 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeP4Q: Learning to Prompt for Quantization in Visual-language Models
Paper and Code
Sep 26, 2024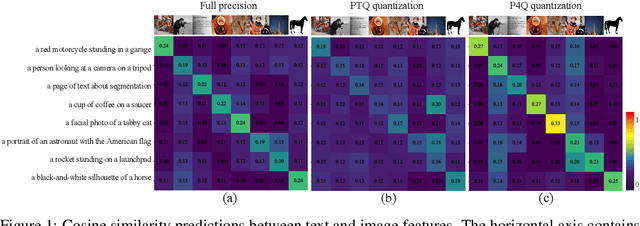
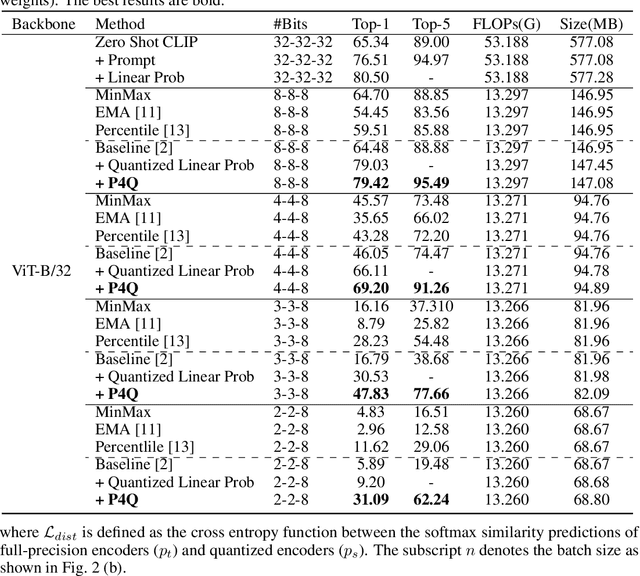
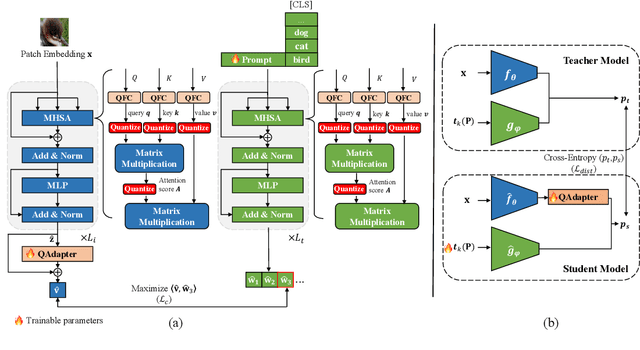
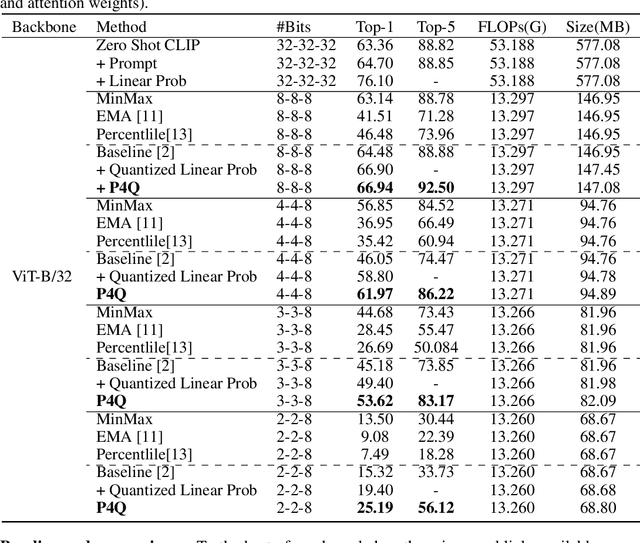
Large-scale pre-trained Vision-Language Models (VLMs) have gained prominence in various visual and multimodal tasks, yet the deployment of VLMs on downstream application platforms remains challenging due to their prohibitive requirements of training samples and computing resources. Fine-tuning and quantization of VLMs can substantially reduce the sample and computation costs, which are in urgent need. There are two prevailing paradigms in quantization, Quantization-Aware Training (QAT) can effectively quantize large-scale VLMs but incur a huge training cost, while low-bit Post-Training Quantization (PTQ) suffers from a notable performance drop. We propose a method that balances fine-tuning and quantization named ``Prompt for Quantization'' (P4Q), in which we design a lightweight architecture to leverage contrastive loss supervision to enhance the recognition performance of a PTQ model. Our method can effectively reduce the gap between image features and text features caused by low-bit quantization, based on learnable prompts to reorganize textual representations and a low-bit adapter to realign the distributions of image and text features. We also introduce a distillation loss based on cosine similarity predictions to distill the quantized model using a full-precision teacher. Extensive experimental results demonstrate that our P4Q method outperforms prior arts, even achieving comparable results to its full-precision counterparts. For instance, our 8-bit P4Q can theoretically compress the CLIP-ViT/B-32 by 4 $\times$ while achieving 66.94\% Top-1 accuracy, outperforming the learnable prompt fine-tuned full-precision model by 2.24\% with negligible additional parameters on the ImageNet dataset.