 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Hallucinations in Video Large Language Models via Spatiotemporal-Semantic Contrastive Decoding
Jan 30, 2026Although Video Large Language Models perform remarkably well across tasks such as video understanding, question answering, and reasoning, they still suffer from the problem of hallucination, which refers to generating outputs that are inconsistent with explicit video content or factual evidence. However, existing decoding methods for mitigating video hallucinations, while considering the spatiotemporal characteristics of videos, mostly rely on heuristic designs. As a result, they fail to precisely capture the root causes of hallucinations and their fine-grained temporal and semantic correlations, leading to limited robustness and generalization in complex scenarios. To more effectively mitigate video hallucinations, we propose a novel decoding strategy termed Spatiotemporal-Semantic Contrastive Decoding. This strategy constructs negative features by deliberately disrupting the spatiotemporal consistency and semantic associations of video features, and suppresses video hallucinations through contrastive decoding against the original video features during inference. Extensive experiments demonstrate that our method not only effectively mitigates the occurrence of hallucinations, but also preserves the general video understanding and reasoning capabilities of the model.
VModA: An Effective Framework for Adaptive NSFW Image Moderation
May 29, 2025

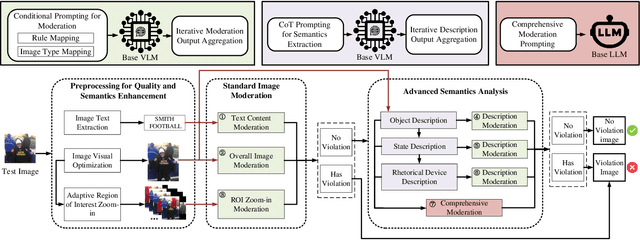
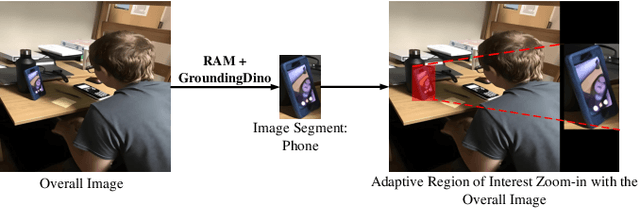
Not Safe/Suitable for Work (NSFW) content is rampant on social networks and poses serious harm to citizens, especially minors. Current detection methods mainly rely on deep learning-based image recognition and classification. However, NSFW images are now presented in increasingly sophisticated ways, often using image details and complex semantics to obscure their true nature or attract more views. Although still understandable to humans, these images often evade existing detection methods, posing a significant threat. Further complicating the issue, varying regulations across platforms and regions create additional challenges for effective moderation, leading to detection bias and reduced accuracy. To address this, we propose VModA, a general and effective framework that adapts to diverse moderation rules and handles complex, semantically rich NSFW content across categories. Experimental results show that VModA significantly outperforms existing methods, achieving up to a 54.3% accuracy improvement across NSFW types, including those with complex semantics. Further experiments demonstrate that our method exhibits strong adaptability across categories, scenarios, and base VLMs. We also identified inconsistent and controversial label samples in public NSFW benchmark datasets, re-annotated them, and submitted corrections to the original maintainers. Two datasets have confirmed the updates so far. Additionally, we evaluate VModA in real-world scenarios to demonstrate its practical effectiveness.
MentalMAC: Enhancing Large Language Models for Detecting Mental Manipulation via Multi-Task Anti-Curriculum Distillation
May 21, 2025Mental manipulation is a subtle yet pervasive form of psychological abuse that poses serious threats to mental health. Its covert nature and the complexity of manipulation strategies make it challenging to detect, even for state-of-the-art large language models (LLMs). This concealment also hinders the manual collection of large-scale, high-quality annotations essential for training effective models. Although recent efforts have sought to improve LLM's performance on this task, progress remains limited due to the scarcity of real-world annotated datasets. To address these challenges, we propose MentalMAC, a multi-task anti-curriculum distillation method that enhances LLMs' ability to detect mental manipulation in multi-turn dialogue. Our approach includes: (i) EvoSA, an unsupervised data expansion method based on evolutionary operations and speech act theory; (ii) teacher-model-generated multi-task supervision; and (iii) progressive knowledge distillation from complex to simpler tasks. We then constructed the ReaMent dataset with 5,000 real-world dialogue samples, using a MentalMAC-distilled model to assist human annotation. Vast experiments demonstrate that our method significantly narrows the gap between student and teacher models and outperforms competitive LLMs across key evaluation metrics. All code, datasets, and checkpoints will be released upon paper acceptance. Warning: This paper contains content that may be offensive to readers.
Could It Be Generated? Towards Practical Analysis of Memorization in Text-To-Image Diffusion Models
May 09, 2024



