 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantFormer: Learning to Quantize for Neural Activity Forecasting in Mouse Visual Cortex
Dec 10, 2024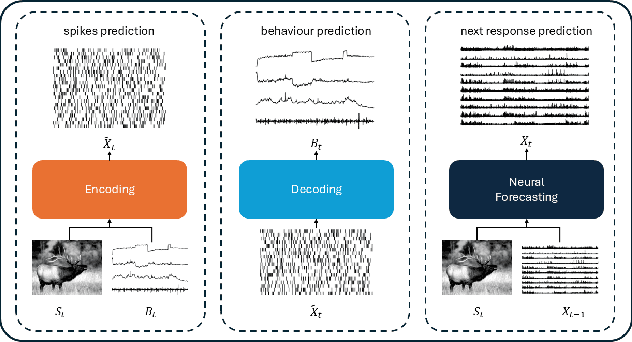
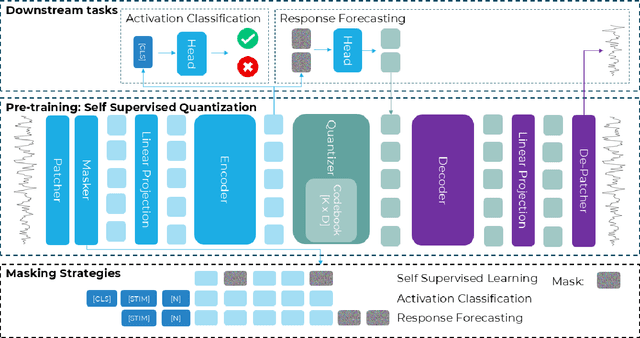
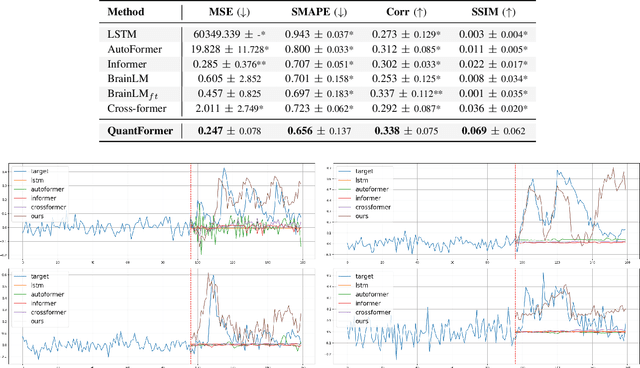
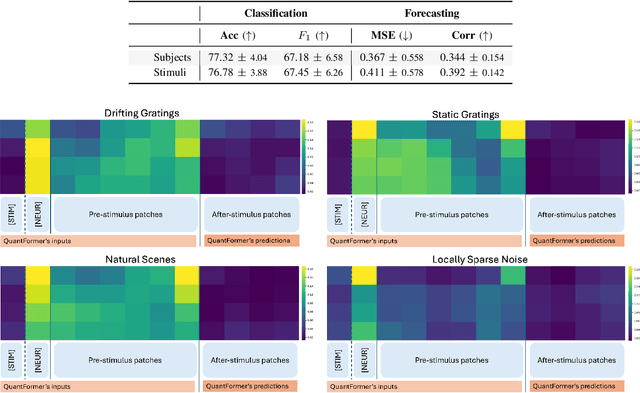
Understanding complex animal behaviors hinges on deciphering the neural activity patterns within brain circuits, making the ability to forecast neural activity crucial for developing predictive models of brain dynamics. This capability holds immense value for neuroscience, particularly in applications such as real-time optogenetic interventions. While traditional encoding and decoding methods have been used to map external variables to neural activity and vice versa, they focus on interpreting past data. In contrast, neural forecasting aims to predict future neural activity, presenting a unique and challenging task due to the spatiotemporal sparsity and complex dependencies of neural signals. Existing transformer-based forecasting methods, while effective in many domains, struggle to capture the distinctiveness of neural signals characterized by spatiotemporal sparsity and intricate dependencies. To address this challenge, we here introduce QuantFormer, a transformer-based model specifically designed for forecasting neural activity from two-photon calcium imaging data. Unlike conventional regression-based approaches, QuantFormerreframes the forecasting task as a classification problem via dynamic signal quantization, enabling more effective learning of sparse neural activation patterns. Additionally, QuantFormer tackles the challenge of analyzing multivariate signals from an arbitrary number of neurons by incorporating neuron-specific tokens, allowing scalability across diverse neuronal populations. Trained with unsupervised quantization on the Allen dataset, QuantFormer sets a new benchmark in forecasting mouse visual cortex activity. It demonstrates robust performance and generalization across various stimuli and individuals, paving the way for a foundational model in neural signal prediction.
Self-supervised learning for radio-astronomy source classification: a benchmark
Nov 22, 2024The upcoming Square Kilometer Array (SKA) telescope marks a significant step forward in radio astronomy, presenting new opportunities and challenges for data analysis. Traditional visual models pretrained on optical photography images may not perform optimally on radio interferometry images, which have distinct visual characteristics. Self-Supervised Learning (SSL) offers a promising approach to address this issue, leveraging the abundant unlabeled data in radio astronomy to train neural networks that learn useful representations from radio images. This study explores the application of SSL to radio astronomy, comparing the performance of SSL-trained models with that of traditional models pretrained on natural images, evaluating the importance of data curation for SSL, and assessing the potential benefits of self-supervision to different domain-specific radio astronomy datasets. Our results indicate that, SSL-trained models achieve significant improvements over the baseline in several downstream tasks, especially in the linear evaluation setting; when the entire backbone is fine-tuned, the benefits of SSL are less evident but still outperform pretraining. These findings suggest that SSL can play a valuable role in efficiently enhancing the analysis of radio astronomical data. The trained models and code is available at: \url{https://github.com/dr4thmos/solo-learn-radio}
Back to Supervision: Boosting Word Boundary Detection through Frame Classification
Nov 15, 2024

