 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModular PE-Structured Learning for Cross-Task Wireless Communications
Sep 10, 2025Recent trends in learning wireless policies attempt to develop deep neural networks (DNNs) for handling multiple tasks with a single model. Existing approaches often rely on large models, which are hard to pre-train and fine-tune at the wireless edge. In this work, we challenge this paradigm by leveraging the structured knowledge of wireless problems -- specifically, permutation equivariant (PE) properties. We design three types of PE-aware modules, two of which are Transformer-style sub-layers. These modules can serve as building blocks to assemble compact DNNs applicable to the wireless policies with various PE properties. To guide the design, we analyze the hypothesis space associated with each PE property, and show that the PE-structured module assembly can boost the learning efficiency. Inspired by the reusability of the modules, we propose PE-MoFormer, a compositional DNN capable of learning a wide range of wireless policies -- including but not limited to precoding, coordinated beamforming, power allocation, and channel estimation -- with strong generalizability, low sample and space complexity. Simulations demonstrate that the proposed modular PE-based framework outperforms relevant large model in both learning efficiency and inference time, offering a new direction for structured cross-task learning for wireless communications.
Learning Precoding in Multi-user Multi-antenna Systems: Transformer or Graph Transformer?
Mar 04, 2025Transformers have been designed for channel acquisition tasks such as channel prediction and other tasks such as precoding, while graph neural networks (GNNs) have been demonstrated to be efficient for learning a multitude of communication tasks. Nonetheless, whether or not Transformers are efficient for the tasks other than channel acquisition and how to reap the benefits of both architectures are less understood. In this paper, we take learning precoding policies in multi-user multi-antenna systems as an example to answer the questions. We notice that a Transformer tailored for precoding can reflect multiuser interference, which is essential for its generalizability to the number of users. Yet the tailored Transformer can only leverage partial permutation property of precoding policies and hence is not generalizable to the number of antennas, same as a GNN learning over a homogeneous graph. To provide useful insight, we establish the relation between Transformers and the GNNs that learn over heterogeneous graphs. Based on the relation, we propose Graph Transformers, namely 2D- and 3D-Gformers, for exploiting the permutation properties of baseband precoding and hybrid precoding policies. The learning performance, inference and training complexity, and size-generalizability of the Gformers are evaluated and compared with Transformers and GNNs via simulations.
DomainGallery: Few-shot Domain-driven Image Generation by Attribute-centric Finetuning
Nov 07, 2024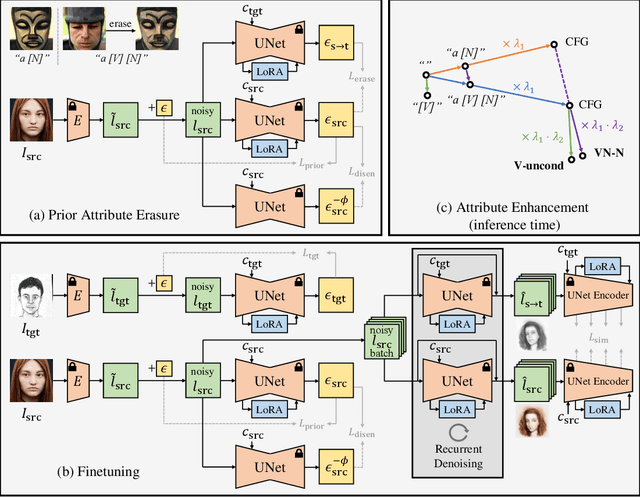
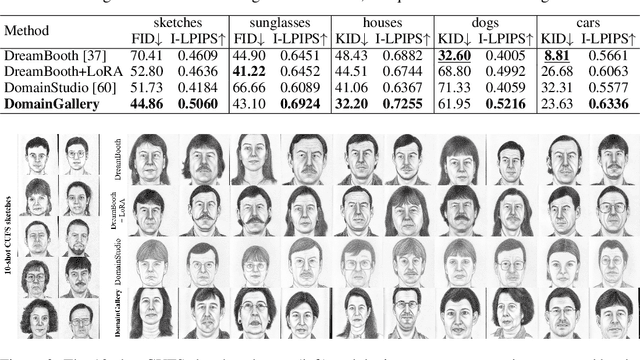


The recent progress in text-to-image models pretrained on large-scale datasets has enabled us to generate various images as long as we provide a text prompt describing what we want. Nevertheless, the availability of these models is still limited when we expect to generate images that fall into a specific domain either hard to describe or just unseen to the models. In this work, we propose DomainGallery, a few-shot domain-driven image generation method which aims at finetuning pretrained Stable Diffusion on few-shot target datasets in an attribute-centric manner. Specifically, DomainGallery features prior attribute erasure, attribute disentanglement, regularization and enhancement. These techniques are tailored to few-shot domain-driven generation in order to solve key issues that previous works have failed to settle. Extensive experiments are given to validate the superior performance of DomainGallery on a variety of domain-driven generation scenarios. Codes are available at https://github.com/Ldhlwh/DomainGallery.
