 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReverB-SNN: Reversing Bit of the Weight and Activation for Spiking Neural Networks
Jun 09, 2025The Spiking Neural Network (SNN), a biologically inspired neural network infrastructure, has garnered significant attention recently. SNNs utilize binary spike activations for efficient information transmission, replacing multiplications with additions, thereby enhancing energy efficiency. However, binary spike activation maps often fail to capture sufficient data information, resulting in reduced accuracy. To address this challenge, we advocate reversing the bit of the weight and activation for SNNs, called \textbf{ReverB-SNN}, inspired by recent findings that highlight greater accuracy degradation from quantizing activations compared to weights. Specifically, our method employs real-valued spike activations alongside binary weights in SNNs. This preserves the event-driven and multiplication-free advantages of standard SNNs while enhancing the information capacity of activations. Additionally, we introduce a trainable factor within binary weights to adaptively learn suitable weight amplitudes during training, thereby increasing network capacity. To maintain efficiency akin to vanilla \textbf{ReverB-SNN}, our trainable binary weight SNNs are converted back to standard form using a re-parameterization technique during inference. Extensive experiments across various network architectures and datasets, both static and dynamic, demonstrate that our approach consistently outperforms state-of-the-art methods.
EDEN: Efficient Dual-Layer Exploration Planning for Fast UAV Autonomous Exploration in Large 3-D Environments
Jun 05, 2025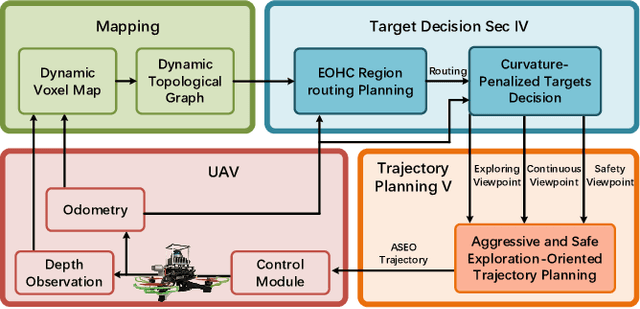
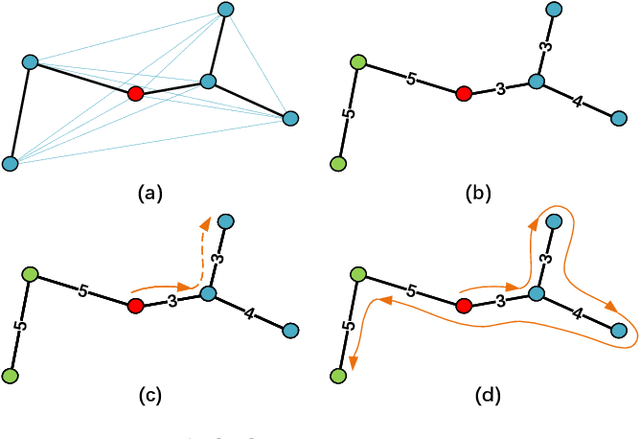
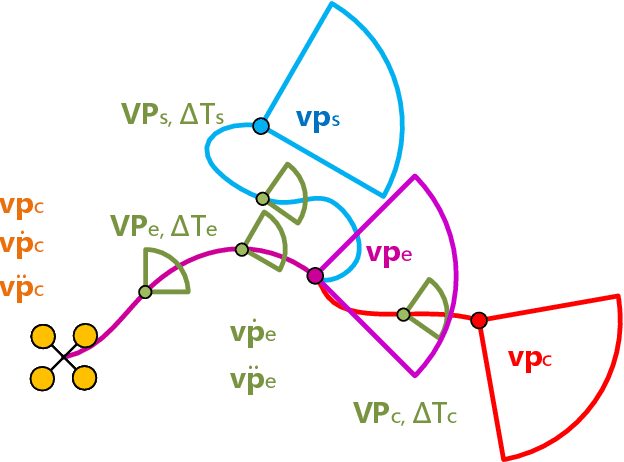

Efficient autonomous exploration in large-scale environments remains challenging due to the high planning computational cost and low-speed maneuvers. In this paper, we propose a fast and computationally efficient dual-layer exploration planning method. The insight of our dual-layer method is efficiently finding an acceptable long-term region routing and greedily exploring the target in the region of the first routing area with high speed. Specifically, the proposed method finds the long-term area routing through an approximate algorithm to ensure real-time planning in large-scale environments. Then, the viewpoint in the first routing region with the lowest curvature-penalized cost, which can effectively reduce decelerations caused by sharp turn motions, will be chosen as the next exploration target. To further speed up the exploration, we adopt an aggressive and safe exploration-oriented trajectory to enhance exploration continuity. The proposed method is compared to state-of-the-art methods in challenging simulation environments. The results show that the proposed method outperforms other methods in terms of exploration efficiency, computational cost, and trajectory speed. We also conduct real-world experiments to validate the effectiveness of the proposed method. The code will be open-sourced.
