 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabel Anything: Multi-Class Few-Shot Semantic Segmentation with Visual Prompts
Jul 02, 2024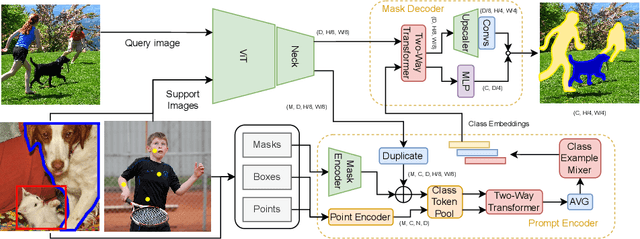
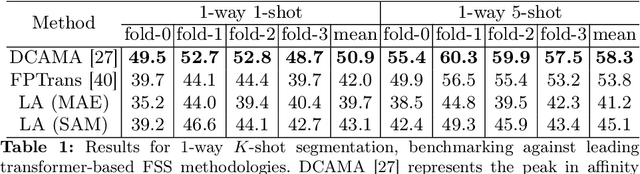
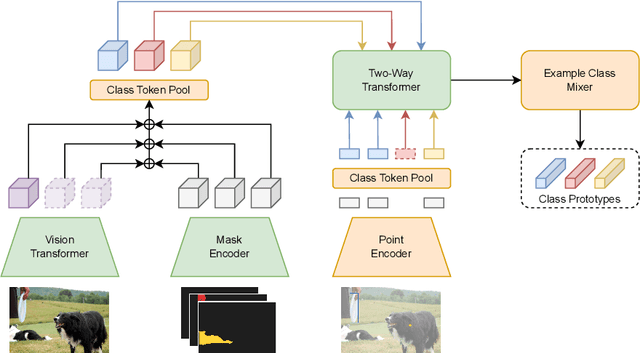

We present Label Anything, an innovative neural network architecture designed for few-shot semantic segmentation (FSS) that demonstrates remarkable generalizability across multiple classes with minimal examples required per class. Diverging from traditional FSS methods that predominantly rely on masks for annotating support images, Label Anything introduces varied visual prompts -- points, bounding boxes, and masks -- thereby enhancing the framework's versatility and adaptability. Unique to our approach, Label Anything is engineered for end-to-end training across multi-class FSS scenarios, efficiently learning from diverse support set configurations without retraining. This approach enables a "universal" application to various FSS challenges, ranging from $1$-way $1$-shot to complex $N$-way $K$-shot configurations while remaining agnostic to the specific number of class examples. This innovative training strategy reduces computational requirements and substantially improves the model's adaptability and generalization across diverse segmentation tasks. Our comprehensive experimental validation, particularly achieving state-of-the-art results on the COCO-$20^i$ benchmark, underscores Label Anything's robust generalization and flexibility. The source code is publicly available at: https://github.com/pasqualedem/LabelAnything.
Deepfake Detection without Deepfakes: Generalization via Synthetic Frequency Patterns Injection
Mar 20, 2024Deepfake detectors are typically trained on large sets of pristine and generated images, resulting in limited generalization capacity; they excel at identifying deepfakes created through methods encountered during training but struggle with those generated by unknown techniques. This paper introduces a learning approach aimed at significantly enhancing the generalization capabilities of deepfake detectors. Our method takes inspiration from the unique "fingerprints" that image generation processes consistently introduce into the frequency domain. These fingerprints manifest as structured and distinctly recognizable frequency patterns. We propose to train detectors using only pristine images injecting in part of them crafted frequency patterns, simulating the effects of various deepfake generation techniques without being specific to any. These synthetic patterns are based on generic shapes, grids, or auras. We evaluated our approach using diverse architectures across 25 different generation methods. The models trained with our approach were able to perform state-of-the-art deepfake detection, demonstrating also superior generalization capabilities in comparison with previous methods. Indeed, they are untied to any specific generation technique and can effectively identify deepfakes regardless of how they were made.