Target-Driven Distillation: Consistency Distillation with Target Timestep Selection and Decoupled Guidance
Sep 02, 2024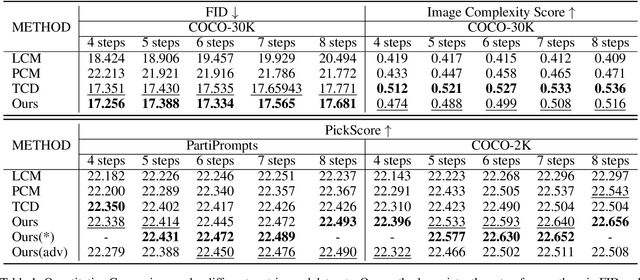
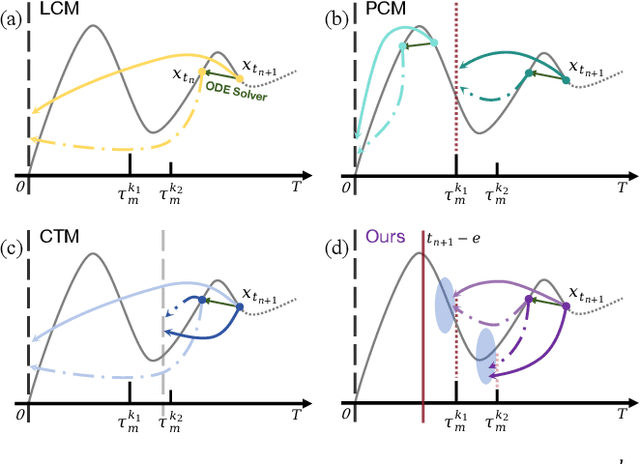
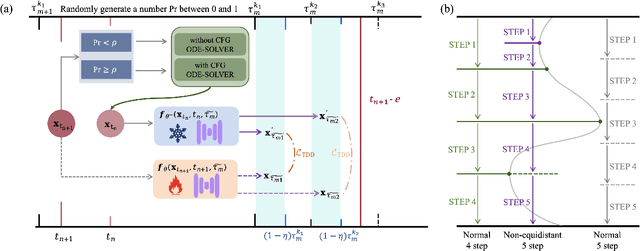

Consistency distillation methods have demonstrated significant success in accelerating generative tasks of diffusion models. However, since previous consistency distillation methods use simple and straightforward strategies in selecting target timesteps, they usually struggle with blurs and detail losses in generated images. To address these limitations, we introduce Target-Driven Distillation (TDD), which (1) adopts a delicate selection strategy of target timesteps, increasing the training efficiency; (2) utilizes decoupled guidances during training, making TDD open to post-tuning on guidance scale during inference periods; (3) can be optionally equipped with non-equidistant sampling and x0 clipping, enabling a more flexible and accurate way for image sampling. Experiments verify that TDD achieves state-of-the-art performance in few-step generation, offering a better choice among consistency distillation models.