HuixiangDou2: A Robustly Optimized GraphRAG Approach
Mar 09, 2025Large Language Models (LLMs) perform well on familiar queries but struggle with specialized or emerging topics. Graph-based Retrieval-Augmented Generation (GraphRAG) addresses this by structuring domain knowledge as a graph for dynamic retrieval. However, existing pipelines involve complex engineering workflows, making it difficult to isolate the impact of individual components. Evaluating retrieval effectiveness is also challenging due to dataset overlap with LLM pretraining data. In this work, we introduce HuixiangDou2, a robustly optimized GraphRAG framework. Specifically, we leverage the effectiveness of dual-level retrieval and optimize its performance in a 32k context for maximum precision, and compare logic-based retrieval and dual-level retrieval to enhance overall functionality. Our implementation includes comparative experiments on a test set, where Qwen2.5-7B-Instruct initially underperformed. With our approach, the score improved significantly from 60 to 74.5, as illustrated in the Figure. Experiments on domain-specific datasets reveal that dual-level retrieval enhances fuzzy matching, while logic-form retrieval improves structured reasoning. Furthermore, we propose a multi-stage verification mechanism to improve retrieval robustness without increasing computational cost. Empirical results show significant accuracy gains over baselines, highlighting the importance of adaptive retrieval. To support research and adoption, we release HuixiangDou2 as an open-source resource https://github.com/tpoisonooo/huixiangdou2.
Improving Transformer Based Line Segment Detection with Matched Predicting and Re-ranking
Feb 25, 2025Classical Transformer-based line segment detection methods have delivered impressive results. However, we observe that some accurately detected line segments are assigned low confidence scores during prediction, causing them to be ranked lower and potentially suppressed. Additionally, these models often require prolonged training periods to achieve strong performance, largely due to the necessity of bipartite matching. In this paper, we introduce RANK-LETR, a novel Transformer-based line segment detection method. Our approach leverages learnable geometric information to refine the ranking of predicted line segments by enhancing the confidence scores of high-quality predictions in a posterior verification step. We also propose a new line segment proposal method, wherein the feature point nearest to the centroid of the line segment directly predicts the location, significantly improving training efficiency and stability. Moreover, we introduce a line segment ranking loss to stabilize rankings during training, thereby enhancing the generalization capability of the model. Experimental results demonstrate that our method outperforms other Transformer-based and CNN-based approaches in prediction accuracy while requiring fewer training epochs than previous Transformer-based models.
Navigating the Risks: A Survey of Security, Privacy, and Ethics Threats in LLM-Based Agents
Nov 14, 2024



With the continuous development of large language models (LLMs), transformer-based models have made groundbreaking advances in numerous natural language processing (NLP) tasks, leading to the emergence of a series of agents that use LLMs as their control hub. While LLMs have achieved success in various tasks, they face numerous security and privacy threats, which become even more severe in the agent scenarios. To enhance the reliability of LLM-based applications, a range of research has emerged to assess and mitigate these risks from different perspectives. To help researchers gain a comprehensive understanding of various risks, this survey collects and analyzes the different threats faced by these agents. To address the challenges posed by previous taxonomies in handling cross-module and cross-stage threats, we propose a novel taxonomy framework based on the sources and impacts. Additionally, we identify six key features of LLM-based agents, based on which we summarize the current research progress and analyze their limitations. Subsequently, we select four representative agents as case studies to analyze the risks they may face in practical use. Finally, based on the aforementioned analyses, we propose future research directions from the perspectives of data, methodology, and policy, respectively.
