 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiff-ID: An Explainable Identity Difference Quantification Framework for DeepFake Detection
Mar 30, 2023
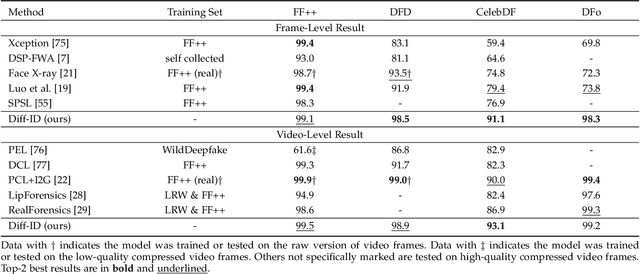


Despite the fact that DeepFake forgery detection algorithms have achieved impressive performance on known manipulations, they often face disastrous performance degradation when generalized to an unseen manipulation. Some recent works show improvement in generalization but rely on features fragile to image distortions such as compression. To this end, we propose Diff-ID, a concise and effective approach that explains and measures the identity loss induced by facial manipulations. When testing on an image of a specific person, Diff-ID utilizes an authentic image of that person as a reference and aligns them to the same identity-insensitive attribute feature space by applying a face-swapping generator. We then visualize the identity loss between the test and the reference image from the image differences of the aligned pairs, and design a custom metric to quantify the identity loss. The metric is then proved to be effective in distinguishing the forgery images from the real ones. Extensive experiments show that our approach achieves high detection performance on DeepFake images and state-of-the-art generalization ability to unknown forgery methods, while also being robust to image distortions.
WeakM3D: Towards Weakly Supervised Monocular 3D Object Detection
Mar 16, 2022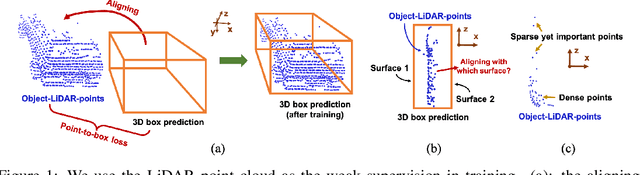
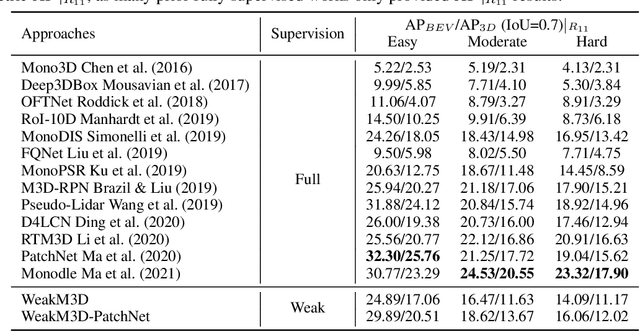
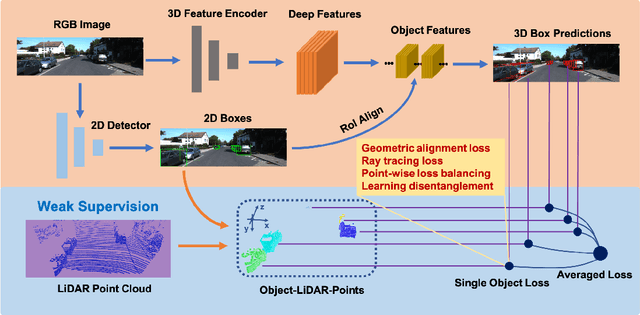