LLaMAntino: LLaMA 2 Models for Effective Text Generation in Italian Language
Dec 15, 2023


Large Language Models represent state-of-the-art linguistic models designed to equip computers with the ability to comprehend natural language. With its exceptional capacity to capture complex contextual relationships, the LLaMA (Large Language Model Meta AI) family represents a novel advancement in the field of natural language processing by releasing foundational models designed to improve the natural language understanding abilities of the transformer architecture thanks to their large amount of trainable parameters (7, 13, and 70 billion parameters). In many natural language understanding tasks, these models obtain the same performances as private company models such as OpenAI Chat-GPT with the advantage to make publicly available weights and code for research and commercial uses. In this work, we investigate the possibility of Language Adaptation for LLaMA models, explicitly focusing on addressing the challenge of Italian Language coverage. Adopting an open science approach, we explore various tuning approaches to ensure a high-quality text generated in Italian suitable for common tasks in this underrepresented language in the original models' datasets. We aim to release effective text generation models with strong linguistic properties for many tasks that seem challenging using multilingual or general-purpose LLMs. By leveraging an open science philosophy, this study contributes to Language Adaptation strategies for the Italian language by introducing the novel LLaMAntino family of Italian LLMs.
Compositional Semantic Mix for Domain Adaptation in Point Cloud Segmentation
Aug 29, 2023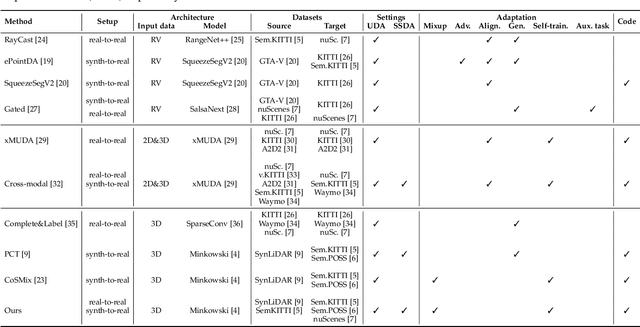

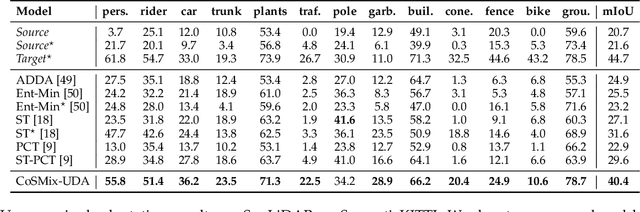
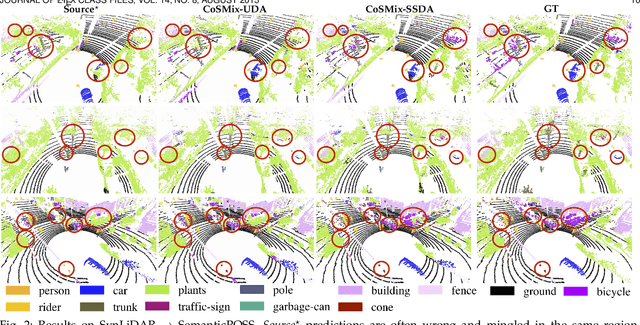
Deep-learning models for 3D point cloud semantic segmentation exhibit limited generalization capabilities when trained and tested on data captured with different sensors or in varying environments due to domain shift. Domain adaptation methods can be employed to mitigate this domain shift, for instance, by simulating sensor noise, developing domain-agnostic generators, or training point cloud completion networks. Often, these methods are tailored for range view maps or necessitate multi-modal input. In contrast, domain adaptation in the image domain can be executed through sample mixing, which emphasizes input data manipulation rather than employing distinct adaptation modules. In this study, we introduce compositional semantic mixing for point cloud domain adaptation, representing the first unsupervised domain adaptation technique for point cloud segmentation based on semantic and geometric sample mixing. We present a two-branch symmetric network architecture capable of concurrently processing point clouds from a source domain (e.g. synthetic) and point clouds from a target domain (e.g. real-world). Each branch operates within one domain by integrating selected data fragments from the other domain and utilizing semantic information derived from source labels and target (pseudo) labels. Additionally, our method can leverage a limited number of human point-level annotations (semi-supervised) to further enhance performance. We assess our approach in both synthetic-to-real and real-to-real scenarios using LiDAR datasets and demonstrate that it significantly outperforms state-of-the-art methods in both unsupervised and semi-supervised settings.