Safe Planner: Empowering Safety Awareness in Large Pre-Trained Models for Robot Task Planning
Nov 11, 2024
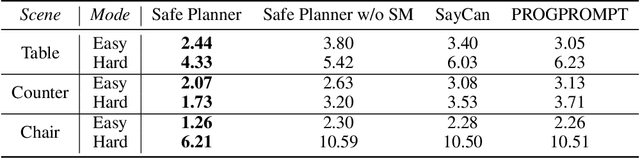
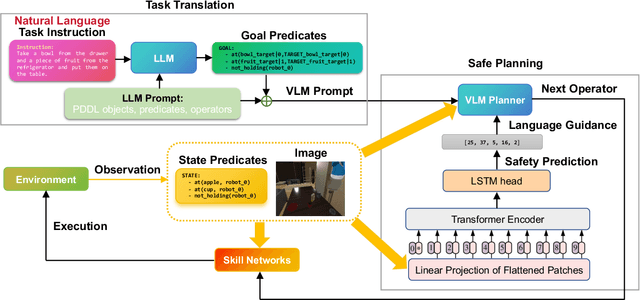
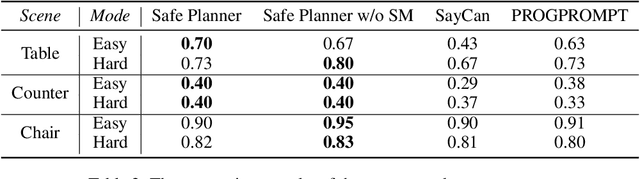
Robot task planning is an important problem for autonomous robots in long-horizon challenging tasks. As large pre-trained models have demonstrated superior planning ability, recent research investigates utilizing large models to achieve autonomous planning for robots in diverse tasks. However, since the large models are pre-trained with Internet data and lack the knowledge of real task scenes, large models as planners may make unsafe decisions that hurt the robots and the surrounding environments. To solve this challenge, we propose a novel Safe Planner framework, which empowers safety awareness in large pre-trained models to accomplish safe and executable planning. In this framework, we develop a safety prediction module to guide the high-level large model planner, and this safety module trained in a simulator can be effectively transferred to real-world tasks. The proposed Safe Planner framework is evaluated on both simulated environments and real robots. The experiment results demonstrate that Safe Planner not only achieves state-of-the-art task success rates, but also substantially improves safety during task execution. The experiment videos are shown in https://sites.google.com/view/safeplanner .
LLM-PySC2: Starcraft II learning environment for Large Language Models
Nov 08, 2024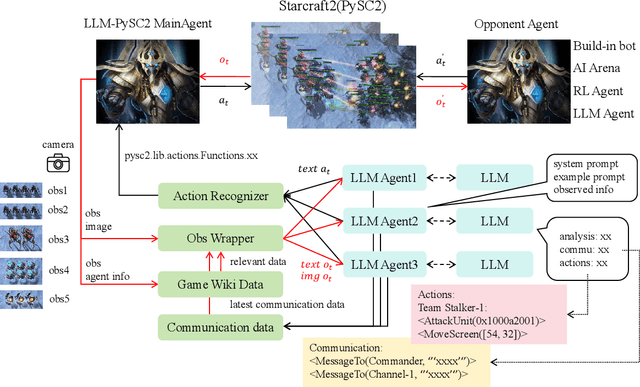
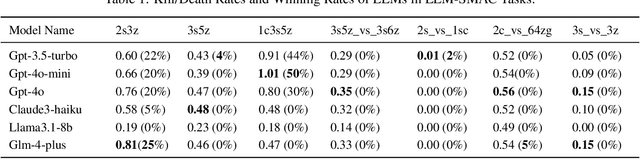
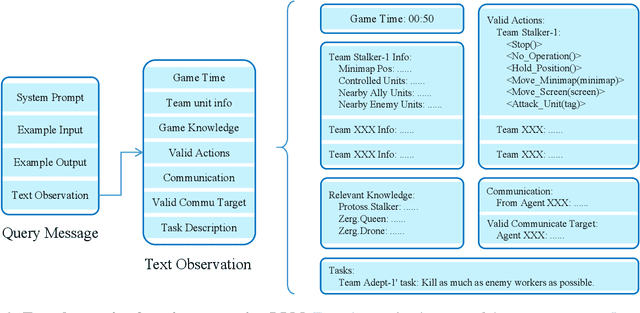

This paper introduces a new environment LLM-PySC2 (the Large Language Model StarCraft II Learning Environment), a platform derived from DeepMind's StarCraft II Learning Environment that serves to develop Large Language Models (LLMs) based decision-making methodologies. This environment is the first to offer the complete StarCraft II action space, multi-modal observation interfaces, and a structured game knowledge database, which are seamlessly connected with various LLMs to facilitate the research of LLMs-based decision-making. To further support multi-agent research, we developed an LLM collaborative framework that supports multi-agent concurrent queries and multi-agent communication. In our experiments, the LLM-PySC2 environment is adapted to be compatible with the StarCraft Multi-Agent Challenge (SMAC) task group and provided eight