 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuroBreak: Unveil Internal Jailbreak Mechanisms in Large Language Models
Sep 04, 2025In deployment and application, large language models (LLMs) typically undergo safety alignment to prevent illegal and unethical outputs. However, the continuous advancement of jailbreak attack techniques, designed to bypass safety mechanisms with adversarial prompts, has placed increasing pressure on the security defenses of LLMs. Strengthening resistance to jailbreak attacks requires an in-depth understanding of the security mechanisms and vulnerabilities of LLMs. However, the vast number of parameters and complex structure of LLMs make analyzing security weaknesses from an internal perspective a challenging task. This paper presents NeuroBreak, a top-down jailbreak analysis system designed to analyze neuron-level safety mechanisms and mitigate vulnerabilities. We carefully design system requirements through collaboration with three experts in the field of AI security. The system provides a comprehensive analysis of various jailbreak attack methods. By incorporating layer-wise representation probing analysis, NeuroBreak offers a novel perspective on the model's decision-making process throughout its generation steps. Furthermore, the system supports the analysis of critical neurons from both semantic and functional perspectives, facilitating a deeper exploration of security mechanisms. We conduct quantitative evaluations and case studies to verify the effectiveness of our system, offering mechanistic insights for developing next-generation defense strategies against evolving jailbreak attacks.
Navigating the Risks: A Survey of Security, Privacy, and Ethics Threats in LLM-Based Agents
Nov 14, 2024



With the continuous development of large language models (LLMs), transformer-based models have made groundbreaking advances in numerous natural language processing (NLP) tasks, leading to the emergence of a series of agents that use LLMs as their control hub. While LLMs have achieved success in various tasks, they face numerous security and privacy threats, which become even more severe in the agent scenarios. To enhance the reliability of LLM-based applications, a range of research has emerged to assess and mitigate these risks from different perspectives. To help researchers gain a comprehensive understanding of various risks, this survey collects and analyzes the different threats faced by these agents. To address the challenges posed by previous taxonomies in handling cross-module and cross-stage threats, we propose a novel taxonomy framework based on the sources and impacts. Additionally, we identify six key features of LLM-based agents, based on which we summarize the current research progress and analyze their limitations. Subsequently, we select four representative agents as case studies to analyze the risks they may face in practical use. Finally, based on the aforementioned analyses, we propose future research directions from the perspectives of data, methodology, and policy, respectively.
"Is your explanation stable?": A Robustness Evaluation Framework for Feature Attribution
Sep 05, 2022
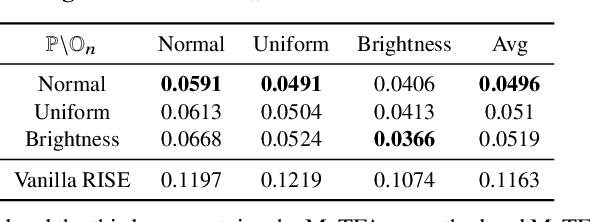
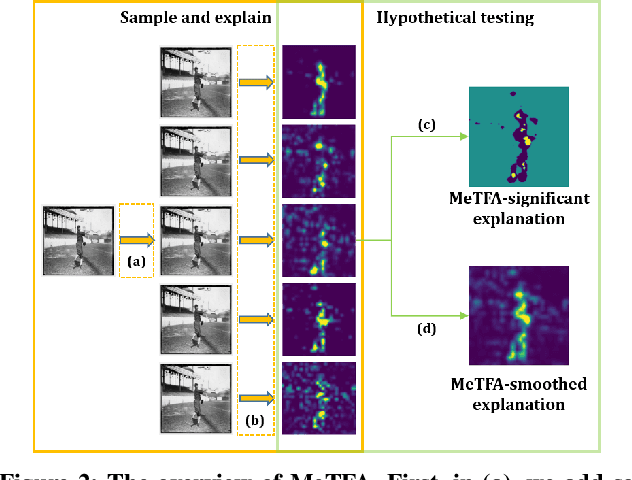
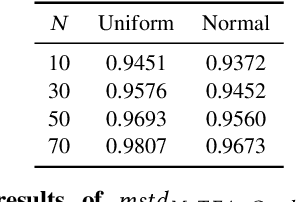
Understanding the decision process of neural networks is hard. One vital method for explanation is to attribute its decision to pivotal features. Although many algorithms are proposed, most of them solely improve the faithfulness to the model. However, the real environment contains many random noises, which may leads to great fluctuations in the explanations. More seriously, recent works show that explanation algorithms are vulnerable to adversarial attacks. All of these make the explanation hard to trust in real scenarios. To bridge this gap, we propose a model-agnostic method \emph{Median Test for Feature Attribution} (MeTFA) to quantify the uncertainty and increase the stability of explanation algorithms with theoretical guarantees. MeTFA has the following two functions: (1) examine whether one feature is significantly important or unimportant and generate a MeTFA-significant map to visualize the results; (2) compute the confidence interval of a feature attribution score and generate a MeTFA-smoothed map to increase the stability of the explanation. Experiments show that MeTFA improves the visual quality of explanations and significantly reduces the instability while maintaining the faithfulness. To quantitatively evaluate the faithfulness of an explanation under different noise settings, we further propose several robust faithfulness metrics. Experiment results show that the MeTFA-smoothed explanation can significantly increase the robust faithfulness. In addition, we use two scenarios to show MeTFA's potential in the applications. First, when applied to the SOTA explanation method to locate context bias for semantic segmentation models, MeTFA-significant explanations use far smaller regions to maintain 99\%+ faithfulness. Second, when tested with different explanation-oriented attacks, MeTFA can help defend vanilla, as well as adaptive, adversarial attacks against explanations.