 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLASS: Graph and Vision-Language Assisted Semantic Shape Correspondence
Mar 08, 2026Establishing dense correspondence across 3D shapes is crucial for fundamental downstream tasks, including texture transfer, shape interpolation, and robotic manipulation. However, learning these mappings without manual supervision remains a formidable challenge, particularly under severe non-isometric deformations and in inter-class settings where geometric cues are ambiguous. Conventional functional map methods, while elegant, typically struggle in these regimes due to their reliance on isometry. To address this, we present GLASS, a framework that bridges the gap by integrating geometric spectral analysis with rich semantic priors from vision-language foundation models. GLASS introduces three key innovations: (i) a view-consistent strategy that enables robust multi-view visual feature extraction from powerful vision foundation models; (ii) the injection of language embeddings into vertex descriptors via zero-shot 3D segmentation, capturing high-level part semantics; and (iii) a graph-assisted contrastive loss that enforces structural consistency between regions (e.g., source's head'' $\leftrightarrow$ target's head'') by leveraging geodesic and topological relationships between regions. This design allows GLASS to learn globally coherent and semantically consistent maps without ground-truth supervision. Extensive experiments demonstrate that GLASS achieves state-of-the-art performance across all regimes, maintaining high accuracy on standard near-isometric tasks while significantly advancing performance in challenging settings. Specifically, it achieves average geodesic errors of 0.21, 4.5, and 5.6 on the inter-class benchmark SNIS and non-isometric benchmarks SMAL and TOPKIDS, reducing errors from URSSM baselines of 0.49, 6.0, and 8.9 by 57%, 25%, and 37%, respectively.
Efficient Encoder-Free Fourier-based 3D Large Multimodal Model
Feb 26, 2026Large Multimodal Models (LMMs) that process 3D data typically rely on heavy, pre-trained visual encoders to extract geometric features. While recent 2D LMMs have begun to eliminate such encoders for efficiency and scalability, extending this paradigm to 3D remains challenging due to the unordered and large-scale nature of point clouds. This leaves a critical unanswered question: How can we design an LMM that tokenizes unordered 3D data effectively and efficiently without a cumbersome encoder? We propose Fase3D, the first efficient encoder-free Fourier-based 3D scene LMM. Fase3D tackles the challenges of scalability and permutation invariance with a novel tokenizer that combines point cloud serialization and the Fast Fourier Transform (FFT) to approximate self-attention. This design enables an effective and computationally minimal architecture, built upon three key innovations: First, we represent large scenes compactly via structured superpoints. Second, our space-filling curve serialization followed by an FFT enables efficient global context modeling and graph-based token merging. Lastly, our Fourier-augmented LoRA adapters inject global frequency-aware interactions into the LLMs at a negligible cost. Fase3D achieves performance comparable to encoder-based 3D LMMs while being significantly more efficient in computation and parameters. Project website: https://tev-fbk.github.io/Fase3D.
Generative 6D Pose Estimation via Conditional Flow Matching
Feb 23, 2026Existing methods for instance-level 6D pose estimation typically rely on neural networks that either directly regress the pose in $\mathrm{SE}(3)$ or estimate it indirectly via local feature matching. The former struggle with object symmetries, while the latter fail in the absence of distinctive local features. To overcome these limitations, we propose a novel formulation of 6D pose estimation as a conditional flow matching problem in $\mathbb{R}^3$. We introduce Flose, a generative method that infers object poses via a denoising process conditioned on local features. While prior approaches based on conditional flow matching perform denoising solely based on geometric guidance, Flose integrates appearance-based semantic features to mitigate ambiguities caused by object symmetries. We further incorporate RANSAC-based registration to handle outliers. We validate Flose on five datasets from the established BOP benchmark. Flose outperforms prior methods with an average improvement of +4.5 Average Recall. Project Website : https://tev-fbk.github.io/Flose/
OpenHype: Hyperbolic Embeddings for Hierarchical Open-Vocabulary Radiance Fields
Oct 24, 2025Modeling the inherent hierarchical structure of 3D objects and 3D scenes is highly desirable, as it enables a more holistic understanding of environments for autonomous agents. Accomplishing this with implicit representations, such as Neural Radiance Fields, remains an unexplored challenge. Existing methods that explicitly model hierarchical structures often face significant limitations: they either require multiple rendering passes to capture embeddings at different levels of granularity, significantly increasing inference time, or rely on predefined, closed-set discrete hierarchies that generalize poorly to the diverse and nuanced structures encountered by agents in the real world. To address these challenges, we propose OpenHype, a novel approach that represents scene hierarchies using a continuous hyperbolic latent space. By leveraging the properties of hyperbolic geometry, OpenHype naturally encodes multi-scale relationships and enables smooth traversal of hierarchies through geodesic paths in latent space. Our method outperforms state-of-the-art approaches on standard benchmarks, demonstrating superior efficiency and adaptability in 3D scene understanding.
