 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Multi-Camera Tokenization with Triplanes for End-to-End Driving
Jun 13, 2025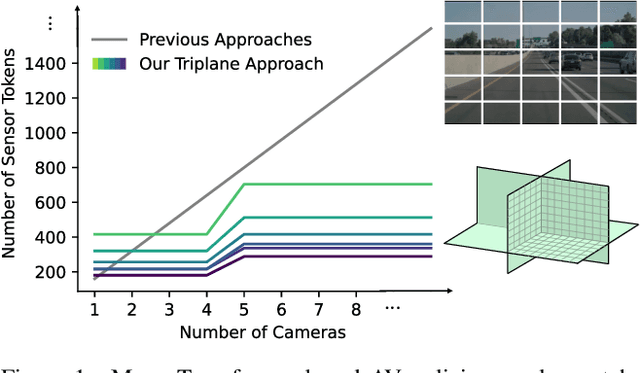
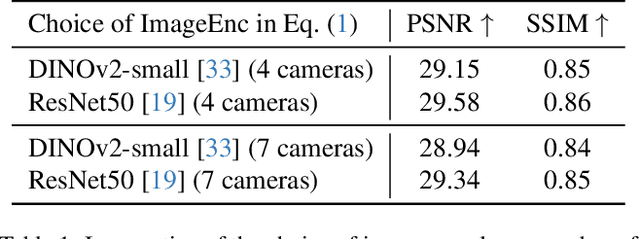
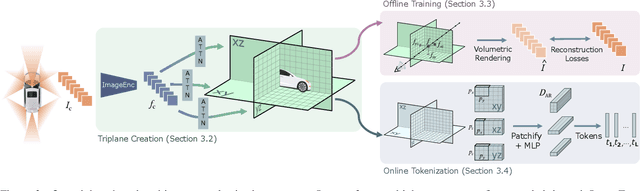
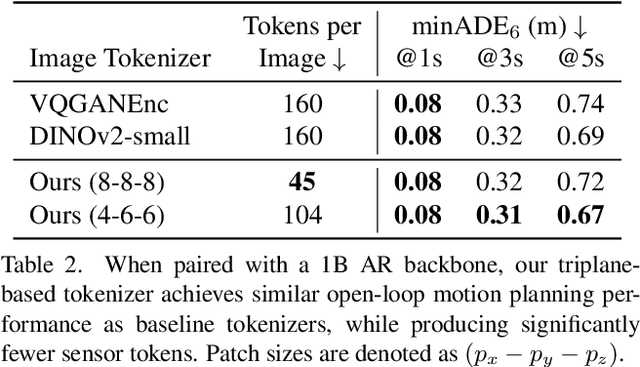
Autoregressive Transformers are increasingly being deployed as end-to-end robot and autonomous vehicle (AV) policy architectures, owing to their scalability and potential to leverage internet-scale pretraining for generalization. Accordingly, tokenizing sensor data efficiently is paramount to ensuring the real-time feasibility of such architectures on embedded hardware. To this end, we present an efficient triplane-based multi-camera tokenization strategy that leverages recent advances in 3D neural reconstruction and rendering to produce sensor tokens that are agnostic to the number of input cameras and their resolution, while explicitly accounting for their geometry around an AV. Experiments on a large-scale AV dataset and state-of-the-art neural simulator demonstrate that our approach yields significant savings over current image patch-based tokenization strategies, producing up to 72% fewer tokens, resulting in up to 50% faster policy inference while achieving the same open-loop motion planning accuracy and improved offroad rates in closed-loop driving simulations.