The past few years have witnessed substantial advancement in text-guided image generation powered by diffusion models. However, it was shown that text-to-image diffusion models are vulnerable to training image memorization, raising concerns on copyright infringement and privacy invasion. In this work, we perform practical analysis of memorization in text-to-image diffusion models. Targeting a set of images to protect, we conduct quantitive analysis on them without need to collect any prompts. Specifically, we first formally define the memorization of image and identify three necessary conditions of memorization, respectively similarity, existence and probability. We then reveal the correlation between the model's prediction error and image replication. Based on the correlation, we propose to utilize inversion techniques to verify the safety of target images against memorization and measure the extent to which they are memorized. Model developers can utilize our analysis method to discover memorized images or reliably claim safety against memorization. Extensive experiments on the Stable Diffusion, a popular open-source text-to-image diffusion model, demonstrate the effectiveness of our analysis method.
PRSA: Prompt Reverse Stealing Attacks against Large Language Models
Feb 29, 2024Prompt, recognized as crucial intellectual property, enables large language models (LLMs) to perform specific tasks without the need of fine-tuning, underscoring their escalating importance. With the rise of prompt-based services, such as prompt marketplaces and LLM applications, providers often display prompts' capabilities through input-output examples to attract users. However, this paradigm raises a pivotal security concern: does the exposure of input-output pairs pose the risk of potential prompt leakage, infringing on the intellectual property rights of the developers? To our knowledge, this problem still has not been comprehensively explored yet. To remedy this gap, in this paper, we perform the first in depth exploration and propose a novel attack framework for reverse-stealing prompts against commercial LLMs, namely PRSA. The main idea of PRSA is that by analyzing the critical features of the input-output pairs, we mimic and gradually infer (steal) the target prompts. In detail, PRSA mainly consists of two key phases: prompt mutation and prompt pruning. In the mutation phase, we propose a prompt attention algorithm based on differential feedback to capture these critical features for effectively inferring the target prompts. In the prompt pruning phase, we identify and mask the words dependent on specific inputs, enabling the prompts to accommodate diverse inputs for generalization. Through extensive evaluation, we verify that PRSA poses a severe threat in real world scenarios. We have reported these findings to prompt service providers and actively collaborate with them to take protective measures for prompt copyright.
Let All be Whitened: Multi-teacher Distillation for Efficient Visual Retrieval
Dec 15, 2023