RADiff: Controllable Diffusion Models for Radio Astronomical Maps Generation
Jul 05, 2023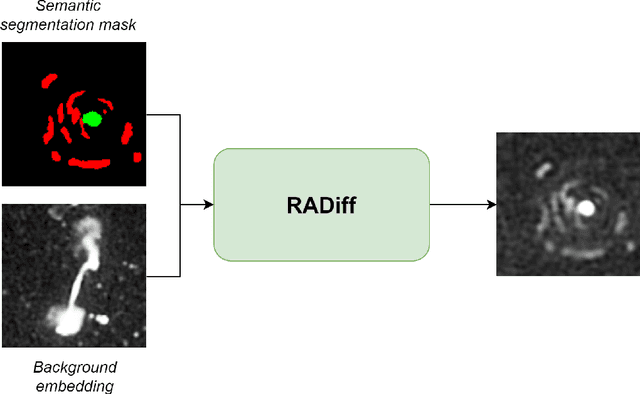
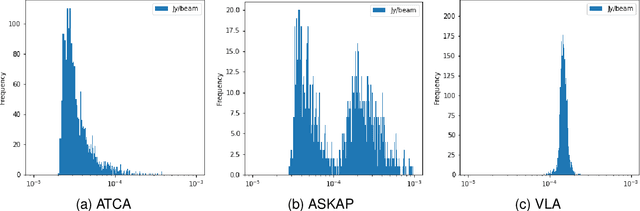
Along with the nearing completion of the Square Kilometre Array (SKA), comes an increasing demand for accurate and reliable automated solutions to extract valuable information from the vast amount of data it will allow acquiring. Automated source finding is a particularly important task in this context, as it enables the detection and classification of astronomical objects. Deep-learning-based object detection and semantic segmentation models have proven to be suitable for this purpose. However, training such deep networks requires a high volume of labeled data, which is not trivial to obtain in the context of radio astronomy. Since data needs to be manually labeled by experts, this process is not scalable to large dataset sizes, limiting the possibilities of leveraging deep networks to address several tasks. In this work, we propose RADiff, a generative approach based on conditional diffusion models trained over an annotated radio dataset to generate synthetic images, containing radio sources of different morphologies, to augment existing datasets and reduce the problems caused by class imbalances. We also show that it is possible to generate fully-synthetic image-annotation pairs to automatically augment any annotated dataset. We evaluate the effectiveness of this approach by training a semantic segmentation model on a real dataset augmented in two ways: 1) using synthetic images obtained from real masks, and 2) generating images from synthetic semantic masks. We show an improvement in performance when applying augmentation, gaining up to 18% in performance when using real masks and 4% when augmenting with synthetic masks. Finally, we employ this model to generate large-scale radio maps with the objective of simulating Data Challenges.