GRASPLAT: Enabling dexterous grasping through novel view synthesis
Oct 22, 2025Achieving dexterous robotic grasping with multi-fingered hands remains a significant challenge. While existing methods rely on complete 3D scans to predict grasp poses, these approaches face limitations due to the difficulty of acquiring high-quality 3D data in real-world scenarios. In this paper, we introduce GRASPLAT, a novel grasping framework that leverages consistent 3D information while being trained solely on RGB images. Our key insight is that by synthesizing physically plausible images of a hand grasping an object, we can regress the corresponding hand joints for a successful grasp. To achieve this, we utilize 3D Gaussian Splatting to generate high-fidelity novel views of real hand-object interactions, enabling end-to-end training with RGB data. Unlike prior methods, our approach incorporates a photometric loss that refines grasp predictions by minimizing discrepancies between rendered and real images. We conduct extensive experiments on both synthetic and real-world grasping datasets, demonstrating that GRASPLAT improves grasp success rates up to 36.9% over existing image-based methods. Project page: https://mbortolon97.github.io/grasplat/
Masked Clustering Prediction for Unsupervised Point Cloud Pre-training
Aug 12, 2025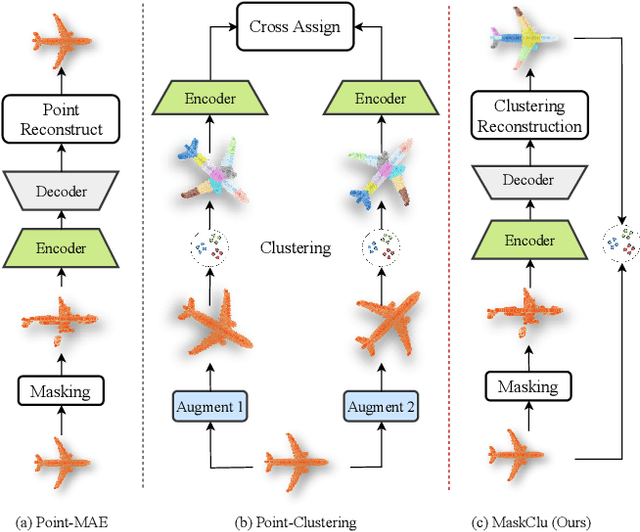
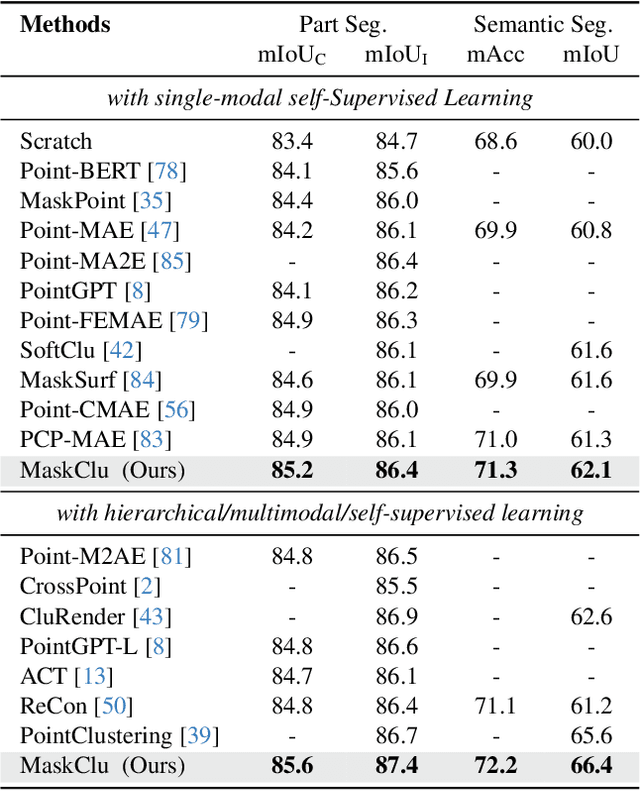
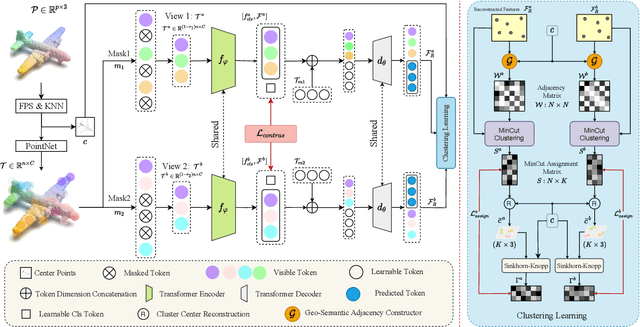
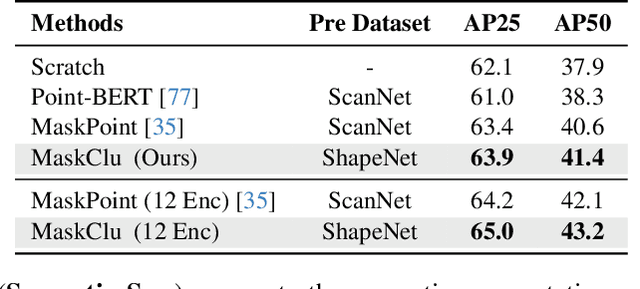
Vision transformers (ViTs) have recently been widely applied to 3D point cloud understanding, with masked autoencoding as the predominant pre-training paradigm. However, the challenge of learning dense and informative semantic features from point clouds via standard ViTs remains underexplored. We propose MaskClu, a novel unsupervised pre-training method for ViTs on 3D point clouds that integrates masked point modeling with clustering-based learning. MaskClu is designed to reconstruct both cluster assignments and cluster centers from masked point clouds, thus encouraging the model to capture dense semantic information. Additionally, we introduce a global contrastive learning mechanism that enhances instance-level feature learning by contrasting different masked views of the same point cloud. By jointly optimizing these complementary objectives, i.e., dense semantic reconstruction, and instance-level contrastive learning. MaskClu enables ViTs to learn richer and more semantically meaningful representations from 3D point clouds. We validate the effectiveness of our method via multiple 3D tasks, including part segmentation, semantic segmentation, object detection, and classification, where MaskClu sets new competitive results. The code and models will be released at:https://github.com/Amazingren/maskclu.
