 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
Breaking the Overscaling Curse: Thinking Parallelism Before Parallel Thinking
Jan 29, 2026Parallel thinking enhances LLM reasoning by multi-path sampling and aggregation. In system-level evaluations, a global parallelism level N is allocated to all samples, typically set large to maximize overall dataset accuracy. However, due to sample heterogeneity, some samples can achieve comparable performance with a smaller N'< N, causing budget redundancy. This incompatibility between system-level efficacy and sample-level efficiency constitutes the overscaling curse. In this paper, we formalize and quantify the overscaling curse, showing its universality and severity in practice, and analyze its trigger mechanism. We then propose a lightweight method, T2, to break the overscaling curse, which utilizes latent representations to estimate the optimal parallelism level for each sample before decoding. Experiments show that T2 significantly reduces cost while maintaining comparable performance, enabling more efficient parallel thinking.
ExoGS: A 4D Real-to-Sim-to-Real Framework for Scalable Manipulation Data Collection
Jan 26, 2026Real-to-Sim-to-Real technique is gaining increasing interest for robotic manipulation, as it can generate scalable data in simulation while having narrower sim-to-real gap. However, previous methods mainly focused on environment-level visual real-to-sim transfer, ignoring the transfer of interactions, which could be challenging and inefficient to obtain purely in simulation especially for contact-rich tasks. We propose ExoGS, a robot-free 4D Real-to-Sim-to-Real framework that captures both static environments and dynamic interactions in the real world and transfers them seamlessly to a simulated environment. It provides a new solution for scalable manipulation data collection and policy learning. ExoGS employs a self-designed robot-isomorphic passive exoskeleton AirExo-3 to capture kinematically consistent trajectories with millimeter-level accuracy and synchronized RGB observations during direct human demonstrations. The robot, objects, and environment are reconstructed as editable 3D Gaussian Splatting assets, enabling geometry-consistent replay and large-scale data augmentation. Additionally, a lightweight Mask Adapter injects instance-level semantics into the policy to enhance robustness under visual domain shifts. Real-world experiments demonstrate that ExoGS significantly improves data efficiency and policy generalization compared to teleoperation-based baselines. Code and hardware files have been released on https://github.com/zaixiabalala/ExoGS.
Semantic-Guided Unsupervised Video Summarization
Jan 21, 2026Video summarization is a crucial technique for social understanding, enabling efficient browsing of massive multimedia content and extraction of key information from social platforms. Most existing unsupervised summarization methods rely on Generative Adversarial Networks (GANs) to enhance keyframe selection and generate coherent, video summaries through adversarial training. However, such approaches primarily exploit unimodal features, overlooking the guiding role of semantic information in keyframe selection, and often suffer from unstable training. To address these limitations, we propose a novel Semantic-Guided Unsupervised Video Summarization method. Specifically, we design a novel frame-level semantic alignment attention mechanism and integrate it into a keyframe selector, which guides the Transformer-based generator within the adversarial framework to better reconstruct videos. In addition, we adopt an incremental training strategy to progressively update the model components, effectively mitigating the instability of GAN training. Experimental results demonstrate that our approach achieves superior performance on multiple benchmark datasets.
Spherical Geometry Diffusion: Generating High-quality 3D Face Geometry via Sphere-anchored Representations
Jan 19, 2026A fundamental challenge in text-to-3D face generation is achieving high-quality geometry. The core difficulty lies in the arbitrary and intricate distribution of vertices in 3D space, making it challenging for existing models to establish clean connectivity and resulting in suboptimal geometry. To address this, our core insight is to simplify the underlying geometric structure by constraining the distribution onto a simple and regular manifold, a topological sphere. Building on this, we first propose the Spherical Geometry Representation, a novel face representation that anchors geometric signals to uniform spherical coordinates. This guarantees a regular point distribution, from which the mesh connectivity can be robustly reconstructed. Critically, this canonical sphere can be seamlessly unwrapped into a 2D map, creating a perfect synergy with powerful 2D generative models. We then introduce Spherical Geometry Diffusion, a conditional diffusion framework built upon this 2D map. It enables diverse and controllable generation by jointly modeling geometry and texture, where the geometry explicitly conditions the texture synthesis process. Our method's effectiveness is demonstrated through its success in a wide range of tasks: text-to-3D generation, face reconstruction, and text-based 3D editing. Extensive experiments show that our approach substantially outperforms existing methods in geometric quality, textual fidelity, and inference efficiency.
