 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasked Clustering Prediction for Unsupervised Point Cloud Pre-training
Aug 12, 2025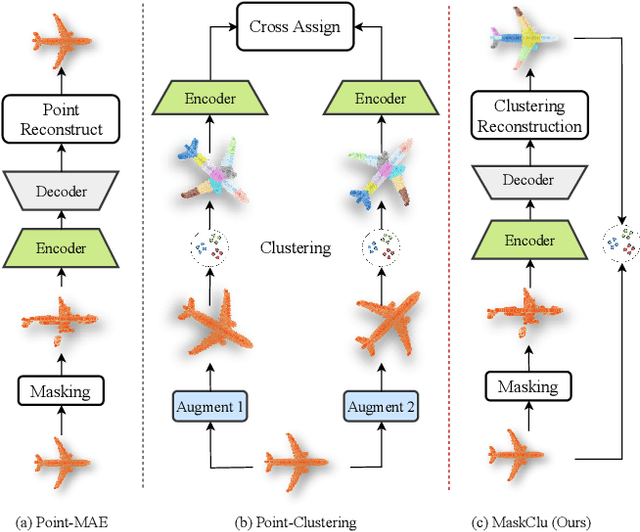
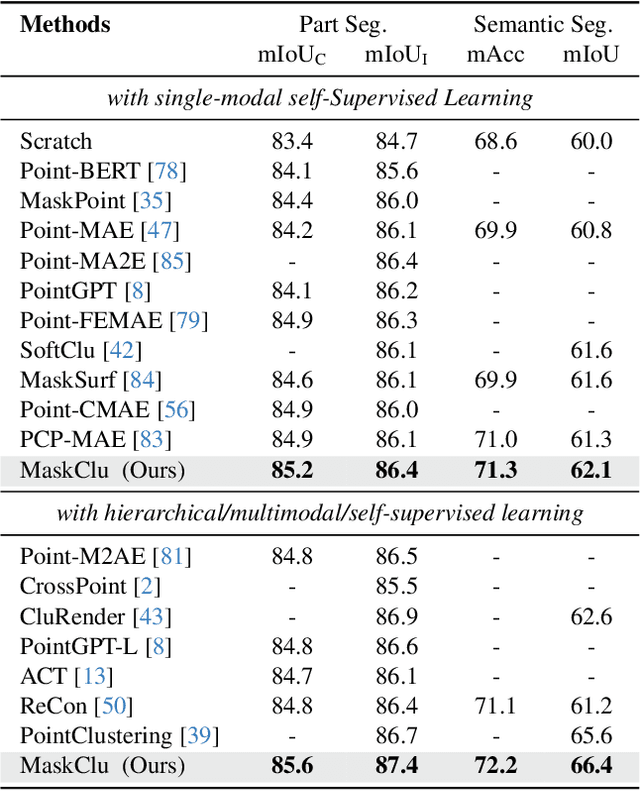
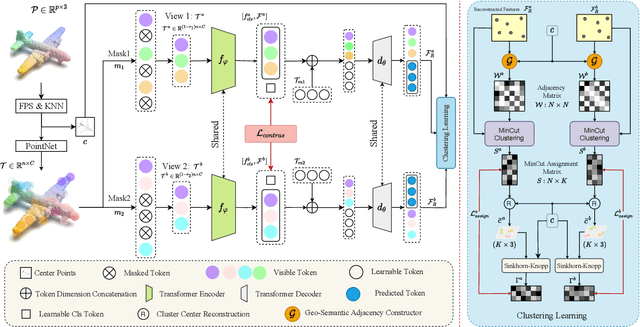
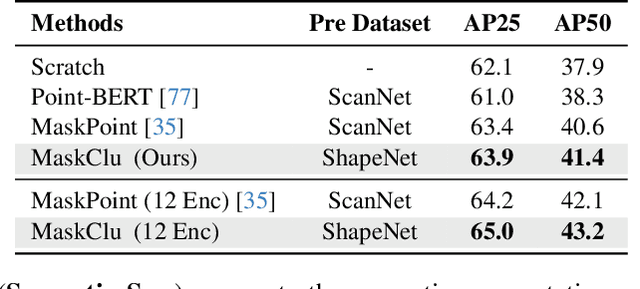
Vision transformers (ViTs) have recently been widely applied to 3D point cloud understanding, with masked autoencoding as the predominant pre-training paradigm. However, the challenge of learning dense and informative semantic features from point clouds via standard ViTs remains underexplored. We propose MaskClu, a novel unsupervised pre-training method for ViTs on 3D point clouds that integrates masked point modeling with clustering-based learning. MaskClu is designed to reconstruct both cluster assignments and cluster centers from masked point clouds, thus encouraging the model to capture dense semantic information. Additionally, we introduce a global contrastive learning mechanism that enhances instance-level feature learning by contrasting different masked views of the same point cloud. By jointly optimizing these complementary objectives, i.e., dense semantic reconstruction, and instance-level contrastive learning. MaskClu enables ViTs to learn richer and more semantically meaningful representations from 3D point clouds. We validate the effectiveness of our method via multiple 3D tasks, including part segmentation, semantic segmentation, object detection, and classification, where MaskClu sets new competitive results. The code and models will be released at:https://github.com/Amazingren/maskclu.
Self-Supervised and Generalizable Tokenization for CLIP-Based 3D Understanding
May 24, 2025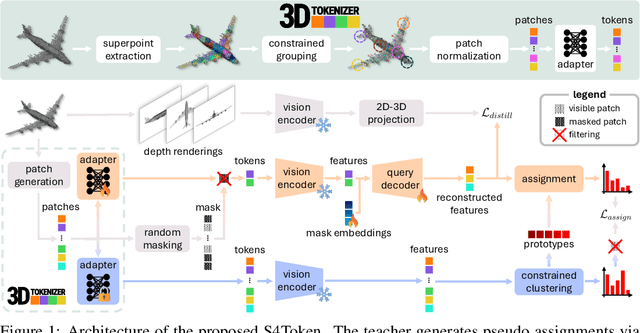


