 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIP-Map: Structured Matrix Mapping for Parameter-Efficient CLIP Compression
Feb 05, 2026Contrastive Language-Image Pre-training (CLIP) has achieved widely applications in various computer vision tasks, e.g., text-to-image generation, Image-Text retrieval and Image captioning. However, CLIP suffers from high memory and computation cost, which prohibits its usage to the resource-limited application scenarios. Existing CLIP compression methods typically reduce the size of pre-trained CLIP weights by selecting their subset as weight inheritance for further retraining via mask optimization or important weight measurement. However, these select-based weight inheritance often compromises the feature presentation ability, especially on the extreme compression. In this paper, we propose a novel mapping-based CLIP compression framework, CLIP-Map. It leverages learnable matrices to map and combine pretrained weights by Full-Mapping with Kronecker Factorization, aiming to preserve as much information from the original weights as possible. To mitigate the optimization challenges introduced by the learnable mapping, we propose Diagonal Inheritance Initialization to reduce the distribution shifting problem for efficient and effective mapping learning. Extensive experimental results demonstrate that the proposed CLIP-Map outperforms select-based frameworks across various compression ratios, with particularly significant gains observed under high compression settings.
DynamicFace: High-Quality and Consistent Video Face Swapping using Composable 3D Facial Priors
Jan 15, 2025



Face swapping transfers the identity of a source face to a target face while retaining the attributes like expression, pose, hair, and background of the target face. Advanced face swapping methods have achieved attractive results. However, these methods often inadvertently transfer identity information from the target face, compromising expression-related details and accurate identity. We propose a novel method DynamicFace that leverages the power of diffusion model and plug-and-play temporal layers for video face swapping. First, we introduce four fine-grained face conditions using 3D facial priors. All conditions are designed to be disentangled from each other for precise and unique control. Then, we adopt Face Former and ReferenceNet for high-level and detailed identity injection. Through experiments on the FF++ dataset, we demonstrate that our method achieves state-of-the-art results in face swapping, showcasing superior image quality, identity preservation, and expression accuracy. Besides, our method could be easily transferred to video domain with temporal attention layer. Our code and results will be available on the project page: https://dynamic-face.github.io/
Single Trajectory Distillation for Accelerating Image and Video Style Transfer
Dec 25, 2024



Diffusion-based stylization methods typically denoise from a specific partial noise state for image-to-image and video-to-video tasks. This multi-step diffusion process is computationally expensive and hinders real-world application. A promising solution to speed up the process is to obtain few-step consistency models through trajectory distillation. However, current consistency models only force the initial-step alignment between the probability flow ODE (PF-ODE) trajectories of the student and the imperfect teacher models. This training strategy can not ensure the consistency of whole trajectories. To address this issue, we propose single trajectory distillation (STD) starting from a specific partial noise state. We introduce a trajectory bank to store the teacher model's trajectory states, mitigating the time cost during training. Besides, we use an asymmetric adversarial loss to enhance the style and quality of the generated images. Extensive experiments on image and video stylization demonstrate that our method surpasses existing acceleration models in terms of style similarity and aesthetic evaluations. Our code and results will be available on the project page: https://single-trajectory-distillation.github.io.
Target-Driven Distillation: Consistency Distillation with Target Timestep Selection and Decoupled Guidance
Sep 02, 2024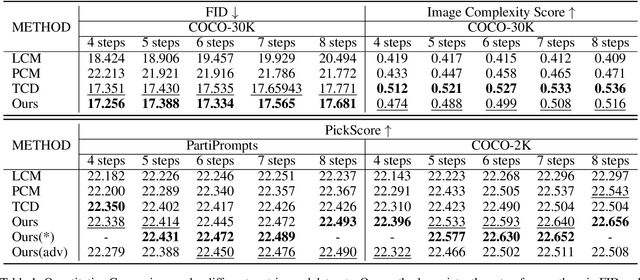
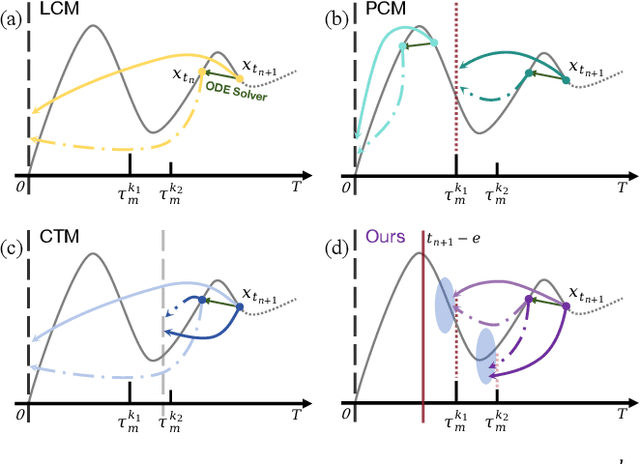
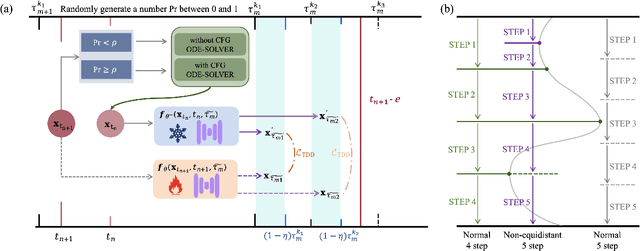

Consistency distillation methods have demonstrated significant success in accelerating generative tasks of diffusion models. However, since previous consistency distillation methods use simple and straightforward strategies in selecting target timesteps, they usually struggle with blurs and detail losses in generated images. To address these limitations, we introduce Target-Driven Distillation (TDD), which (1) adopts a delicate selection strategy of target timesteps, increasing the training efficiency; (2) utilizes decoupled guidances during training, making TDD open to post-tuning on guidance scale during inference periods; (3) can be optionally equipped with non-equidistant sampling and x0 clipping, enabling a more flexible and accurate way for image sampling. Experiments verify that TDD achieves state-of-the-art performance in few-step generation, offering a better choice among consistency distillation models.