Unifying Speech Recognition, Synthesis and Conversion with Autoregressive Transformers
Jan 15, 2026Traditional speech systems typically rely on separate, task-specific models for text-to-speech (TTS), automatic speech recognition (ASR), and voice conversion (VC), resulting in fragmented pipelines that limit scalability, efficiency, and cross-task generalization. In this paper, we present General-Purpose Audio (GPA), a unified audio foundation model that integrates multiple core speech tasks within a single large language model (LLM) architecture. GPA operates on a shared discrete audio token space and supports instruction-driven task induction, enabling a single autoregressive model to flexibly perform TTS, ASR, and VC without architectural modifications. This unified design combines a fully autoregressive formulation over discrete speech tokens, joint multi-task training across speech domains, and a scalable inference pipeline that achieves high concurrency and throughput. The resulting model family supports efficient multi-scale deployment, including a lightweight 0.3B-parameter variant optimized for edge and resource-constrained environments. Together, these design choices demonstrate that a unified autoregressive architecture can achieve competitive performance across diverse speech tasks while remaining viable for low-latency, practical deployment.
PALM-Bench: A Comprehensive Benchmark for Personalized Audio-Language Models
Jan 07, 2026Large Audio-Language Models (LALMs) have demonstrated strong performance in audio understanding and generation. Yet, our extensive benchmarking reveals that their behavior is largely generic (e.g., summarizing spoken content) and fails to adequately support personalized question answering (e.g., summarizing what my best friend says). In contrast, human conditions their interpretation and decision-making on each individual's personal context. To bridge this gap, we formalize the task of Personalized LALMs (PALM) for recognizing personal concepts and reasoning within personal context. Moreover, we create the first benchmark (PALM-Bench) to foster the methodological advances in PALM and enable structured evaluation on several tasks across multi-speaker scenarios. Our extensive experiments on representative open-source LALMs, show that existing training-free prompting and supervised fine-tuning strategies, while yield improvements, remains limited in modeling personalized knowledge and transferring them across tasks robustly. Data and code will be released.
PhysSFI-Net: Physics-informed Geometric Learning of Skeletal and Facial Interactions for Orthognathic Surgical Outcome Prediction
Jan 06, 2026Orthognathic surgery repositions jaw bones to restore occlusion and enhance facial aesthetics. Accurate simulation of postoperative facial morphology is essential for preoperative planning. However, traditional biomechanical models are computationally expensive, while geometric deep learning approaches often lack interpretability. In this study, we develop and validate a physics-informed geometric deep learning framework named PhysSFI-Net for precise prediction of soft tissue deformation following orthognathic surgery. PhysSFI-Net consists of three components: a hierarchical graph module with craniofacial and surgical plan encoders combined with attention mechanisms to extract skeletal-facial interaction features; a Long Short-Term Memory (LSTM)-based sequential predictor for incremental soft tissue deformation; and a biomechanics-inspired module for high-resolution facial surface reconstruction. Model performance was assessed using point cloud shape error (Hausdorff distance), surface deviation error, and landmark localization error (Euclidean distances of craniomaxillofacial landmarks) between predicted facial shapes and corresponding ground truths. A total of 135 patients who underwent combined orthodontic and orthognathic treatment were included for model training and validation. Quantitative analysis demonstrated that PhysSFI-Net achieved a point cloud shape error of 1.070 +/- 0.088 mm, a surface deviation error of 1.296 +/- 0.349 mm, and a landmark localization error of 2.445 +/- 1.326 mm. Comparative experiments indicated that PhysSFI-Net outperformed the state-of-the-art method ACMT-Net in prediction accuracy. In conclusion, PhysSFI-Net enables interpretable, high-resolution prediction of postoperative facial morphology with superior accuracy, showing strong potential for clinical application in orthognathic surgical planning and simulation.