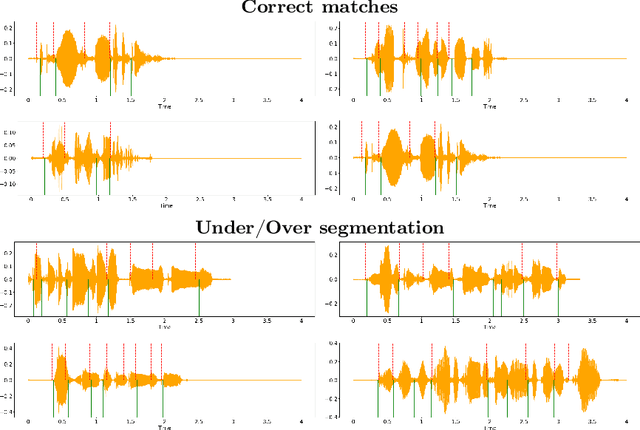

Speech segmentation at both word and phoneme levels is crucial for various speech processing tasks. It significantly aids in extracting meaningful units from an utterance, thus enabling the generation of discrete elements. In this work we propose a model-agnostic framework to perform word boundary detection in a supervised manner also employing a labels augmentation technique and an output-frame selection strategy. We trained and tested on the Buckeye dataset and only tested on TIMIT one, using state-of-the-art encoder models, including pre-trained solutions (Wav2Vec 2.0 and HuBERT), as well as convolutional and convolutional recurrent networks. Our method, with the HuBERT encoder, surpasses the performance of other state-of-the-art architectures, whether trained in supervised or self-supervised settings on the same datasets. Specifically, we achieved F-values of 0.8427 on the Buckeye dataset and 0.7436 on the TIMIT dataset, along with R-values of 0.8489 and 0.7807, respectively. These results establish a new state-of-the-art for both datasets. Beyond the immediate task, our approach offers a robust and efficient preprocessing method for future research in audio tokenization.
Evidential Federated Learning for Skin Lesion Image Classification
Nov 15, 2024We introduce FedEvPrompt, a federated learning approach that integrates principles of evidential deep learning, prompt tuning, and knowledge distillation for distributed skin lesion classification. FedEvPrompt leverages two sets of prompts: b-prompts (for low-level basic visual knowledge) and t-prompts (for task-specific knowledge) prepended to frozen pre-trained Vision Transformer (ViT) models trained in an evidential learning framework to maximize class evidences. Crucially, knowledge sharing across federation clients is achieved only through knowledge distillation on attention maps generated by the local ViT models, ensuring enhanced privacy preservation compared to traditional parameter or synthetic image sharing methodologies. FedEvPrompt is optimized within a round-based learning paradigm, where each round involves training local models followed by attention maps sharing with all federation clients. Experimental validation conducted in a real distributed setting, on the ISIC2019 dataset, demonstrates the superior performance of FedEvPrompt against baseline federated learning algorithms and knowledge distillation methods, without sharing model parameters. In conclusion, FedEvPrompt offers a promising approach for federated learning, effectively addressing challenges such as data heterogeneity, imbalance, privacy preservation, and knowledge sharing.
FedRewind: Rewinding Continual Model Exchange for Decentralized Federated Learning
Nov 14, 2024



In this paper, we present FedRewind, a novel approach to decentralized federated learning that leverages model exchange among nodes to address the issue of data distribution shift. Drawing inspiration from continual learning (CL) principles and cognitive neuroscience theories for memory retention, FedRewind implements a decentralized routing mechanism where nodes send/receive models to/from other nodes in the federation to address spatial distribution challenges inherent in distributed learning (FL). During local training, federation nodes periodically send their models back (i.e., rewind) to the nodes they received them from for a limited number of iterations. This strategy reduces the distribution shift between nodes' data, leading to enhanced learning and generalization performance. We evaluate our method on multiple benchmarks, demonstrating its superiority over standard decentralized federated learning methods and those enforcing specific routing schemes within the federation. Furthermore, the combination of federated and continual learning concepts enables our method to tackle the more challenging federated continual learning task, with data shifts over both space and time, surpassing existing baselines.
Diffexplainer: Towards Cross-modal Global Explanations with Diffusion Models
Apr 03, 2024



