 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKling-Omni Technical Report
Dec 18, 2025



We present Kling-Omni, a generalist generative framework designed to synthesize high-fidelity videos directly from multimodal visual language inputs. Adopting an end-to-end perspective, Kling-Omni bridges the functional separation among diverse video generation, editing, and intelligent reasoning tasks, integrating them into a holistic system. Unlike disjointed pipeline approaches, Kling-Omni supports a diverse range of user inputs, including text instructions, reference images, and video contexts, processing them into a unified multimodal representation to deliver cinematic-quality and highly-intelligent video content creation. To support these capabilities, we constructed a comprehensive data system that serves as the foundation for multimodal video creation. The framework is further empowered by efficient large-scale pre-training strategies and infrastructure optimizations for inference. Comprehensive evaluations reveal that Kling-Omni demonstrates exceptional capabilities in in-context generation, reasoning-based editing, and multimodal instruction following. Moving beyond a content creation tool, we believe Kling-Omni is a pivotal advancement toward multimodal world simulators capable of perceiving, reasoning, generating and interacting with the dynamic and complex worlds.
Near-Optimal Regret for Efficient Stochastic Combinatorial Semi-Bandits
Aug 08, 2025The combinatorial multi-armed bandit (CMAB) is a cornerstone of sequential decision-making framework, dominated by two algorithmic families: UCB-based and adversarial methods such as follow the regularized leader (FTRL) and online mirror descent (OMD). However, prominent UCB-based approaches like CUCB suffer from additional regret factor $\log T$ that is detrimental over long horizons, while adversarial methods such as EXP3.M and HYBRID impose significant computational overhead. To resolve this trade-off, we introduce the Combinatorial Minimax Optimal Strategy in the Stochastic setting (CMOSS). CMOSS is a computationally efficient algorithm that achieves an instance-independent regret of $O\big( (\log k)^2\sqrt{kmT}\big )$ under semi-bandit feedback, where $m$ is the number of arms and $k$ is the maximum cardinality of a feasible action. Crucially, this result eliminates the dependency on $\log T$ and matches the established $\Omega\big( \sqrt{kmT}\big)$ lower bound up to $O\big((\log k)^2\big)$. We then extend our analysis to show that CMOSS is also applicable to cascading feedback. Experiments on synthetic and real-world datasets validate that CMOSS consistently outperforms benchmark algorithms in both regret and runtime efficiency.
Squeeze10-LLM: Squeezing LLMs' Weights by 10 Times via a Staged Mixed-Precision Quantization Method
Jul 24, 2025Deploying large language models (LLMs) is challenging due to their massive parameters and high computational costs. Ultra low-bit quantization can significantly reduce storage and accelerate inference, but extreme compression (i.e., mean bit-width <= 2) often leads to severe performance degradation. To address this, we propose Squeeze10-LLM, effectively "squeezing" 16-bit LLMs' weights by 10 times. Specifically, Squeeze10-LLM is a staged mixed-precision post-training quantization (PTQ) framework and achieves an average of 1.6 bits per weight by quantizing 80% of the weights to 1 bit and 20% to 4 bits. We introduce Squeeze10LLM with two key innovations: Post-Binarization Activation Robustness (PBAR) and Full Information Activation Supervision (FIAS). PBAR is a refined weight significance metric that accounts for the impact of quantization on activations, improving accuracy in low-bit settings. FIAS is a strategy that preserves full activation information during quantization to mitigate cumulative error propagation across layers. Experiments on LLaMA and LLaMA2 show that Squeeze10-LLM achieves state-of-the-art performance for sub-2bit weight-only quantization, improving average accuracy from 43% to 56% on six zero-shot classification tasks--a significant boost over existing PTQ methods. Our code will be released upon publication.
Leader and Follower: Interactive Motion Generation under Trajectory Constraints
Feb 17, 2025With the rapid advancement of game and film production, generating interactive motion from texts has garnered significant attention due to its potential to revolutionize content creation processes. In many practical applications, there is a need to impose strict constraints on the motion range or trajectory of virtual characters. However, existing methods that rely solely on textual input face substantial challenges in accurately capturing the user's intent, particularly in specifying the desired trajectory. As a result, the generated motions often lack plausibility and accuracy. Moreover, existing trajectory - based methods for customized motion generation rely on retraining for single - actor scenarios, which limits flexibility and adaptability to different datasets, as well as interactivity in two-actor motions. To generate interactive motion following specified trajectories, this paper decouples complex motion into a Leader - Follower dynamic, inspired by role allocation in partner dancing. Based on this framework, this paper explores the motion range refinement process in interactive motion generation and proposes a training-free approach, integrating a Pace Controller and a Kinematic Synchronization Adapter. The framework enhances the ability of existing models to generate motion that adheres to trajectory by controlling the leader's movement and correcting the follower's motion to align with the leader. Experimental results show that the proposed approach, by better leveraging trajectory information, outperforms existing methods in both realism and accuracy.
