 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatFuse: Controllable Material Generation with Diffusion Models
Aug 22, 2023Creating high quality and realistic materials in computer graphics is a challenging and time-consuming task, which requires great expertise. In this paper, we present MatFuse, a novel unified approach that harnesses the generative power of diffusion models (DM) to simplify the creation of SVBRDF maps. Our DM-based pipeline integrates multiple sources of conditioning, such as color palettes, sketches, and pictures, enabling fine-grained control and flexibility in material synthesis. This design allows for the combination of diverse information sources (e.g., sketch + image embedding), enhancing creative possibilities in line with the principle of compositionality. We demonstrate the generative capabilities of the proposed method under various conditioning settings; on the SVBRDF estimation task, we show that our method yields performance comparable to state-of-the-art approaches, both qualitatively and quantitatively.
RADiff: Controllable Diffusion Models for Radio Astronomical Maps Generation
Jul 05, 2023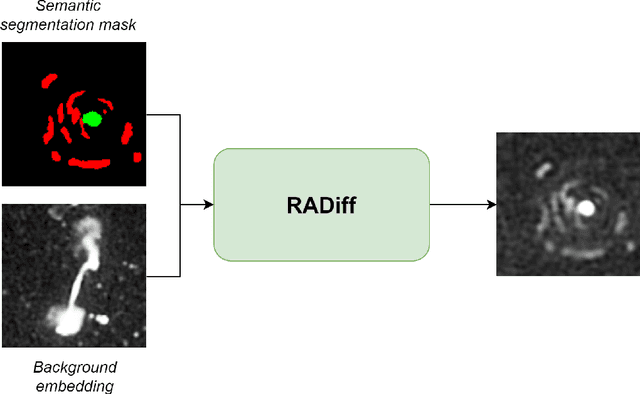
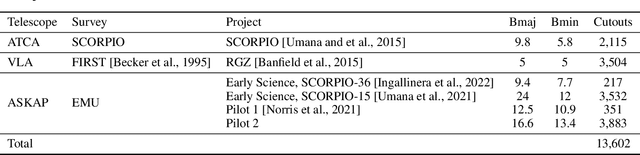
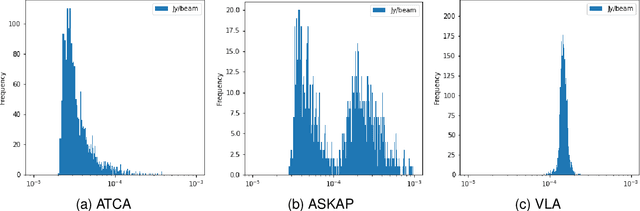
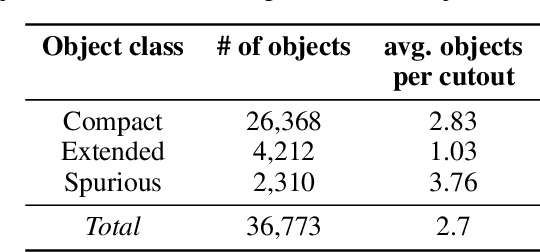
Along with the nearing completion of the Square Kilometre Array (SKA), comes an increasing demand for accurate and reliable automated solutions to extract valuable information from the vast amount of data it will allow acquiring. Automated source finding is a particularly important task in this context, as it enables the detection and classification of astronomical objects. Deep-learning-based object detection and semantic segmentation models have proven to be suitable for this purpose. However, training such deep networks requires a high volume of labeled data, which is not trivial to obtain in the context of radio astronomy. Since data needs to be manually labeled by experts, this process is not scalable to large dataset sizes, limiting the possibilities of leveraging deep networks to address several tasks. In this work, we propose RADiff, a generative approach based on conditional diffusion models trained over an annotated radio dataset to generate synthetic images, containing radio sources of different morphologies, to augment existing datasets and reduce the problems caused by class imbalances. We also show that it is possible to generate fully-synthetic image-annotation pairs to automatically augment any annotated dataset. We evaluate the effectiveness of this approach by training a semantic segmentation model on a real dataset augmented in two ways: 1) using synthetic images obtained from real masks, and 2) generating images from synthetic semantic masks. We show an improvement in performance when applying augmentation, gaining up to 18% in performance when using real masks and 4% when augmenting with synthetic masks. Finally, we employ this model to generate large-scale radio maps with the objective of simulating Data Challenges.
Transformer-based Image Generation from Scene Graphs
Mar 08, 2023Graph-structured scene descriptions can be efficiently used in generative models to control the composition of the generated image. Previous approaches are based on the combination of graph convolutional networks and adversarial methods for layout prediction and image generation, respectively. In this work, we show how employing multi-head attention to encode the graph information, as well as using a transformer-based model in the latent space for image generation can improve the quality of the sampled data, without the need to employ adversarial models with the subsequent advantage in terms of training stability. The proposed approach, specifically, is entirely based on transformer architectures both for encoding scene graphs into intermediate object layouts and for decoding these layouts into images, passing through a lower dimensional space learned by a vector-quantized variational autoencoder. Our approach shows an improved image quality with respect to state-of-the-art methods as well as a higher degree of diversity among multiple generations from the same scene graph. We evaluate our approach on three public datasets: Visual Genome, COCO, and CLEVR. We achieve an Inception Score of 13.7 and 12.8, and an FID of 52.3 and 60.3, on COCO and Visual Genome, respectively. We perform ablation studies on our contributions to assess the impact of each component. Code is available at https://github.com/perceivelab/trf-sg2im
Radio astronomical images object detection and segmentation: A benchmark on deep learning methods
Mar 08, 2023In recent years, deep learning has been successfully applied in various scientific domains. Following these promising results and performances, it has recently also started being evaluated in the domain of radio astronomy. In particular, since radio astronomy is entering the Big Data era, with the advent of the largest telescope in the world - the Square Kilometre Array (SKA), the task of automatic object detection and instance segmentation is crucial for source finding and analysis. In this work, we explore the performance of the most affirmed deep learning approaches, applied to astronomical images obtained by radio interferometric instrumentation, to solve the task of automatic source detection. This is carried out by applying models designed to accomplish two different kinds of tasks: object detection and semantic segmentation. The goal is to provide an overview of existing techniques, in terms of prediction performance and computational efficiency, to scientists in the astrophysics community who would like to employ machine learning in their research.
Transforming Image Generation from Scene Graphs
Jul 01, 2022



Generating images from semantic visual knowledge is a challenging task, that can be useful to condition the synthesis process in complex, subtle, and unambiguous ways, compared to alternatives such as class labels or text descriptions. Although generative methods conditioned by semantic representations exist, they do not provide a way to control the generation process aside from the specification of constraints between objects. As an example, the possibility to iteratively generate or modify images by manually adding specific items is a desired property that, to our knowledge, has not been fully investigated in the literature. In this work we propose a transformer-based approach conditioned by scene graphs that, conversely to recent transformer-based methods, also employs a decoder to autoregressively compose images, making the synthesis process more effective and controllable. The proposed architecture is composed by three modules: 1) a graph convolutional network, to encode the relationships of the input graph; 2) an encoder-decoder transformer, which autoregressively composes the output image; 3) an auto-encoder, employed to generate representations used as input/output of each generation step by the transformer. Results obtained on CIFAR10 and MNIST images show that our model is able to satisfy semantic constraints defined by a scene graph and to model relations between visual objects in the scene by taking into account a user-provided partial rendering of the desired target.