new scenarios focused on macro-decision abilities. We evaluated nine mainstream LLMs in the experiments, and results show that sufficient parameters are necessary for LLMs to make decisions, but improving reasoning ability does not directly lead to better decision-making outcomes. Our findings further indicate the importance of enabling large models to learn autonomously in the deployment environment through parameter training or train-free learning techniques. Ultimately, we expect that the LLM-PySC2 environment can promote research on learning methods for LLMs, helping LLM-based methods better adapt to task scenarios.
Could It Be Generated? Towards Practical Analysis of Memorization in Text-To-Image Diffusion Models
May 09, 2024



The past few years have witnessed substantial advancement in text-guided image generation powered by diffusion models. However, it was shown that text-to-image diffusion models are vulnerable to training image memorization, raising concerns on copyright infringement and privacy invasion. In this work, we perform practical analysis of memorization in text-to-image diffusion models. Targeting a set of images to protect, we conduct quantitive analysis on them without need to collect any prompts. Specifically, we first formally define the memorization of image and identify three necessary conditions of memorization, respectively similarity, existence and probability. We then reveal the correlation between the model's prediction error and image replication. Based on the correlation, we propose to utilize inversion techniques to verify the safety of target images against memorization and measure the extent to which they are memorized. Model developers can utilize our analysis method to discover memorized images or reliably claim safety against memorization. Extensive experiments on the Stable Diffusion, a popular open-source text-to-image diffusion model, demonstrate the effectiveness of our analysis method.
Ternary Spike: Learning Ternary Spikes for Spiking Neural Networks
Dec 17, 2023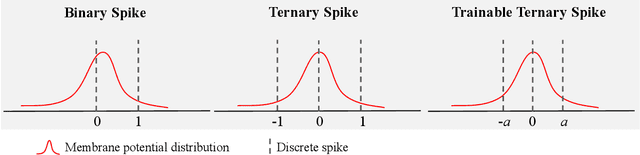
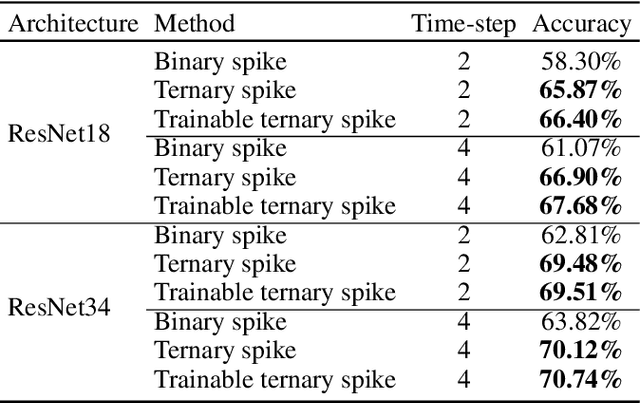
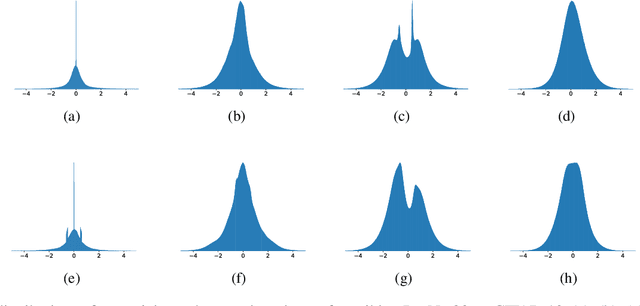
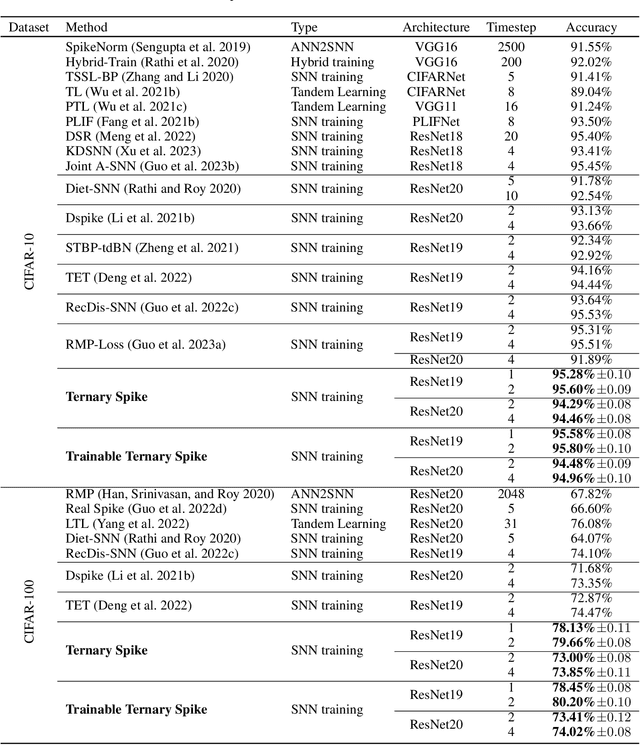