Towards Learning to Complete Anything in Lidar
Apr 16, 2025We propose CAL (Complete Anything in Lidar) for Lidar-based shape-completion in-the-wild. This is closely related to Lidar-based semantic/panoptic scene completion. However, contemporary methods can only complete and recognize objects from a closed vocabulary labeled in existing Lidar datasets. Different to that, our zero-shot approach leverages the temporal context from multi-modal sensor sequences to mine object shapes and semantic features of observed objects. These are then distilled into a Lidar-only instance-level completion and recognition model. Although we only mine partial shape completions, we find that our distilled model learns to infer full object shapes from multiple such partial observations across the dataset. We show that our model can be prompted on standard benchmarks for Semantic and Panoptic Scene Completion, localize objects as (amodal) 3D bounding boxes, and recognize objects beyond fixed class vocabularies. Our project page is https://research.nvidia.com/labs/dvl/projects/complete-anything-lidar
Cross-Modal and Uncertainty-Aware Agglomeration for Open-Vocabulary 3D Scene Understanding
Mar 20, 2025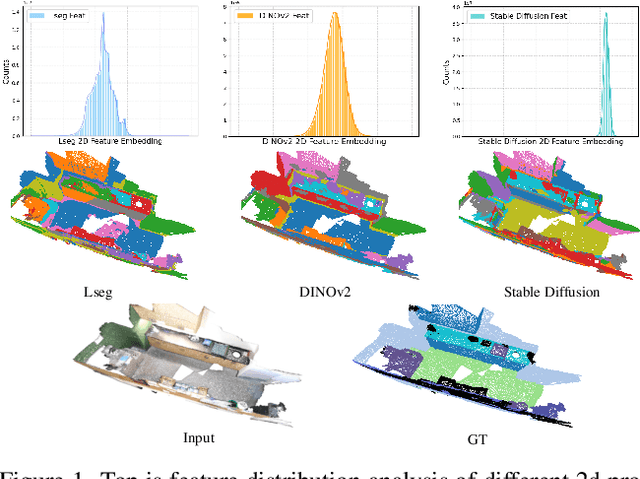

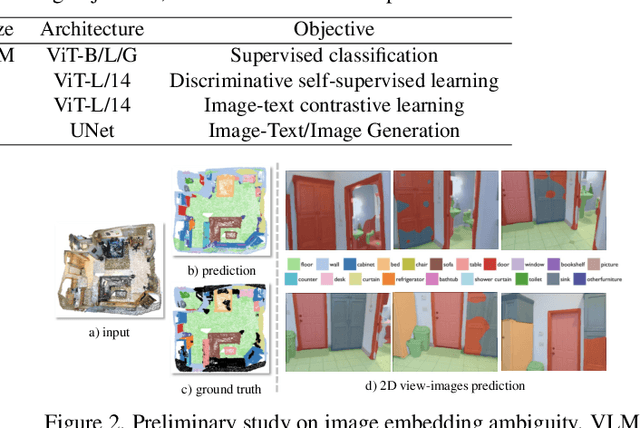

The lack of a large-scale 3D-text corpus has led recent works to distill open-vocabulary knowledge from vision-language models (VLMs). owever, these methods typically rely on a single VLM to align the feature spaces of 3D models within a common language space, which limits the potential of 3D models to leverage the diverse spatial and semantic capabilities encapsulated in various foundation models. In this paper, we propose Cross-modal and Uncertainty-aware Agglomeration for Open-vocabulary 3D Scene Understanding dubbed CUA-O3D, the first model to integrate multiple foundation models-such as CLIP, DINOv2, and Stable Diffusion-into 3D scene understanding. We further introduce a deterministic uncertainty estimation to adaptively distill and harmonize the heterogeneous 2D feature embeddings from these models. Our method addresses two key challenges: (1) incorporating semantic priors from VLMs alongside the geometric knowledge of spatially-aware vision foundation models, and (2) using a novel deterministic uncertainty estimation to capture model-specific uncertainties across diverse semantic and geometric sensitivities, helping to reconcile heterogeneous representations during training. Extensive experiments on ScanNetV2 and Matterport3D demonstrate that our method not only advances open-vocabulary segmentation but also achieves robust cross-domain alignment and competitive spatial perception capabilities. The code will be available at \href{https://github.com/TyroneLi/CUA_O3D}{CUA_O3D}.
Novel class discovery meets foundation models for 3D semantic segmentation
Dec 06, 2023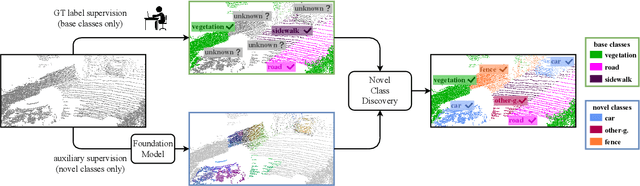

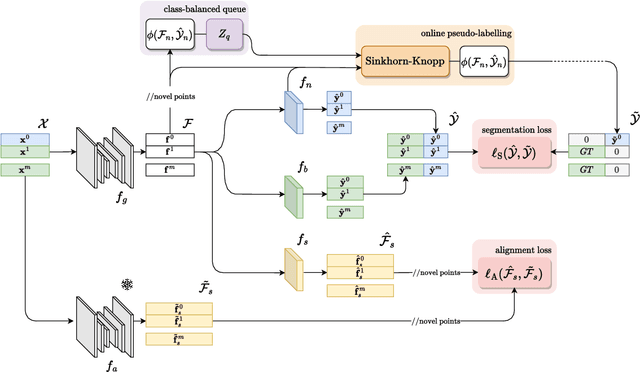

The task of Novel Class Discovery (NCD) in semantic segmentation entails training a model able to accurately segment unlabelled (novel) classes, relying on the available supervision from annotated (base) classes. Although extensively investigated in 2D image data, the extension of the NCD task to the domain of 3D point clouds represents a pioneering effort, characterized by assumptions and challenges that are not present in the 2D case. This paper represents an advancement in the analysis of point cloud data in four directions. Firstly, it introduces the novel task of NCD for point cloud semantic segmentation. Secondly, it demonstrates that directly transposing the only existing NCD method for 2D image semantic segmentation to 3D data yields suboptimal results. Thirdly, a new NCD approach based on online clustering, uncertainty estimation, and semantic distillation is presented. Lastly, a novel evaluation protocol is proposed to rigorously assess the performance of NCD in point cloud semantic segmentation. Through comprehensive evaluations on the SemanticKITTI, SemanticPOSS, and S3DIS datasets, the paper demonstrates substantial superiority of the proposed method over the considered baselines.