DynamicFace: High-Quality and Consistent Video Face Swapping using Composable 3D Facial Priors
Jan 15, 2025



Face swapping transfers the identity of a source face to a target face while retaining the attributes like expression, pose, hair, and background of the target face. Advanced face swapping methods have achieved attractive results. However, these methods often inadvertently transfer identity information from the target face, compromising expression-related details and accurate identity. We propose a novel method DynamicFace that leverages the power of diffusion model and plug-and-play temporal layers for video face swapping. First, we introduce four fine-grained face conditions using 3D facial priors. All conditions are designed to be disentangled from each other for precise and unique control. Then, we adopt Face Former and ReferenceNet for high-level and detailed identity injection. Through experiments on the FF++ dataset, we demonstrate that our method achieves state-of-the-art results in face swapping, showcasing superior image quality, identity preservation, and expression accuracy. Besides, our method could be easily transferred to video domain with temporal attention layer. Our code and results will be available on the project page: https://dynamic-face.github.io/
Single Trajectory Distillation for Accelerating Image and Video Style Transfer
Dec 25, 2024



Diffusion-based stylization methods typically denoise from a specific partial noise state for image-to-image and video-to-video tasks. This multi-step diffusion process is computationally expensive and hinders real-world application. A promising solution to speed up the process is to obtain few-step consistency models through trajectory distillation. However, current consistency models only force the initial-step alignment between the probability flow ODE (PF-ODE) trajectories of the student and the imperfect teacher models. This training strategy can not ensure the consistency of whole trajectories. To address this issue, we propose single trajectory distillation (STD) starting from a specific partial noise state. We introduce a trajectory bank to store the teacher model's trajectory states, mitigating the time cost during training. Besides, we use an asymmetric adversarial loss to enhance the style and quality of the generated images. Extensive experiments on image and video stylization demonstrate that our method surpasses existing acceleration models in terms of style similarity and aesthetic evaluations. Our code and results will be available on the project page: https://single-trajectory-distillation.github.io.
P4Q: Learning to Prompt for Quantization in Visual-language Models
Sep 26, 2024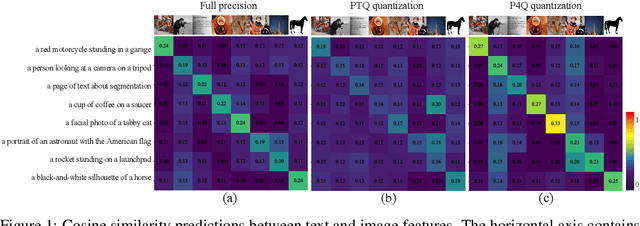
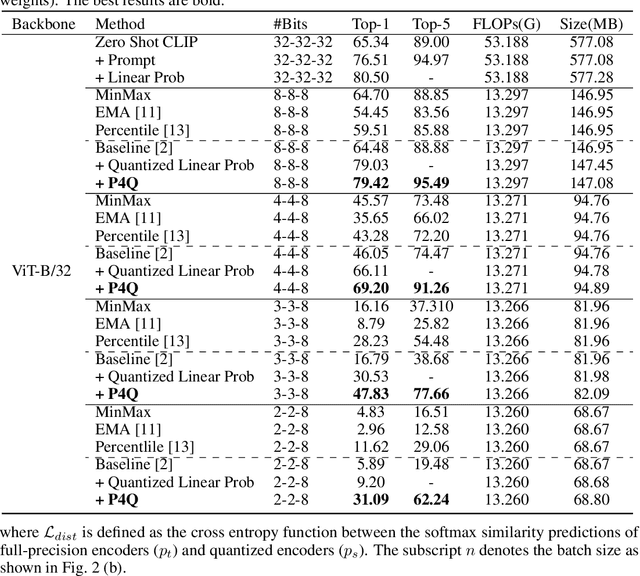
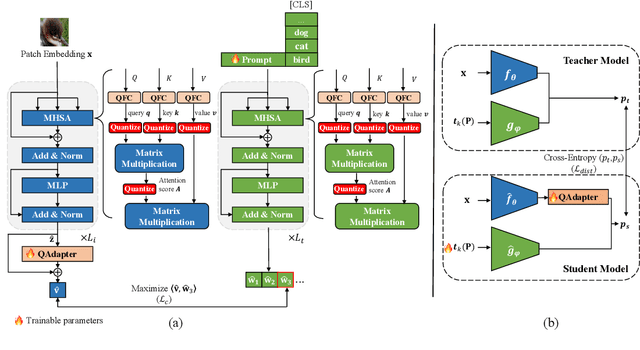
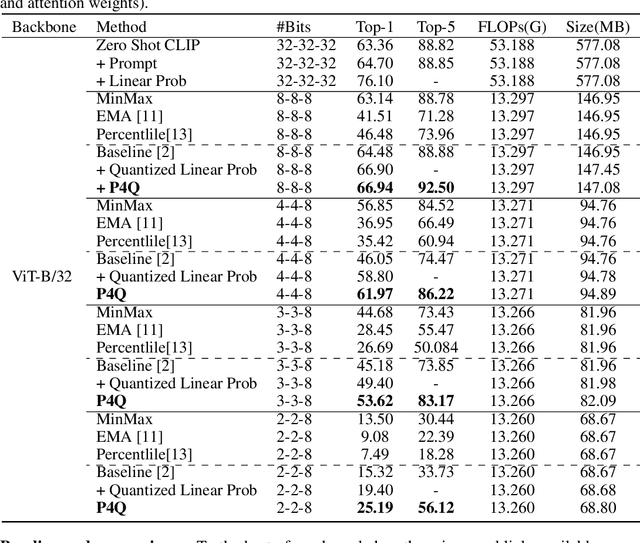