AI-driven visual monitoring of industrial assembly tasks
Jun 18, 2025Visual monitoring of industrial assembly tasks is critical for preventing equipment damage due to procedural errors and ensuring worker safety. Although commercial solutions exist, they typically require rigid workspace setups or the application of visual markers to simplify the problem. We introduce ViMAT, a novel AI-driven system for real-time visual monitoring of assembly tasks that operates without these constraints. ViMAT combines a perception module that extracts visual observations from multi-view video streams with a reasoning module that infers the most likely action being performed based on the observed assembly state and prior task knowledge. We validate ViMAT on two assembly tasks, involving the replacement of LEGO components and the reconfiguration of hydraulic press molds, demonstrating its effectiveness through quantitative and qualitative analysis in challenging real-world scenarios characterized by partial and uncertain visual observations. Project page: https://tev-fbk.github.io/ViMAT
CHIP: A multi-sensor dataset for 6D pose estimation of chairs in industrial settings
Jun 11, 2025Accurate 6D pose estimation of complex objects in 3D environments is essential for effective robotic manipulation. Yet, existing benchmarks fall short in evaluating 6D pose estimation methods under realistic industrial conditions, as most datasets focus on household objects in domestic settings, while the few available industrial datasets are limited to artificial setups with objects placed on tables. To bridge this gap, we introduce CHIP, the first dataset designed for 6D pose estimation of chairs manipulated by a robotic arm in a real-world industrial environment. CHIP includes seven distinct chairs captured using three different RGBD sensing technologies and presents unique challenges, such as distractor objects with fine-grained differences and severe occlusions caused by the robotic arm and human operators. CHIP comprises 77,811 RGBD images annotated with ground-truth 6D poses automatically derived from the robot's kinematics, averaging 11,115 annotations per chair. We benchmark CHIP using three zero-shot 6D pose estimation methods, assessing performance across different sensor types, localization priors, and occlusion levels. Results show substantial room for improvement, highlighting the unique challenges posed by the dataset. CHIP will be publicly released.
