resources. Fine-tuning and quantization of VLMs can substantially reduce the sample and computation costs, which are in urgent need. There are two prevailing paradigms in quantization, Quantization-Aware Training (QAT) can effectively quantize large-scale VLMs but incur a huge training cost, while low-bit Post-Training Quantization (PTQ) suffers from a notable performance drop. We propose a method that balances fine-tuning and quantization named ``Prompt for Quantization'' (P4Q), in which we design a lightweight architecture to leverage contrastive loss supervision to enhance the recognition performance of a PTQ model. Our method can effectively reduce the gap between image features and text features caused by low-bit quantization, based on learnable prompts to reorganize textual representations and a low-bit adapter to realign the distributions of image and text features. We also introduce a distillation loss based on cosine similarity predictions to distill the quantized model using a full-precision teacher. Extensive experimental results demonstrate that our P4Q method outperforms prior arts, even achieving comparable results to its full-precision counterparts. For instance, our 8-bit P4Q can theoretically compress the CLIP-ViT/B-32 by 4 $\times$ while achieving 66.94\% Top-1 accuracy, outperforming the learnable prompt fine-tuned full-precision model by 2.24\% with negligible additional parameters on the ImageNet dataset.
Improving Synthetic Image Detection Towards Generalization: An Image Transformation Perspective
Aug 13, 2024



With recent generative models facilitating photo-realistic image synthesis, the proliferation of synthetic images has also engendered certain negative impacts on social platforms, thereby raising an urgent imperative to develop effective detectors. Current synthetic image detection (SID) pipelines are primarily dedicated to crafting universal artifact features, accompanied by an oversight about SID training paradigm. In this paper, we re-examine the SID problem and identify two prevalent biases in current training paradigms, i.e., weakened artifact features and overfitted artifact features. Meanwhile, we discover that the imaging mechanism of synthetic images contributes to heightened local correlations among pixels, suggesting that detectors should be equipped with local awareness. In this light, we propose SAFE, a lightweight and effective detector with three simple image transformations. Firstly, for weakened artifact features, we substitute the down-sampling operator with the crop operator in image pre-processing to help circumvent artifact distortion. Secondly, for overfitted artifact features, we include ColorJitter and RandomRotation as additional data augmentations, to help alleviate irrelevant biases from color discrepancies and semantic differences in limited training samples. Thirdly, for local awareness, we propose a patch-based random masking strategy tailored for SID, forcing the detector to focus on local regions at training. Comparative experiments are conducted on an open-world dataset, comprising synthetic images generated by 26 distinct generative models. Our pipeline achieves a new state-of-the-art performance, with remarkable improvements of 4.5% in accuracy and 2.9% in average precision against existing methods.