Compositional Semantic Mix for Domain Adaptation in Point Cloud Segmentation
Aug 29, 2023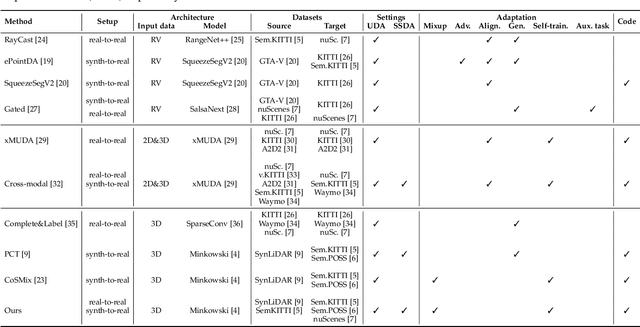

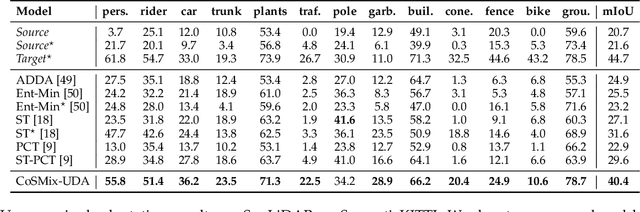
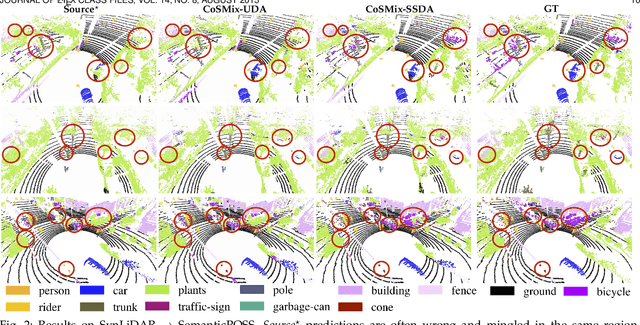
Deep-learning models for 3D point cloud semantic segmentation exhibit limited generalization capabilities when trained and tested on data captured with different sensors or in varying environments due to domain shift. Domain adaptation methods can be employed to mitigate this domain shift, for instance, by simulating sensor noise, developing domain-agnostic generators, or training point cloud completion networks. Often, these methods are tailored for range view maps or necessitate multi-modal input. In contrast, domain adaptation in the image domain can be executed through sample mixing, which emphasizes input data manipulation rather than employing distinct adaptation modules. In this study, we introduce compositional semantic mixing for point cloud domain adaptation, representing the first unsupervised domain adaptation technique for point cloud segmentation based on semantic and geometric sample mixing. We present a two-branch symmetric network architecture capable of concurrently processing point clouds from a source domain (e.g. synthetic) and point clouds from a target domain (e.g. real-world). Each branch operates within one domain by integrating selected data fragments from the other domain and utilizing semantic information derived from source labels and target (pseudo) labels. Additionally, our method can leverage a limited number of human point-level annotations (semi-supervised) to further enhance performance. We assess our approach in both synthetic-to-real and real-to-real scenarios using LiDAR datasets and demonstrate that it significantly outperforms state-of-the-art methods in both unsupervised and semi-supervised settings.