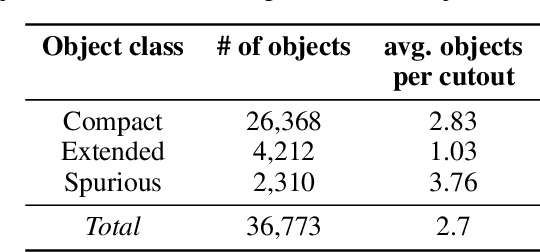
Radio astronomical images object detection and segmentation: A benchmark on deep learning methods
Mar 08, 2023In recent years, deep learning has been successfully applied in various scientific domains. Following these promising results and performances, it has recently also started being evaluated in the domain of radio astronomy. In particular, since radio astronomy is entering the Big Data era, with the advent of the largest telescope in the world - the Square Kilometre Array (SKA), the task of automatic object detection and instance segmentation is crucial for source finding and analysis. In this work, we explore the performance of the most affirmed deep learning approaches, applied to astronomical images obtained by radio interferometric instrumentation, to solve the task of automatic source detection. This is carried out by applying models designed to accomplish two different kinds of tasks: object detection and semantic segmentation. The goal is to provide an overview of existing techniques, in terms of prediction performance and computational efficiency, to scientists in the astrophysics community who would like to employ machine learning in their research.
Inductive Attention for Video Action Anticipation
Dec 17, 2022



Anticipating future actions based on video observations is an important task in video understanding, which would be useful for some precautionary systems that require response time to react before an event occurs. Since the input in action anticipation is only pre-action frames, models do not have enough information about the target action; moreover, similar pre-action frames may lead to different futures. Consequently, any solution using existing action recognition models can only be suboptimal. Recently, researchers have proposed using a longer video context to remedy the insufficient information in pre-action intervals, as well as the self-attention to query past relevant moments to address the anticipation problem. However, the indirect use of video input features as the query might be inefficient, as it only serves as the proxy to the anticipation goal. To this end, we propose an inductive attention model, which transparently uses prior prediction as the query to derive the anticipation result by induction from past experience. Our method naturally considers the uncertainty of multiple futures via the many-to-many association. On the large-scale egocentric video datasets, our model not only shows consistently better performance than state of the art using the same backbone, and is competitive to the methods that employ a stronger backbone, but also superior efficiency in less model parameters.
CoSMix: Compositional Semantic Mix for Domain Adaptation in 3D LiDAR Segmentation
Jul 20, 20223D LiDAR semantic segmentation is fundamental for autonomous driving. Several Unsupervised Domain Adaptation (UDA) methods for point cloud data have been recently proposed to improve model generalization for different sensors and environments. Researchers working on UDA problems in the image domain have shown that sample mixing can mitigate domain shift. We propose a new approach of sample mixing for point cloud UDA, namely Compositional Semantic Mix (CoSMix), the first UDA approach for point cloud segmentation based on sample mixing. CoSMix consists of a two-branch symmetric network that can process labelled synthetic data (source) and real-world unlabelled point clouds (target) concurrently. Each branch operates on one domain by mixing selected pieces of data from the other one, and by using the semantic information derived from source labels and target pseudo-labels. We evaluate CoSMix on two large-scale datasets, showing that it outperforms state-of-the-art methods by a large margin. Our code is available at https://github.com/saltoricristiano/cosmix-uda.
GIPSO: Geometrically Informed Propagation for Online Adaptation in 3D LiDAR Segmentation
Jul 20, 2022


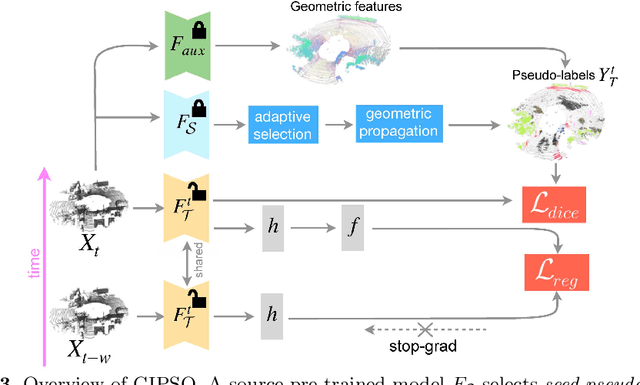
3D point cloud semantic segmentation is fundamental for autonomous driving. Most approaches in the literature neglect an important aspect, i.e., how to deal with domain shift when handling dynamic scenes. This can significantly hinder the navigation capabilities of self-driving vehicles. This paper advances the state of the art in this research field. Our first contribution consists in analysing a new unexplored scenario in point cloud segmentation, namely Source-Free Online Unsupervised Domain Adaptation (SF-OUDA). We experimentally show that state-of-the-art methods have a rather limited ability to adapt pre-trained deep network models to unseen domains in an online manner. Our second contribution is an approach that relies on adaptive self-training and geometric-feature propagation to adapt a pre-trained source model online without requiring either source data or target labels. Our third contribution is to study SF-OUDA in a challenging setup where source data is synthetic and target data is point clouds captured in the real world. We use the recent SynLiDAR dataset as a synthetic source and introduce two new synthetic (source) datasets, which can stimulate future synthetic-to-real autonomous driving research. Our experiments show the effectiveness of our segmentation approach on thousands of real-world point clouds. Code and synthetic datasets are available at https://github.com/saltoricristiano/gipso-sfouda.