Large-scale pre-trained Vision-Language Models (VLMs) have gained prominence in various visual and multimodal tasks, yet the deployment of VLMs on downstream application platforms remains challenging due to their prohibitive requirements of training samples and computing resources. Fine-tuning and quantization of VLMs can substantially reduce the sample and computation costs, which are in urgent need. There are two prevailing paradigms in quantization, Quantization-Aware Training (QAT) can effectively quantize large-scale VLMs but incur a huge training cost, while low-bit Post-Training Quantization (PTQ) suffers from a notable performance drop. We propose a method that balances fine-tuning and quantization named ``Prompt for Quantization'' (P4Q), in which we design a lightweight architecture to leverage contrastive loss supervision to enhance the recognition performance of a PTQ model. Our method can effectively reduce the gap between image features and text features caused by low-bit quantization, based on learnable prompts to reorganize textual representations and a low-bit adapter to realign the distributions of image and text features. We also introduce a distillation loss based on cosine similarity predictions to distill the quantized model using a full-precision teacher. Extensive experimental results demonstrate that our P4Q method outperforms prior arts, even achieving comparable results to its full-precision counterparts. For instance, our 8-bit P4Q can theoretically compress the CLIP-ViT/B-32 by 4 $\times$ while achieving 66.94\% Top-1 accuracy, outperforming the learnable prompt fine-tuned full-precision model by 2.24\% with negligible additional parameters on the ImageNet dataset.
TAAT: Think and Act from Arbitrary Texts in Text2Motion
Apr 23, 2024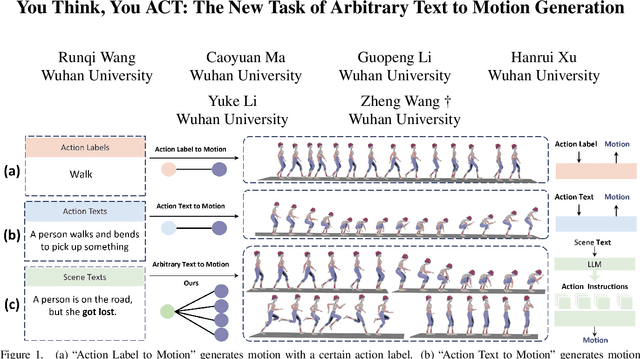

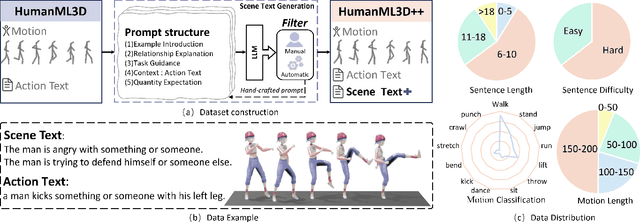

Text2Motion aims to generate human motions from texts. Existing datasets rely on the assumption that texts include action labels (such as "walk, bend, and pick up"), which is not flexible for practical scenarios. This paper redefines this problem with a more realistic assumption that the texts are arbitrary. Specifically, arbitrary texts include existing action texts composed of action labels (e.g., A person walks and bends to pick up something), and introduce scene texts without explicit action labels (e.g., A person notices his wallet on the ground ahead). To bridge the gaps between this realistic setting and existing datasets, we expand the action texts on the HumanML3D dataset to more scene texts, thereby creating a new HumanML3D++ dataset including arbitrary texts. In this challenging dataset, we benchmark existing state-of-the-art methods and propose a novel two-stage framework to extract action labels from arbitrary texts by the Large Language Model (LLM) and then generate motions from action labels. Extensive experiments are conducted under different application scenarios to validate the effectiveness of the proposed framework on existing and proposed datasets. The results indicate that Text2Motion in this realistic setting is very challenging, fostering new research in this practical direction. Our dataset and code will be released.
