 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantFormer: Learning to Quantize for Neural Activity Forecasting in Mouse Visual Cortex
Dec 10, 2024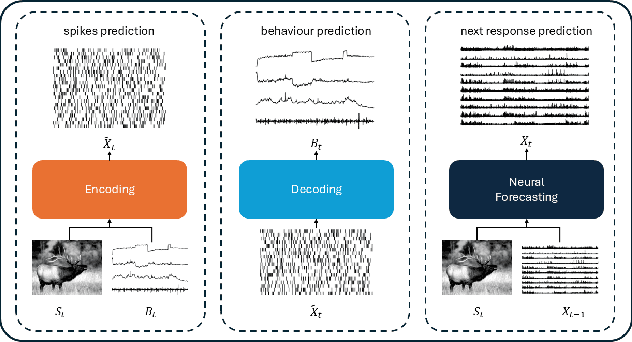
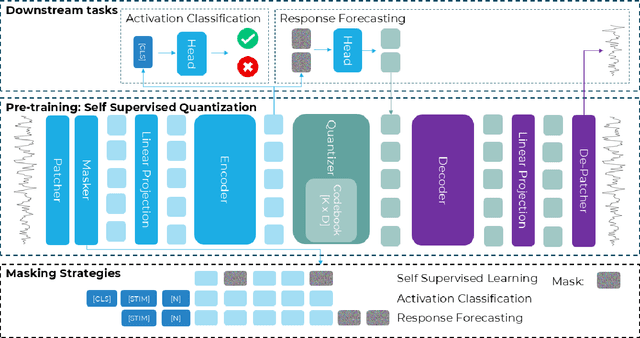
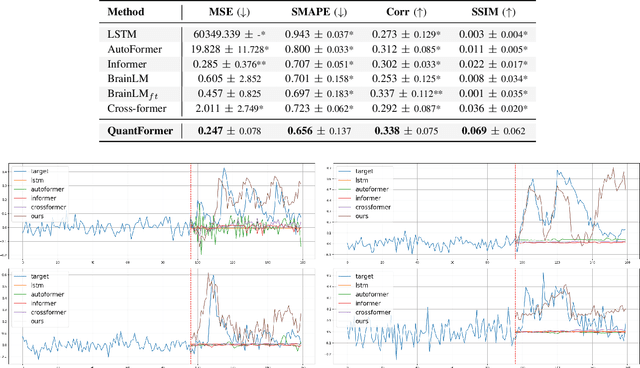
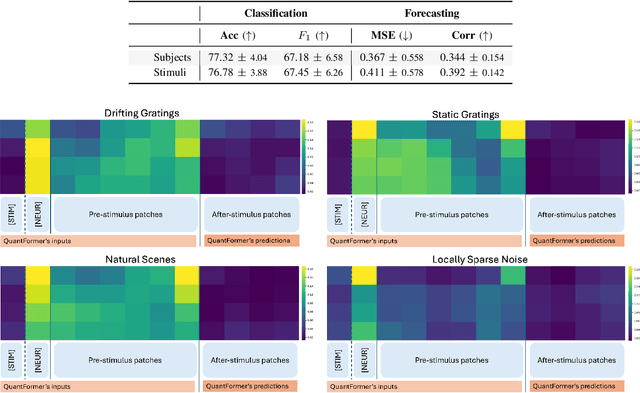
Understanding complex animal behaviors hinges on deciphering the neural activity patterns within brain circuits, making the ability to forecast neural activity crucial for developing predictive models of brain dynamics. This capability holds immense value for neuroscience, particularly in applications such as real-time optogenetic interventions. While traditional encoding and decoding methods have been used to map external variables to neural activity and vice versa, they focus on interpreting past data. In contrast, neural forecasting aims to predict future neural activity, presenting a unique and challenging task due to the spatiotemporal sparsity and complex dependencies of neural signals. Existing transformer-based forecasting methods, while effective in many domains, struggle to capture the distinctiveness of neural signals characterized by spatiotemporal sparsity and intricate dependencies. To address this challenge, we here introduce QuantFormer, a transformer-based model specifically designed for forecasting neural activity from two-photon calcium imaging data. Unlike conventional regression-based approaches, QuantFormerreframes the forecasting task as a classification problem via dynamic signal quantization, enabling more effective learning of sparse neural activation patterns. Additionally, QuantFormer tackles the challenge of analyzing multivariate signals from an arbitrary number of neurons by incorporating neuron-specific tokens, allowing scalability across diverse neuronal populations. Trained with unsupervised quantization on the Allen dataset, QuantFormer sets a new benchmark in forecasting mouse visual cortex activity. It demonstrates robust performance and generalization across various stimuli and individuals, paving the way for a foundational model in neural signal prediction.
Back to Supervision: Boosting Word Boundary Detection through Frame Classification
Nov 15, 2024