Walking Your LiDOG: A Journey Through Multiple Domains for LiDAR Semantic Segmentation
Apr 23, 2023



The ability to deploy robots that can operate safely in diverse environments is crucial for developing embodied intelligent agents. As a community, we have made tremendous progress in within-domain LiDAR semantic segmentation. However, do these methods generalize across domains? To answer this question, we design the first experimental setup for studying domain generalization (DG) for LiDAR semantic segmentation (DG-LSS). Our results confirm a significant gap between methods, evaluated in a cross-domain setting: for example, a model trained on the source dataset (SemanticKITTI) obtains $26.53$ mIoU on the target data, compared to $48.49$ mIoU obtained by the model trained on the target domain (nuScenes). To tackle this gap, we propose the first method specifically designed for DG-LSS, which obtains $34.88$ mIoU on the target domain, outperforming all baselines. Our method augments a sparse-convolutional encoder-decoder 3D segmentation network with an additional, dense 2D convolutional decoder that learns to classify a birds-eye view of the point cloud. This simple auxiliary task encourages the 3D network to learn features that are robust to sensor placement shifts and resolution, and are transferable across domains. With this work, we aim to inspire the community to develop and evaluate future models in such cross-domain conditions.
Novel Class Discovery for 3D Point Cloud Semantic Segmentation
Mar 21, 2023



Novel class discovery (NCD) for semantic segmentation is the task of learning a model that can segment unlabelled (novel) classes using only the supervision from labelled (base) classes. This problem has recently been pioneered for 2D image data, but no work exists for 3D point cloud data. In fact, the assumptions made for 2D are loosely applicable to 3D in this case. This paper is presented to advance the state of the art on point cloud data analysis in four directions. Firstly, we address the new problem of NCD for point cloud semantic segmentation. Secondly, we show that the transposition of the only existing NCD method for 2D semantic segmentation to 3D data is suboptimal. Thirdly, we present a new method for NCD based on online clustering that exploits uncertainty quantification to produce prototypes for pseudo-labelling the points of the novel classes. Lastly, we introduce a new evaluation protocol to assess the performance of NCD for point cloud semantic segmentation. We thoroughly evaluate our method on SemanticKITTI and SemanticPOSS datasets, showing that it can significantly outperform the baseline. Project page at this link: https://github.com/LuigiRiz/NOPS.
Overlap-guided Gaussian Mixture Models for Point Cloud Registration
Oct 17, 2022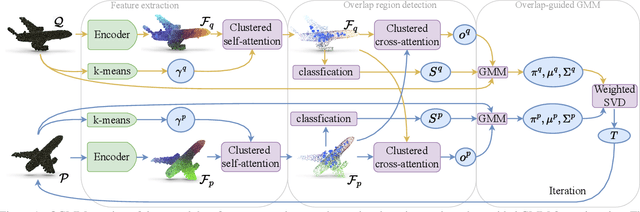
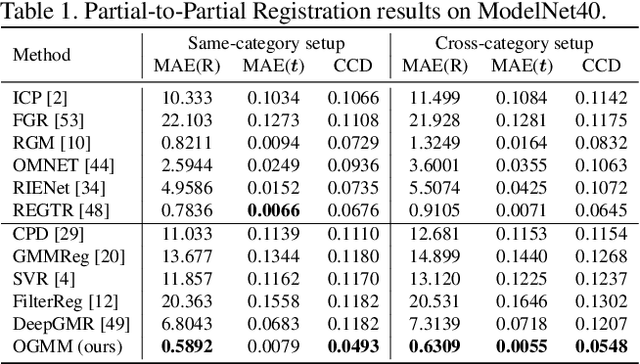
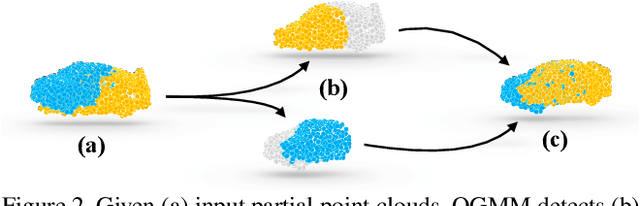
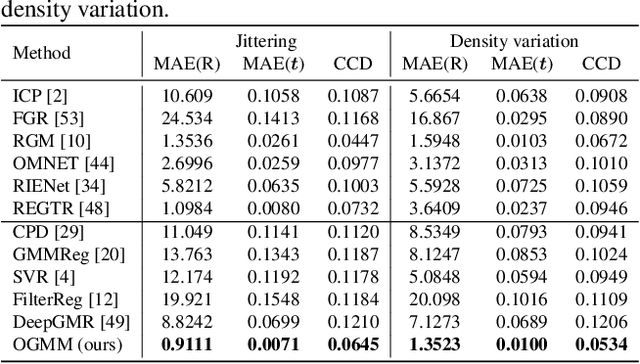