Monocular 3D object detection is one of the most challenging tasks in 3D scene understanding. Due to the ill-posed nature of monocular imagery, existing monocular 3D detection methods highly rely on training with the manually annotated 3D box labels on the LiDAR point clouds. This annotation process is very laborious and expensive. To dispense with the reliance on 3D box labels, in this paper we explore the weakly supervised monocular 3D detection. Specifically, we first detect 2D boxes on the image. Then, we adopt the generated 2D boxes to select corresponding RoI LiDAR points as the weak supervision. Eventually, we adopt a network to predict 3D boxes which can tightly align with associated RoI LiDAR points. This network is learned by minimizing our newly-proposed 3D alignment loss between the 3D box estimates and the corresponding RoI LiDAR points. We will illustrate the potential challenges of the above learning problem and resolve these challenges by introducing several effective designs into our method. Codes will be available at https://github.com/SPengLiang/WeakM3D.
Lidar Point Cloud Guided Monocular 3D Object Detection
Apr 19, 2021
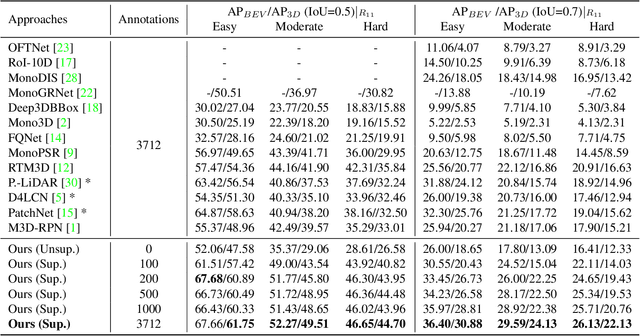
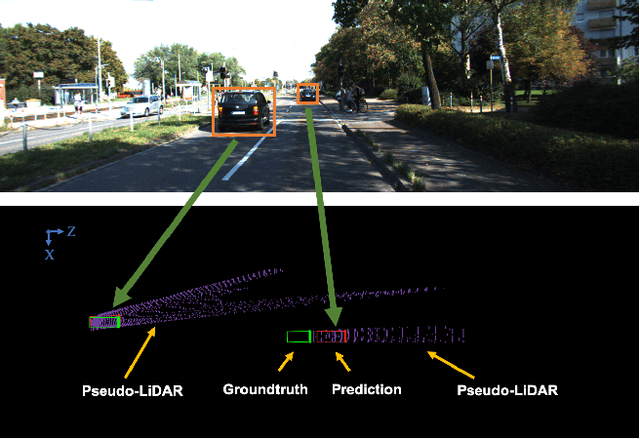
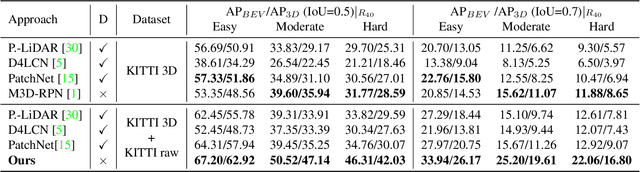
Monocular 3D object detection is drawing increasing attention from the community as it enables cars to perceive the world in 3D with a single camera. However, monocular 3D detection currently struggles with extremely lower detection rates compared to LiDAR-based methods, limiting its applications. The poor accuracy is mainly caused by the absence of accurate depth cues due to the ill-posed nature of monocular imagery. LiDAR point clouds, which provide accurate depth measurement, can offer beneficial information for the training of monocular methods. Prior works only use LiDAR point clouds to train a depth estimator. This implicit way does not fully utilize LiDAR point clouds, consequently leading to suboptimal performances. To effectively take advantage of LiDAR point clouds, in this paper we propose a general, simple yet effective framework for monocular methods. Specifically, we use LiDAR point clouds to directly guide the training of monocular 3D detectors, allowing them to learn desired objectives meanwhile eliminating the extra annotation cost. Thanks to the general design, our method can be plugged into any monocular 3D detection method, significantly boosting the performance. In conclusion, we take the first place on KITTI monocular 3D detection benchmark and increase the BEV/3D AP from 11.88/8.65 to 22.06/16.80 on the hard setting for the prior state-of-the-art method. The code will be made publicly available soon.
OCM3D: Object-Centric Monocular 3D Object Detection
Apr 13, 2021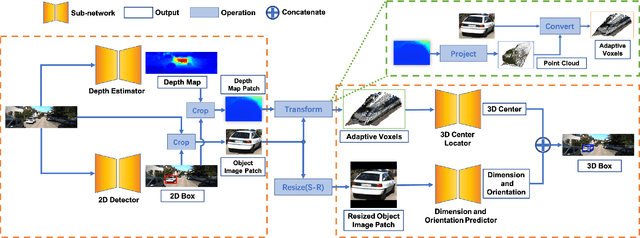
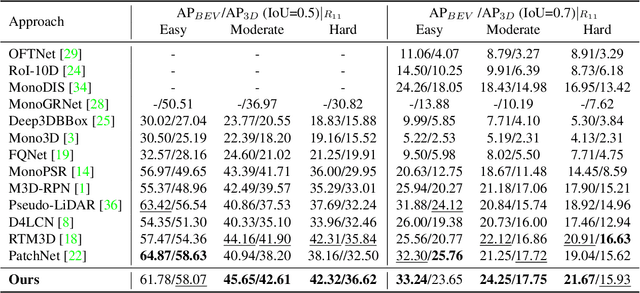
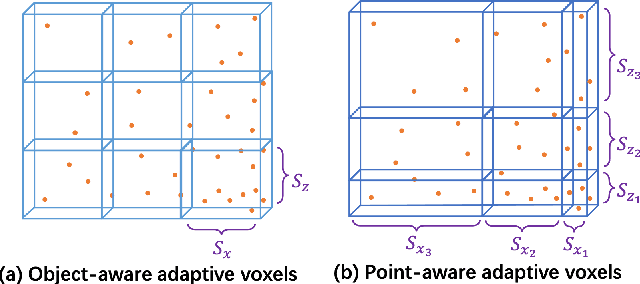

Image-only and pseudo-LiDAR representations are commonly used for monocular 3D object detection. However, methods based on them have shortcomings of either not well capturing the spatial relationships in neighbored image pixels or being hard to handle the noisy nature of the monocular pseudo-LiDAR point cloud. To overcome these issues, in this paper we propose a novel object-centric voxel representation tailored for monocular 3D object detection. Specifically, voxels are built on each object proposal, and their sizes are adaptively determined by the 3D spatial distribution of the points, allowing the noisy point cloud to be organized effectively within a voxel grid. This representation is proved to be able to locate the object in 3D space accurately. Furthermore, prior works would like to estimate the orientation via deep features extracted from an entire image or a noisy point cloud. By contrast, we argue that the local RoI information from the object image patch alone with a proper resizing scheme is a better input as it provides complete semantic clues meanwhile excludes irrelevant interferences. Besides, we decompose the confidence mechanism in monocular 3D object detection by considering the relationship between 3D objects and the associated 2D boxes. Evaluated on KITTI, our method outperforms state-of-the-art methods by a large margin. The code will be made publicly available soon.