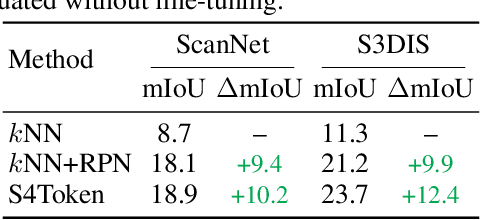
Vision-language models like CLIP can offer a promising foundation for 3D scene understanding when extended with 3D tokenizers. However, standard approaches, such as k-nearest neighbor or radius-based tokenization, struggle with cross-domain generalization due to sensitivity to dataset-specific spatial scales. We present a universal 3D tokenizer designed for scale-invariant representation learning with a frozen CLIP backbone. We show that combining superpoint-based grouping with coordinate scale normalization consistently outperforms conventional methods through extensive experimental analysis. Specifically, we introduce S4Token, a tokenization pipeline that produces semantically-informed tokens regardless of scene scale. Our tokenizer is trained without annotations using masked point modeling and clustering-based objectives, along with cross-modal distillation to align 3D tokens with 2D multi-view image features. For dense prediction tasks, we propose a superpoint-level feature propagation module to recover point-level detail from sparse tokens.
Adversarial Robustness for Unified Multi-Modal Encoders via Efficient Calibration
May 17, 2025Recent unified multi-modal encoders align a wide range of modalities into a shared representation space, enabling diverse cross-modal tasks. Despite their impressive capabilities, the robustness of these models under adversarial perturbations remains underexplored, which is a critical concern for safety-sensitive applications. In this work, we present the first comprehensive study of adversarial vulnerability in unified multi-modal encoders. We find that even mild adversarial perturbations lead to substantial performance drops across all modalities. Non-visual inputs, such as audio and point clouds, are especially fragile, while visual inputs like images and videos also degrade significantly. To address this, we propose an efficient adversarial calibration framework that improves robustness across modalities without modifying pretrained encoders or semantic centers, ensuring compatibility with existing foundation models. Our method introduces modality-specific projection heads trained solely on adversarial examples, while keeping the backbone and embeddings frozen. We explore three training objectives: fixed-center cross-entropy, clean-to-adversarial L2 alignment, and clean-adversarial InfoNCE, and we introduce a regularization strategy to ensure modality-consistent alignment under attack. Experiments on six modalities and three Bind-style models show that our method improves adversarial robustness by up to 47.3 percent at epsilon = 4/255, while preserving or even improving clean zero-shot and retrieval performance with less than 1 percent trainable parameters.
Free-form language-based robotic reasoning and grasping
Mar 17, 2025
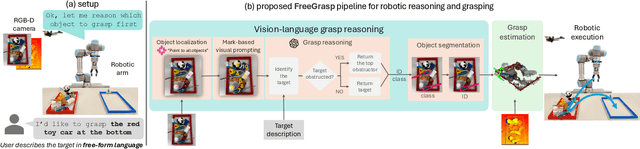