RGMP: Recurrent Geometric-prior Multimodal Policy for Generalizable Humanoid Robot Manipulation
Nov 12, 2025Humanoid robots exhibit significant potential in executing diverse human-level skills. However, current research predominantly relies on data-driven approaches that necessitate extensive training datasets to achieve robust multimodal decision-making capabilities and generalizable visuomotor control. These methods raise concerns due to the neglect of geometric reasoning in unseen scenarios and the inefficient modeling of robot-target relationships within the training data, resulting in significant waste of training resources. To address these limitations, we present the Recurrent Geometric-prior Multimodal Policy (RGMP), an end-to-end framework that unifies geometric-semantic skill reasoning with data-efficient visuomotor control. For perception capabilities, we propose the Geometric-prior Skill Selector, which infuses geometric inductive biases into a vision language model, producing adaptive skill sequences for unseen scenes with minimal spatial common sense tuning. To achieve data-efficient robotic motion synthesis, we introduce the Adaptive Recursive Gaussian Network, which parameterizes robot-object interactions as a compact hierarchy of Gaussian processes that recursively encode multi-scale spatial relationships, yielding dexterous, data-efficient motion synthesis even from sparse demonstrations. Evaluated on both our humanoid robot and desktop dual-arm robot, the RGMP framework achieves 87% task success in generalization tests and exhibits 5x greater data efficiency than the state-of-the-art model. This performance underscores its superior cross-domain generalization, enabled by geometric-semantic reasoning and recursive-Gaussion adaptation.
LLMs as Scalable, General-Purpose Simulators For Evolving Digital Agent Training
Oct 16, 2025
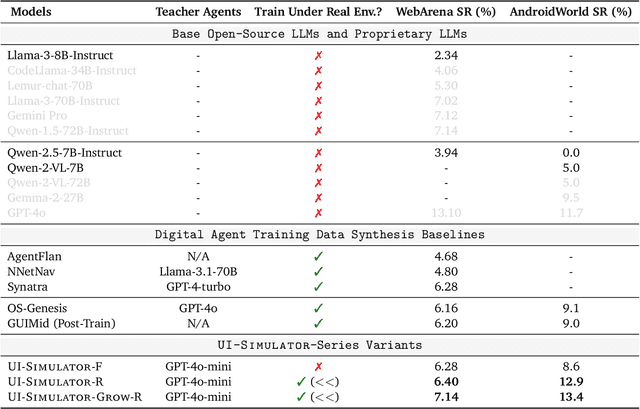

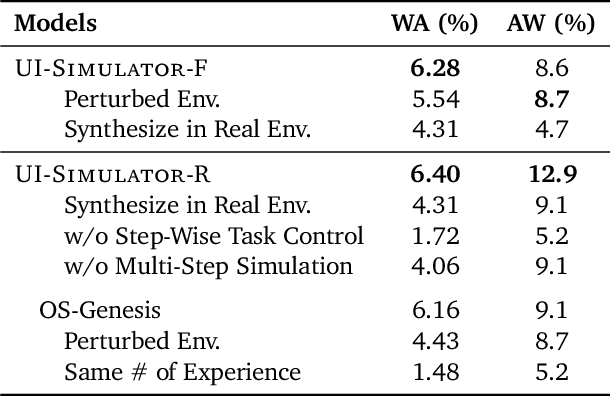
Digital agents require diverse, large-scale UI trajectories to generalize across real-world tasks, yet collecting such data is prohibitively expensive in both human annotation, infra and engineering perspectives. To this end, we introduce $\textbf{UI-Simulator}$, a scalable paradigm that generates structured UI states and transitions to synthesize training trajectories at scale. Our paradigm integrates a digital world simulator for diverse UI states, a guided rollout process for coherent exploration, and a trajectory wrapper that produces high-quality and diverse trajectories for agent training. We further propose $\textbf{UI-Simulator-Grow}$, a targeted scaling strategy that enables more rapid and data-efficient scaling by prioritizing high-impact tasks and synthesizes informative trajectory variants. Experiments on WebArena and AndroidWorld show that UI-Simulator rivals or surpasses open-source agents trained on real UIs with significantly better robustness, despite using weaker teacher models. Moreover, UI-Simulator-Grow matches the performance of Llama-3-70B-Instruct using only Llama-3-8B-Instruct as the base model, highlighting the potential of targeted synthesis scaling paradigm to continuously and efficiently enhance the digital agents.