Dataset Distillation in Latent Space
Nov 27, 2023
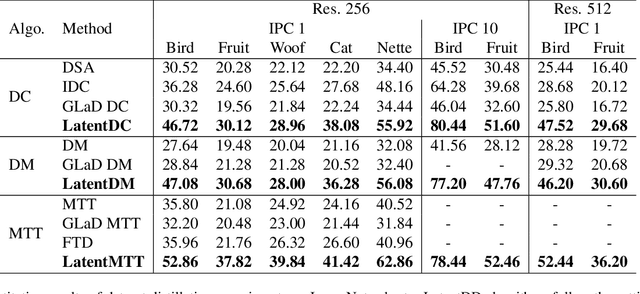


Dataset distillation (DD) is a newly emerging research area aiming at alleviating the heavy computational load in training models on large datasets. It tries to distill a large dataset into a small and condensed one so that models trained on the distilled dataset can perform comparably with those trained on the full dataset when performing downstream tasks. Among the previous works in this area, there are three key problems that hinder the performance and availability of the existing DD methods: high time complexity, high space complexity, and low info-compactness. In this work, we simultaneously attempt to settle these three problems by moving the DD processes from conventionally used pixel space to latent space. Encoded by a pretrained generic autoencoder, latent codes in the latent space are naturally info-compact representations of the original images in much smaller sizes. After transferring three mainstream DD algorithms to latent space, we significantly reduce time and space consumption while achieving similar performance, allowing us to distill high-resolution datasets or target at greater data ratio that previous methods have failed. Besides, within the same storage budget, we can also quantitatively deliver more latent codes than pixel-level images, which further boosts the performance of our methods.
ControlCom: Controllable Image Composition using Diffusion Model
Aug 19, 2023



Image composition targets at synthesizing a realistic composite image from a pair of foreground and background images. Recently, generative composition methods are built on large pretrained diffusion models to generate composite images, considering their great potential in image generation. However, they suffer from lack of controllability on foreground attributes and poor preservation of foreground identity. To address these challenges, we propose a controllable image composition method that unifies four tasks in one diffusion model: image blending, image harmonization, view synthesis, and generative composition. Meanwhile, we design a self-supervised training framework coupled with a tailored pipeline of training data preparation. Moreover, we propose a local enhancement module to enhance the foreground details in the diffusion model, improving the foreground fidelity of composite images. The proposed method is evaluated on both public benchmark and real-world data, which demonstrates that our method can generate more faithful and controllable composite images than existing approaches. The code and model will be available at https://github.com/bcmi/ControlCom-Image-Composition.
WeditGAN: Few-shot Image Generation via Latent Space Relocation
May 11, 2023In few-shot image generation, directly training GAN models on just a handful of images faces the risk of overfitting. A popular solution is to transfer the models pretrained on large source domains to small target ones. In this work, we introduce WeditGAN, which realizes model transfer by editing the intermediate latent codes $w$ in StyleGANs with learned constant offsets ($\Delta w$), discovering and constructing target latent spaces via simply relocating the distribution of source latent spaces. The established one-to-one mapping between latent spaces can naturally prevents mode collapse and overfitting. Besides, we also propose variants of WeditGAN to further enhance the relocation process by regularizing the direction or finetuning the intensity of $\Delta w$. Experiments on a collection of widely used source/target datasets manifest the capability of WeditGAN in generating realistic and diverse images, which is simple yet highly effective in the research area of few-shot image generation.