Performing robotic grasping from a cluttered bin based on human instructions is a challenging task, as it requires understanding both the nuances of free-form language and the spatial relationships between objects. Vision-Language Models (VLMs) trained on web-scale data, such as GPT-4o, have demonstrated remarkable reasoning capabilities across both text and images. But can they truly be used for this task in a zero-shot setting? And what are their limitations? In this paper, we explore these research questions via the free-form language-based robotic grasping task, and propose a novel method, FreeGrasp, leveraging the pre-trained VLMs' world knowledge to reason about human instructions and object spatial arrangements. Our method detects all objects as keypoints and uses these keypoints to annotate marks on images, aiming to facilitate GPT-4o's zero-shot spatial reasoning. This allows our method to determine whether a requested object is directly graspable or if other objects must be grasped and removed first. Since no existing dataset is specifically designed for this task, we introduce a synthetic dataset FreeGraspData by extending the MetaGraspNetV2 dataset with human-annotated instructions and ground-truth grasping sequences. We conduct extensive analyses with both FreeGraspData and real-world validation with a gripper-equipped robotic arm, demonstrating state-of-the-art performance in grasp reasoning and execution. Project website: https://tev-fbk.github.io/FreeGrasp/.
Fully-Geometric Cross-Attention for Point Cloud Registration
Feb 12, 2025Point cloud registration approaches often fail when the overlap between point clouds is low due to noisy point correspondences. This work introduces a novel cross-attention mechanism tailored for Transformer-based architectures that tackles this problem, by fusing information from coordinates and features at the super-point level between point clouds. This formulation has remained unexplored primarily because it must guarantee rotation and translation invariance since point clouds reside in different and independent reference frames. We integrate the Gromov-Wasserstein distance into the cross-attention formulation to jointly compute distances between points across different point clouds and account for their geometric structure. By doing so, points from two distinct point clouds can attend to each other under arbitrary rigid transformations. At the point level, we also devise a self-attention mechanism that aggregates the local geometric structure information into point features for fine matching. Our formulation boosts the number of inlier correspondences, thereby yielding more precise registration results compared to state-of-the-art approaches. We have conducted an extensive evaluation on 3DMatch, 3DLoMatch, KITTI, and 3DCSR datasets.
PerLA: Perceptive 3D Language Assistant
Nov 29, 2024
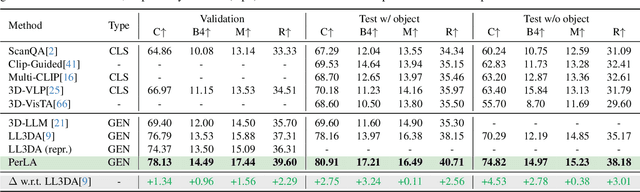
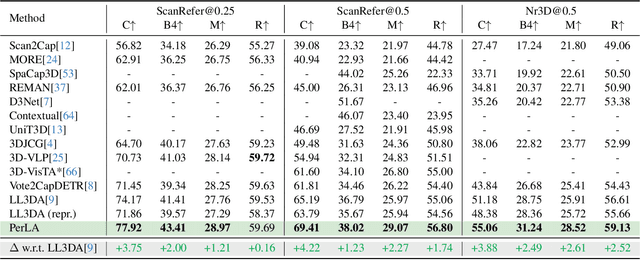

Enabling Large Language Models (LLMs) to understand the 3D physical world is an emerging yet challenging research direction. Current strategies for processing point clouds typically downsample the scene or divide it into smaller parts for separate analysis. However, both approaches risk losing key local details or global contextual information. In this paper, we introduce PerLA, a 3D language assistant designed to be more perceptive to both details and context, making visual representations more informative for the LLM. PerLA captures high-resolution (local) details in parallel from different point cloud areas and integrates them with (global) context obtained from a lower-resolution whole point cloud. We present a novel algorithm that preserves point cloud locality through the Hilbert curve and effectively aggregates local-to-global information via cross-attention and a graph neural network. Lastly, we introduce a novel loss for local representation consensus to promote training stability. PerLA outperforms state-of-the-art 3D language assistants, with gains of up to +1.34 CiDEr on ScanQA for question answering, and +4.22 on ScanRefer and +3.88 on Nr3D for dense captioning.\url{https://gfmei.github.io/PerLA/}
GSTran: Joint Geometric and Semantic Coherence for Point Cloud Segmentation
Aug 21, 2024



