 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Modal and Uncertainty-Aware Agglomeration for Open-Vocabulary 3D Scene Understanding
Paper and Code
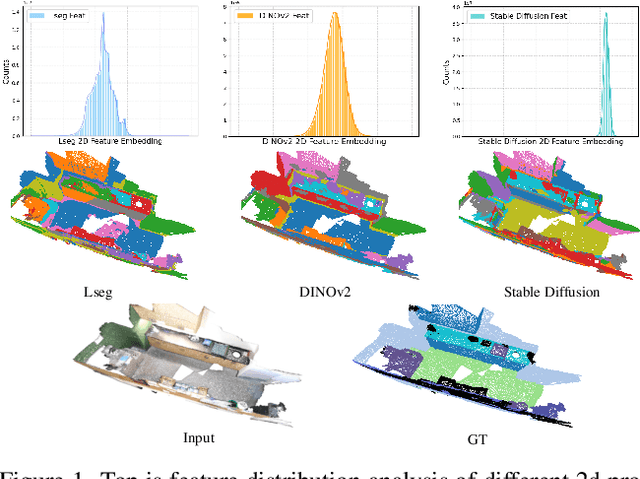

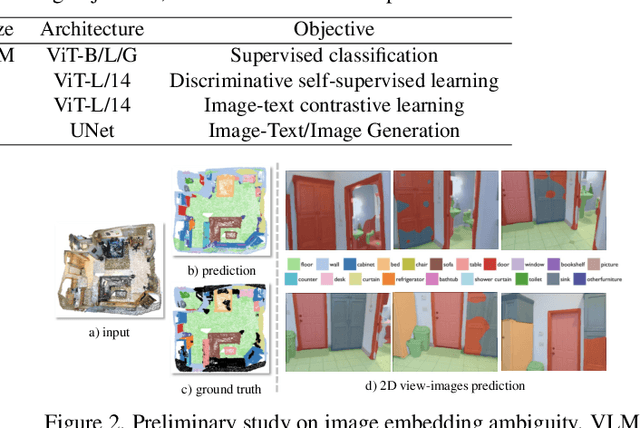

The lack of a large-scale 3D-text corpus has led recent works to distill open-vocabulary knowledge from vision-language models (VLMs). owever, these methods typically rely on a single VLM to align the feature spaces of 3D models within a common language space, which limits the potential of 3D models to leverage the diverse spatial and semantic capabilities encapsulated in various foundation models. In this paper, we propose Cross-modal and Uncertainty-aware Agglomeration for Open-vocabulary 3D Scene Understanding dubbed CUA-O3D, the first model to integrate multiple foundation models-such as CLIP, DINOv2, and Stable Diffusion-into 3D scene understanding. We further introduce a deterministic uncertainty estimation to adaptively distill and harmonize the heterogeneous 2D feature embeddings from these models. Our method addresses two key challenges: (1) incorporating semantic priors from VLMs alongside the geometric knowledge of spatially-aware vision foundation models, and (2) using a novel deterministic uncertainty estimation to capture model-specific uncertainties across diverse semantic and geometric sensitivities, helping to reconcile heterogeneous representations during training. Extensive experiments on ScanNetV2 and Matterport3D demonstrate that our method not only advances open-vocabulary segmentation but also achieves robust cross-domain alignment and competitive spatial perception capabilities. The code will be available at \href{https://github.com/TyroneLi/CUA_O3D}{CUA_O3D}.