NVIDIA-UNIBZ Submission for EPIC-KITCHENS-100 Action Anticipation Challenge 2022
Jun 22, 2022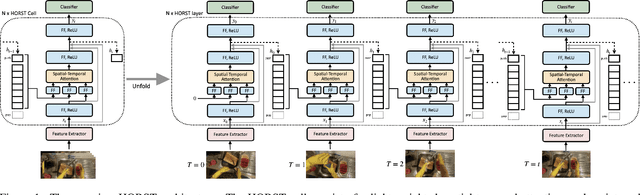
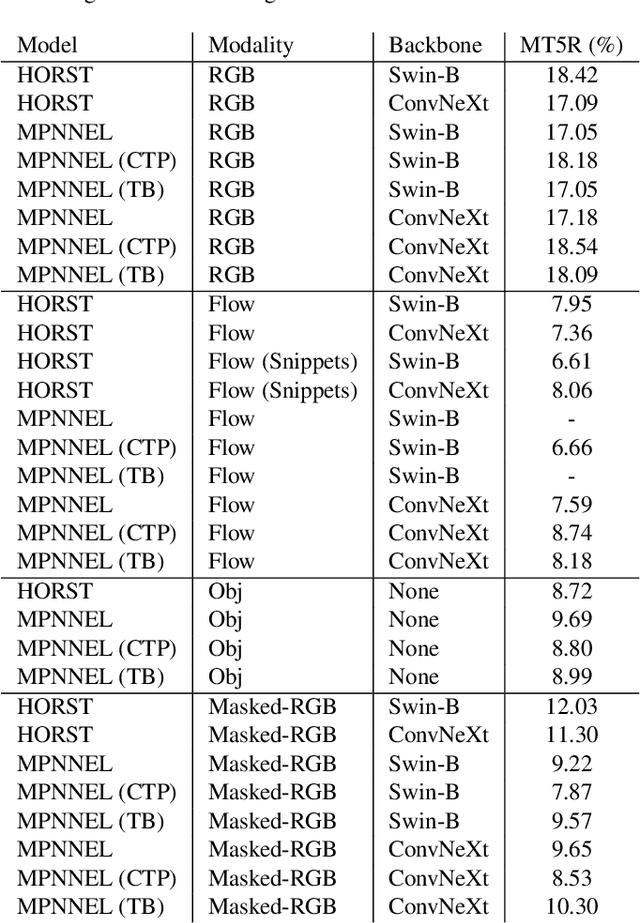

In this report, we describe the technical details of our submission for the EPIC-Kitchen-100 action anticipation challenge. Our modelings, the higher-order recurrent space-time transformer and the message-passing neural network with edge learning, are both recurrent-based architectures which observe only 2.5 seconds inference context to form the action anticipation prediction. By averaging the prediction scores from a set of models compiled with our proposed training pipeline, we achieved strong performance on the test set, which is 19.61% overall mean top-5 recall, recorded as second place on the public leaderboard.