Learning meaningful local and global information remains a challenge in point cloud segmentation tasks. When utilizing local information, prior studies indiscriminately aggregates neighbor information from different classes to update query points, potentially compromising the distinctive feature of query points. In parallel, inaccurate modeling of long-distance contextual dependencies when utilizing global information can also impact model performance. To address these issues, we propose GSTran, a novel transformer network tailored for the segmentation task. The proposed network mainly consists of two principal components: a local geometric transformer and a global semantic transformer. In the local geometric transformer module, we explicitly calculate the geometric disparity within the local region. This enables amplifying the affinity with geometrically similar neighbor points while suppressing the association with other neighbors. In the global semantic transformer module, we design a multi-head voting strategy. This strategy evaluates semantic similarity across the entire spatial range, facilitating the precise capture of contextual dependencies. Experiments on ShapeNetPart and S3DIS benchmarks demonstrate the effectiveness of the proposed method, showing its superiority over other algorithms. The code is available at https://github.com/LAB123-tech/GSTran.
Vocabulary-Free 3D Instance Segmentation with Vision and Language Assistant
Aug 20, 2024



Most recent 3D instance segmentation methods are open vocabulary, offering a greater flexibility than closed-vocabulary methods. Yet, they are limited to reasoning within a specific set of concepts, \ie the vocabulary, prompted by the user at test time. In essence, these models cannot reason in an open-ended fashion, i.e., answering ``List the objects in the scene.''. We introduce the first method to address 3D instance segmentation in a setting that is void of any vocabulary prior, namely a vocabulary-free setting. We leverage a large vision-language assistant and an open-vocabulary 2D instance segmenter to discover and ground semantic categories on the posed images. To form 3D instance mask, we first partition the input point cloud into dense superpoints, which are then merged into 3D instance masks. We propose a novel superpoint merging strategy via spectral clustering, accounting for both mask coherence and semantic coherence that are estimated from the 2D object instance masks. We evaluate our method using ScanNet200 and Replica, outperforming existing methods in both vocabulary-free and open-vocabulary settings. Code will be made available.
Bringing Masked Autoencoders Explicit Contrastive Properties for Point Cloud Self-Supervised Learning
Jul 08, 2024



Contrastive learning (CL) for Vision Transformers (ViTs) in image domains has achieved performance comparable to CL for traditional convolutional backbones. However, in 3D point cloud pretraining with ViTs, masked autoencoder (MAE) modeling remains dominant. This raises the question: Can we take the best of both worlds? To answer this question, we first empirically validate that integrating MAE-based point cloud pre-training with the standard contrastive learning paradigm, even with meticulous design, can lead to a decrease in performance. To address this limitation, we reintroduce CL into the MAE-based point cloud pre-training paradigm by leveraging the inherent contrastive properties of MAE. Specifically, rather than relying on extensive data augmentation as commonly used in the image domain, we randomly mask the input tokens twice to generate contrastive input pairs. Subsequently, a weight-sharing encoder and two identically structured decoders are utilized to perform masked token reconstruction. Additionally, we propose that for an input token masked by both masks simultaneously, the reconstructed features should be as similar as possible. This naturally establishes an explicit contrastive constraint within the generative MAE-based pre-training paradigm, resulting in our proposed method, Point-CMAE. Consequently, Point-CMAE effectively enhances the representation quality and transfer performance compared to its MAE counterpart. Experimental evaluations across various downstream applications, including classification, part segmentation, and few-shot learning, demonstrate the efficacy of our framework in surpassing state-of-the-art techniques under standard ViTs and single-modal settings. The source code and trained models are available at: https://github.com/Amazingren/Point-CMAE.
Zero-Shot Point Cloud Registration
Dec 08, 2023



Learning-based point cloud registration approaches have significantly outperformed their traditional counterparts. However, they typically require extensive training on specific datasets. In this paper, we propose , the first zero-shot point cloud registration approach that eliminates the need for training on point cloud datasets. The cornerstone of ZeroReg is the novel transfer of image features from keypoints to the point cloud, enriched by aggregating information from 3D geometric neighborhoods. Specifically, we extract keypoints and features from 2D image pairs using a frozen pretrained 2D backbone. These features are then projected in 3D, and patches are constructed by searching for neighboring points. We integrate the geometric and visual features of each point using our novel parameter-free geometric decoder. Subsequently, the task of determining correspondences between point clouds is formulated as an optimal transport problem. Extensive evaluations of ZeroReg demonstrate its competitive performance against both traditional and learning-based methods. On benchmarks such as 3DMatch, 3DLoMatch, and ScanNet, ZeroReg achieves impressive Recall Ratios (RR) of over 84%, 46%, and 75%, respectively.