Visual retrieval aims to search for the most relevant visual items, e.g., images and videos, from a candidate gallery with a given query item. Accuracy and efficiency are two competing objectives in retrieval tasks. Instead of crafting a new method pursuing further improvement on accuracy, in this paper we propose a multi-teacher distillation framework Whiten-MTD, which is able to transfer knowledge from off-the-shelf pre-trained retrieval models to a lightweight student model for efficient visual retrieval. Furthermore, we discover that the similarities obtained by different retrieval models are diversified and incommensurable, which makes it challenging to jointly distill knowledge from multiple models. Therefore, we propose to whiten the output of teacher models before fusion, which enables effective multi-teacher distillation for retrieval models. Whiten-MTD is conceptually simple and practically effective. Extensive experiments on two landmark image retrieval datasets and one video retrieval dataset demonstrate the effectiveness of our proposed method, and its good balance of retrieval performance and efficiency. Our source code is released at https://github.com/Maryeon/whiten_mtd.
Diff-ID: An Explainable Identity Difference Quantification Framework for DeepFake Detection
Mar 30, 2023
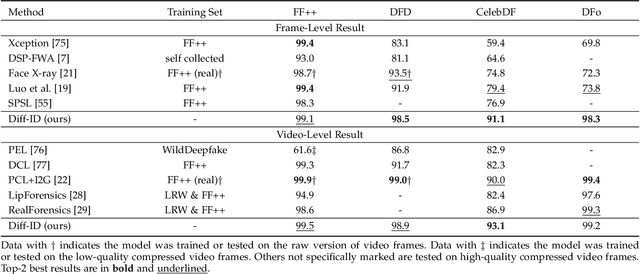


Despite the fact that DeepFake forgery detection algorithms have achieved impressive performance on known manipulations, they often face disastrous performance degradation when generalized to an unseen manipulation. Some recent works show improvement in generalization but rely on features fragile to image distortions such as compression. To this end, we propose Diff-ID, a concise and effective approach that explains and measures the identity loss induced by facial manipulations. When testing on an image of a specific person, Diff-ID utilizes an authentic image of that person as a reference and aligns them to the same identity-insensitive attribute feature space by applying a face-swapping generator. We then visualize the identity loss between the test and the reference image from the image differences of the aligned pairs, and design a custom metric to quantify the identity loss. The metric is then proved to be effective in distinguishing the forgery images from the real ones. Extensive experiments show that our approach achieves high detection performance on DeepFake images and state-of-the-art generalization ability to unknown forgery methods, while also being robust to image distortions.
Watch Out for the Confusing Faces: Detecting Face Swapping with the Probability Distribution of Face Identification Models
Mar 23, 2023


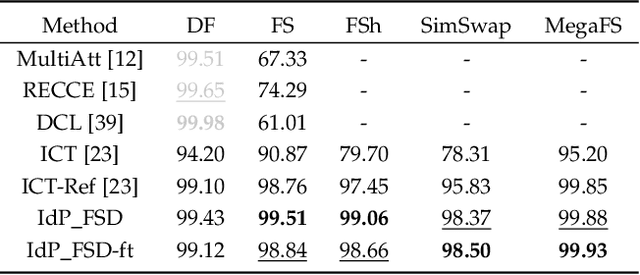
Recently, face swapping has been developing rapidly and achieved a surprising reality, raising concerns about fake content. As a countermeasure, various detection approaches have been proposed and achieved promising performance. However, most existing detectors struggle to maintain performance on unseen face swapping methods and low-quality images. Apart from the generalization problem, current detection approaches have been shown vulnerable to evasion attacks crafted by detection-aware manipulators. Lack of robustness under adversary scenarios leaves threats for applying face swapping detection in real world. In this paper, we propose a novel face swapping detection approach based on face identification probability distributions, coined as IdP_FSD, to improve the generalization and robustness. IdP_FSD is specially designed for detecting swapped faces whose identities belong to a finite set, which is meaningful in real-world applications. Compared with previous general detection methods, we make use of the available real faces with concerned identities and require no fake samples for training. IdP_FSD exploits face swapping's common nature that the identity of swapped face combines that of two faces involved in swapping. We reflect this nature with the confusion of a face identification model and measure the confusion with the maximum value of the output probability distribution. What's more, to defend our detector under adversary scenarios, an attention-based finetuning scheme is proposed for the face identification models used in IdP_FSD. Extensive experiments show that the proposed IdP_FSD not only achieves high detection performance on different benchmark datasets and image qualities but also raises the bar for manipulators to evade the detection.