Cross-Level Distillation and Feature Denoising for Cross-Domain Few-Shot Classification
Nov 04, 2023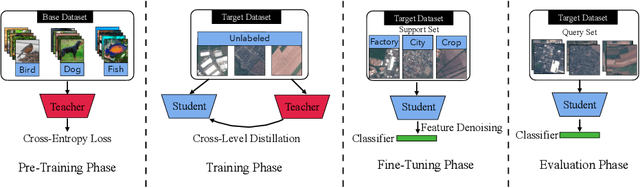
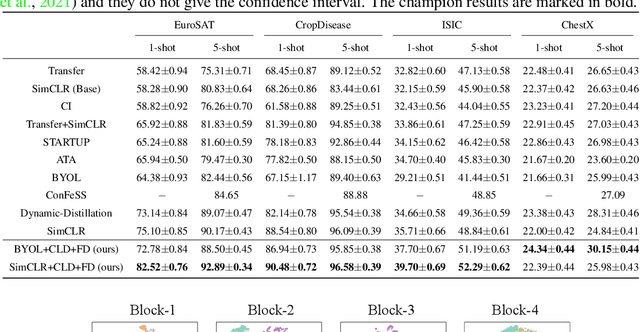
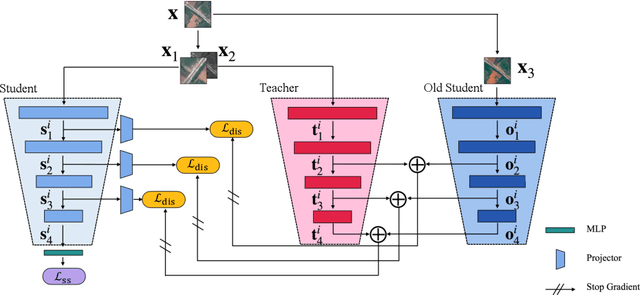

The conventional few-shot classification aims at learning a model on a large labeled base dataset and rapidly adapting to a target dataset that is from the same distribution as the base dataset. However, in practice, the base and the target datasets of few-shot classification are usually from different domains, which is the problem of cross-domain few-shot classification. We tackle this problem by making a small proportion of unlabeled images in the target domain accessible in the training stage. In this setup, even though the base data are sufficient and labeled, the large domain shift still makes transferring the knowledge from the base dataset difficult. We meticulously design a cross-level knowledge distillation method, which can strengthen the ability of the model to extract more discriminative features in the target dataset by guiding the network's shallow layers to learn higher-level information. Furthermore, in order to alleviate the overfitting in the evaluation stage, we propose a feature denoising operation which can reduce the feature redundancy and mitigate overfitting. Our approach can surpass the previous state-of-the-art method, Dynamic-Distillation, by 5.44% on 1-shot and 1.37% on 5-shot classification tasks on average in the BSCD-FSL benchmark. The implementation code will be available at https://github.com/jarucezh/cldfd.
Self-Enhancement Improves Text-Image Retrieval in Foundation Visual-Language Models
Jun 11, 2023The emergence of cross-modal foundation models has introduced numerous approaches grounded in text-image retrieval. However, on some domain-specific retrieval tasks, these models fail to focus on the key attributes required. To address this issue, we propose a self-enhancement framework, A^{3}R, based on the CLIP-ViT/G-14, one of the largest cross-modal models. First, we perform an Attribute Augmentation strategy to enrich the textual description for fine-grained representation before model learning. Then, we propose an Adaption Re-ranking method to unify the representation space of textual query and candidate images and re-rank candidate images relying on the adapted query after model learning. The proposed framework is validated to achieve a salient improvement over the baseline and other teams' solutions in the cross-modal image retrieval track of the 1st foundation model challenge without introducing any additional samples. The code is available at \url{https://github.com/CapricornGuang/A3R}.