The Spiking Neural Network (SNN), as one of the biologically inspired neural network infrastructures, has drawn increasing attention recently. It adopts binary spike activations to transmit information, thus the multiplications of activations and weights can be substituted by additions, which brings high energy efficiency. However, in the paper, we theoretically and experimentally prove that the binary spike activation map cannot carry enough information, thus causing information loss and resulting in accuracy decreasing. To handle the problem, we propose a ternary spike neuron to transmit information. The ternary spike neuron can also enjoy the event-driven and multiplication-free operation advantages of the binary spike neuron but will boost the information capacity. Furthermore, we also embed a trainable factor in the ternary spike neuron to learn the suitable spike amplitude, thus our SNN will adopt different spike amplitudes along layers, which can better suit the phenomenon that the membrane potential distributions are different along layers. To retain the efficiency of the vanilla ternary spike, the trainable ternary spike SNN will be converted to a standard one again via a re-parameterization technique in the inference. Extensive experiments with several popular network structures over static and dynamic datasets show that the ternary spike can consistently outperform state-of-the-art methods. Our code is open-sourced at https://github.com/yfguo91/Ternary-Spike.
Let All be Whitened: Multi-teacher Distillation for Efficient Visual Retrieval
Dec 15, 2023



Visual retrieval aims to search for the most relevant visual items, e.g., images and videos, from a candidate gallery with a given query item. Accuracy and efficiency are two competing objectives in retrieval tasks. Instead of crafting a new method pursuing further improvement on accuracy, in this paper we propose a multi-teacher distillation framework Whiten-MTD, which is able to transfer knowledge from off-the-shelf pre-trained retrieval models to a lightweight student model for efficient visual retrieval. Furthermore, we discover that the similarities obtained by different retrieval models are diversified and incommensurable, which makes it challenging to jointly distill knowledge from multiple models. Therefore, we propose to whiten the output of teacher models before fusion, which enables effective multi-teacher distillation for retrieval models. Whiten-MTD is conceptually simple and practically effective. Extensive experiments on two landmark image retrieval datasets and one video retrieval dataset demonstrate the effectiveness of our proposed method, and its good balance of retrieval performance and efficiency. Our source code is released at https://github.com/Maryeon/whiten_mtd.