We present DiffExplainer, a novel framework that, leveraging language-vision models, enables multimodal global explainability. DiffExplainer employs diffusion models conditioned on optimized text prompts, synthesizing images that maximize class outputs and hidden features of a classifier, thus providing a visual tool for explaining decisions. Moreover, the analysis of generated visual descriptions allows for automatic identification of biases and spurious features, as opposed to traditional methods that often rely on manual intervention. The cross-modal transferability of language-vision models also enables the possibility to describe decisions in a more human-interpretable way, i.e., through text. We conduct comprehensive experiments, which include an extensive user study, demonstrating the effectiveness of DiffExplainer on 1) the generation of high-quality images explaining model decisions, surpassing existing activation maximization methods, and 2) the automated identification of biases and spurious features.
SalFoM: Dynamic Saliency Prediction with Video Foundation Models
Apr 03, 2024



Recent advancements in video saliency prediction (VSP) have shown promising performance compared to the human visual system, whose emulation is the primary goal of VSP. However, current state-of-the-art models employ spatio-temporal transformers trained on limited amounts of data, hindering generalizability adaptation to downstream tasks. The benefits of vision foundation models present a potential solution to improve the VSP process. However, adapting image foundation models to the video domain presents significant challenges in modeling scene dynamics and capturing temporal information. To address these challenges, and as the first initiative to design a VSP model based on video foundation models, we introduce SalFoM, a novel encoder-decoder video transformer architecture. Our model employs UnMasked Teacher (UMT) as feature extractor and presents a heterogeneous decoder which features a locality-aware spatio-temporal transformer and integrates local and global spatio-temporal information from various perspectives to produce the final saliency map. Our qualitative and quantitative experiments on the challenging VSP benchmark datasets of DHF1K, Hollywood-2 and UCF-Sports demonstrate the superiority of our proposed model in comparison with the state-of-the-art methods.
Selective Attention-based Modulation for Continual Learning
Mar 29, 2024



We present SAM, a biologically-plausible selective attention-driven modulation approach to enhance classification models in a continual learning setting. Inspired by neurophysiological evidence that the primary visual cortex does not contribute to object manifold untangling for categorization and that primordial attention biases are still embedded in the modern brain, we propose to employ auxiliary saliency prediction features as a modulation signal to drive and stabilize the learning of a sequence of non-i.i.d. classification tasks. Experimental results confirm that SAM effectively enhances the performance (in some cases up to about twenty percent points) of state-of-the-art continual learning methods, both in class-incremental and task-incremental settings. Moreover, we show that attention-based modulation successfully encourages the learning of features that are more robust to the presence of spurious features and to adversarial attacks than baseline methods. Code is available at: https://github.com/perceivelab/SAM.
Transformer-based Video Saliency Prediction with High Temporal Dimension Decoding
Jan 15, 2024
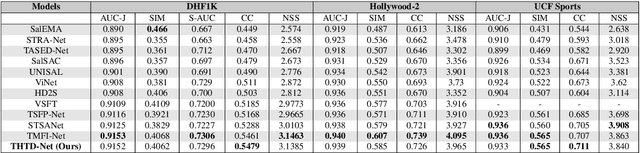


In recent years, finding an effective and efficient strategy for exploiting spatial and temporal information has been a hot research topic in video saliency prediction (VSP). With the emergence of spatio-temporal transformers, the weakness of the prior strategies, e.g., 3D convolutional networks and LSTM-based networks, for capturing long-range dependencies has been effectively compensated. While VSP has drawn benefits from spatio-temporal transformers, finding the most effective way for aggregating temporal features is still challenging. To address this concern, we propose a transformer-based video saliency prediction approach with high temporal dimension decoding network (THTD-Net). This strategy accounts for the lack of complex hierarchical interactions between features that are extracted from the transformer-based spatio-temporal encoder: in particular, it does not require multiple decoders and aims at gradually reducing temporal features' dimensions in the decoder. This decoder-based architecture yields comparable performance to multi-branch and over-complicated models on common benchmarks such as DHF1K, UCF-sports and Hollywood-2.
MatFuse: Controllable Material Generation with Diffusion Models
Aug 22, 2023Creating high quality and realistic materials in computer graphics is a challenging and time-consuming task, which requires great expertise. In this paper, we present MatFuse, a novel unified approach that harnesses the generative power of diffusion models (DM) to simplify the creation of SVBRDF maps. Our DM-based pipeline integrates multiple sources of conditioning, such as color palettes, sketches, and pictures, enabling fine-grained control and flexibility in material synthesis. This design allows for the combination of diverse information sources (e.g., sketch + image embedding), enhancing creative possibilities in line with the principle of compositionality. We demonstrate the generative capabilities of the proposed method under various conditioning settings; on the SVBRDF estimation task, we show that our method yields performance comparable to state-of-the-art approaches, both qualitatively and quantitatively.