Probabilistic 3D point cloud registration methods have shown competitive performance in overcoming noise, outliers, and density variations. However, registering point cloud pairs in the case of partial overlap is still a challenge. This paper proposes a novel overlap-guided probabilistic registration approach that computes the optimal transformation from matched Gaussian Mixture Model (GMM) parameters. We reformulate the registration problem as the problem of aligning two Gaussian mixtures such that a statistical discrepancy measure between the two corresponding mixtures is minimized. We introduce a Transformer-based detection module to detect overlapping regions, and represent the input point clouds using GMMs by guiding their alignment through overlap scores computed by this detection module. Experiments show that our method achieves superior registration accuracy and efficiency than state-of-the-art methods when handling point clouds with partial overlap and different densities on synthetic and real-world datasets. https://github.com/gfmei/ogmm
Data Augmentation-free Unsupervised Learning for 3D Point Cloud Understanding
Oct 06, 2022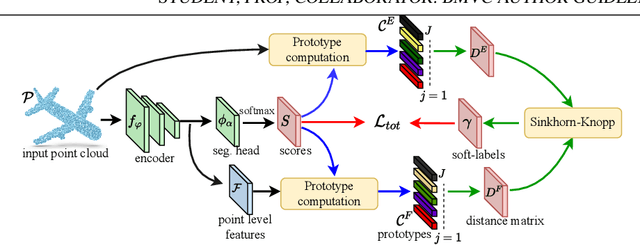

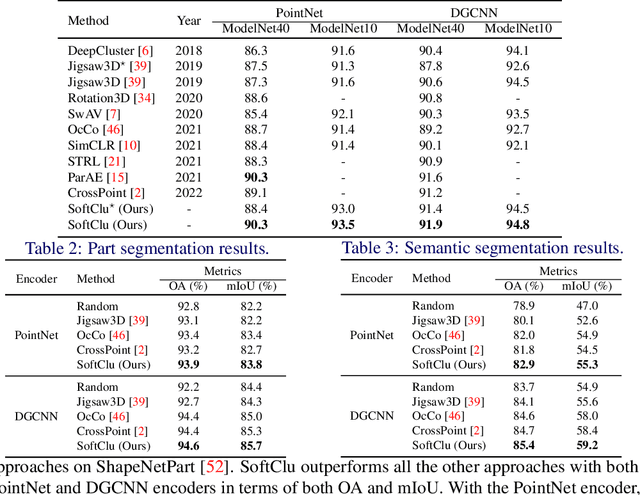
Unsupervised learning on 3D point clouds has undergone a rapid evolution, especially thanks to data augmentation-based contrastive methods. However, data augmentation is not ideal as it requires a careful selection of the type of augmentations to perform, which in turn can affect the geometric and semantic information learned by the network during self-training. To overcome this issue, we propose an augmentation-free unsupervised approach for point clouds to learn transferable point-level features via soft clustering, named SoftClu. SoftClu assumes that the points belonging to a cluster should be close to each other in both geometric and feature spaces. This differs from typical contrastive learning, which builds similar representations for a whole point cloud and its augmented versions. We exploit the affiliation of points to their clusters as a proxy to enable self-training through a pseudo-label prediction task. Under the constraint that these pseudo-labels induce the equipartition of the point cloud, we cast SoftClu as an optimal transport problem. We formulate an unsupervised loss to minimize the standard cross-entropy between pseudo-labels and predicted labels. Experiments on downstream applications, such as 3D object classification, part segmentation, and semantic segmentation, show the effectiveness of our framework in outperforming state-of-the-art techniques.
CoSMix: Compositional Semantic Mix for Domain Adaptation in 3D LiDAR Segmentation
Jul 20, 20223D LiDAR semantic segmentation is fundamental for autonomous driving. Several Unsupervised Domain Adaptation (UDA) methods for point cloud data have been recently proposed to improve model generalization for different sensors and environments. Researchers working on UDA problems in the image domain have shown that sample mixing can mitigate domain shift. We propose a new approach of sample mixing for point cloud UDA, namely Compositional Semantic Mix (CoSMix), the first UDA approach for point cloud segmentation based on sample mixing. CoSMix consists of a two-branch symmetric network that can process labelled synthetic data (source) and real-world unlabelled point clouds (target) concurrently. Each branch operates on one domain by mixing selected pieces of data from the other one, and by using the semantic information derived from source labels and target pseudo-labels. We evaluate CoSMix on two large-scale datasets, showing that it outperforms state-of-the-art methods by a large margin. Our code is available at https://github.com/saltoricristiano/cosmix-uda.