Accurate and efficient zero-shot 6D pose estimation with frozen foundation models
Jun 11, 2025Estimating the 6D pose of objects from RGBD data is a fundamental problem in computer vision, with applications in robotics and augmented reality. A key challenge is achieving generalization to novel objects that were not seen during training. Most existing approaches address this by scaling up training on synthetic data tailored to the task, a process that demands substantial computational resources. But is task-specific training really necessary for accurate and efficient 6D pose estimation of novel objects? To answer No!, we introduce FreeZeV2, the second generation of FreeZe: a training-free method that achieves strong generalization to unseen objects by leveraging geometric and vision foundation models pre-trained on unrelated data. FreeZeV2 improves both accuracy and efficiency over FreeZe through three key contributions: (i) a sparse feature extraction strategy that reduces inference-time computation without sacrificing accuracy; (ii) a feature-aware scoring mechanism that improves both pose selection during RANSAC-based 3D registration and the final ranking of pose candidates; and (iii) a modular design that supports ensembles of instance segmentation models, increasing robustness to segmentation masks errors. We evaluate FreeZeV2 on the seven core datasets of the BOP Benchmark, where it establishes a new state-of-the-art in 6D pose estimation of unseen objects. When using the same segmentation masks, FreeZeV2 achieves a remarkable 8x speedup over FreeZe while also improving accuracy by 5%. When using ensembles of segmentation models, FreeZeV2 gains an additional 8% in accuracy while still running 2.5x faster than FreeZe. FreeZeV2 was awarded Best Overall Method at the BOP Challenge 2024.
Self-Supervised and Generalizable Tokenization for CLIP-Based 3D Understanding
May 24, 2025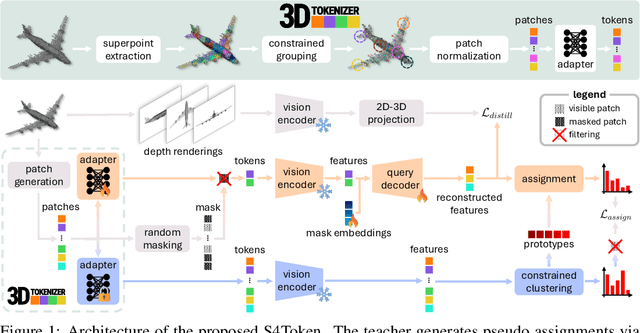


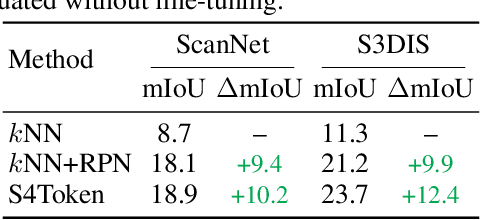
Vision-language models like CLIP can offer a promising foundation for 3D scene understanding when extended with 3D tokenizers. However, standard approaches, such as k-nearest neighbor or radius-based tokenization, struggle with cross-domain generalization due to sensitivity to dataset-specific spatial scales. We present a universal 3D tokenizer designed for scale-invariant representation learning with a frozen CLIP backbone. We show that combining superpoint-based grouping with coordinate scale normalization consistently outperforms conventional methods through extensive experimental analysis. Specifically, we introduce S4Token, a tokenization pipeline that produces semantically-informed tokens regardless of scene scale. Our tokenizer is trained without annotations using masked point modeling and clustering-based objectives, along with cross-modal distillation to align 3D tokens with 2D multi-view image features. For dense prediction tasks, we propose a superpoint-level feature propagation module to recover point-level detail from sparse tokens.