Diff-ID: An Explainable Identity Difference Quantification Framework for DeepFake Detection
Mar 30, 2023
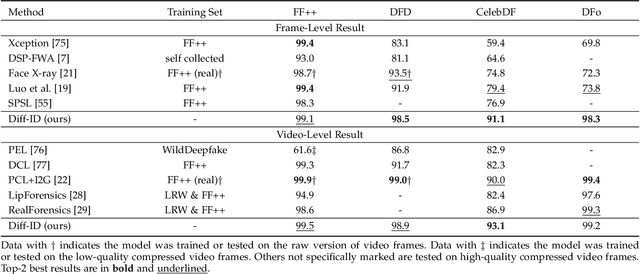


Despite the fact that DeepFake forgery detection algorithms have achieved impressive performance on known manipulations, they often face disastrous performance degradation when generalized to an unseen manipulation. Some recent works show improvement in generalization but rely on features fragile to image distortions such as compression. To this end, we propose Diff-ID, a concise and effective approach that explains and measures the identity loss induced by facial manipulations. When testing on an image of a specific person, Diff-ID utilizes an authentic image of that person as a reference and aligns them to the same identity-insensitive attribute feature space by applying a face-swapping generator. We then visualize the identity loss between the test and the reference image from the image differences of the aligned pairs, and design a custom metric to quantify the identity loss. The metric is then proved to be effective in distinguishing the forgery images from the real ones. Extensive experiments show that our approach achieves high detection performance on DeepFake images and state-of-the-art generalization ability to unknown forgery methods, while also being robust to image distortions.
Watch Out for the Confusing Faces: Detecting Face Swapping with the Probability Distribution of Face Identification Models
Mar 23, 2023


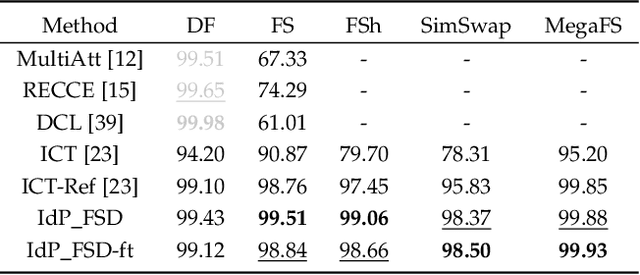
Recently, face swapping has been developing rapidly and achieved a surprising reality, raising concerns about fake content. As a countermeasure, various detection approaches have been proposed and achieved promising performance. However, most existing detectors struggle to maintain performance on unseen face swapping methods and low-quality images. Apart from the generalization problem, current detection approaches have been shown vulnerable to evasion attacks crafted by detection-aware manipulators. Lack of robustness under adversary scenarios leaves threats for applying face swapping detection in real world. In this paper, we propose a novel face swapping detection approach based on face identification probability distributions, coined as IdP_FSD, to improve the generalization and robustness. IdP_FSD is specially designed for detecting swapped faces whose identities belong to a finite set, which is meaningful in real-world applications. Compared with previous general detection methods, we make use of the available real faces with concerned identities and require no fake samples for training. IdP_FSD exploits face swapping's common nature that the identity of swapped face combines that of two faces involved in swapping. We reflect this nature with the confusion of a face identification model and measure the confusion with the maximum value of the output probability distribution. What's more, to defend our detector under adversary scenarios, an attention-based finetuning scheme is proposed for the face identification models used in IdP_FSD. Extensive experiments show that the proposed IdP_FSD not only achieves high detection performance on different benchmark datasets and image qualities but also raises the bar for manipulators to evade the detection.
Few-Shot Defect Image Generation via Defect-Aware Feature Manipulation
Mar 04, 2023The performances of defect inspection have been severely hindered by insufficient defect images in industries, which can be alleviated by generating more samples as data augmentation. We propose the first defect image generation method in the challenging few-shot cases. Given just a handful of defect images and relatively more defect-free ones, our goal is to augment the dataset with new defect images. Our method consists of two training stages. First, we train a data-efficient StyleGAN2 on defect-free images as the backbone. Second, we attach defect-aware residual blocks to the backbone, which learn to produce reasonable defect masks and accordingly manipulate the features within the masked regions by training the added modules on limited defect images. Extensive experiments on MVTec AD dataset not only validate the effectiveness of our method in generating realistic and diverse defect images, but also manifest the benefits it brings to downstream defect inspection tasks. Codes are available at https://github.com/Ldhlwh/DFMGAN.