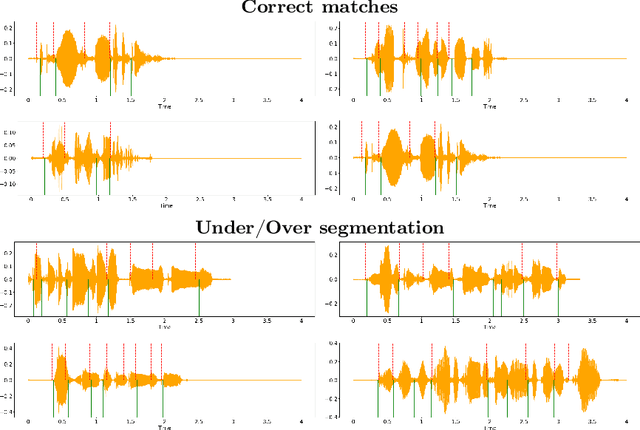

Speech segmentation at both word and phoneme levels is crucial for various speech processing tasks. It significantly aids in extracting meaningful units from an utterance, thus enabling the generation of discrete elements. In this work we propose a model-agnostic framework to perform word boundary detection in a supervised manner also employing a labels augmentation technique and an output-frame selection strategy. We trained and tested on the Buckeye dataset and only tested on TIMIT one, using state-of-the-art encoder models, including pre-trained solutions (Wav2Vec 2.0 and HuBERT), as well as convolutional and convolutional recurrent networks. Our method, with the HuBERT encoder, surpasses the performance of other state-of-the-art architectures, whether trained in supervised or self-supervised settings on the same datasets. Specifically, we achieved F-values of 0.8427 on the Buckeye dataset and 0.7436 on the TIMIT dataset, along with R-values of 0.8489 and 0.7807, respectively. These results establish a new state-of-the-art for both datasets. Beyond the immediate task, our approach offers a robust and efficient preprocessing method for future research in audio tokenization.
A baseline on continual learning methods for video action recognition
Apr 26, 2023Continual learning has recently attracted attention from the research community, as it aims to solve long-standing limitations of classic supervisedly-trained models. However, most research on this subject has tackled continual learning in simple image classification scenarios. In this paper, we present a benchmark of state-of-the-art continual learning methods on video action recognition. Besides the increased complexity due to the temporal dimension, the video setting imposes stronger requirements on computing resources for top-performing rehearsal methods. To counteract the increased memory requirements, we present two method-agnostic variants for rehearsal methods, exploiting measures of either model confidence or data information to select memorable samples. Our experiments show that, as expected from the literature, rehearsal methods outperform other approaches; moreover, the proposed memory-efficient variants are shown to be effective at retaining a certain level of performance with a smaller buffer size.
Neural Transformers for Intraductal Papillary Mucosal Neoplasms (IPMN) Classification in MRI images
Jun 21, 2022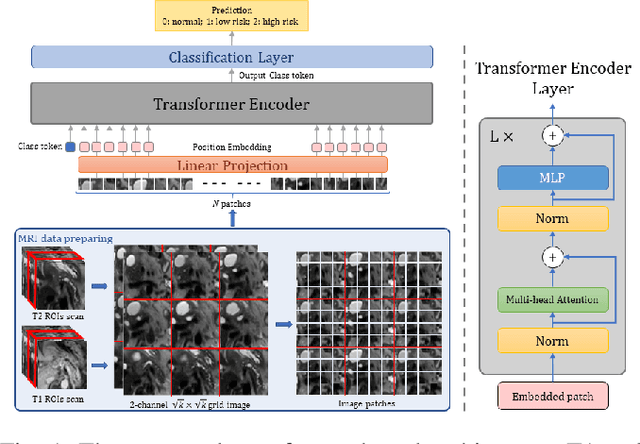
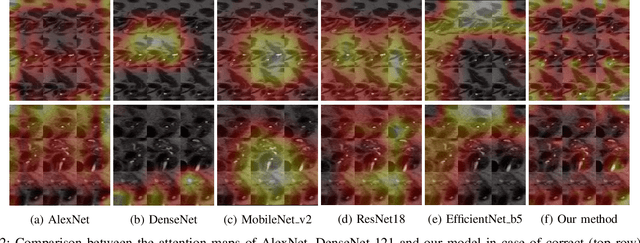

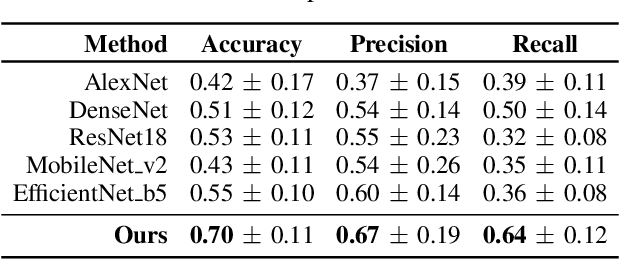
Early detection of precancerous cysts or neoplasms, i.e., Intraductal Papillary Mucosal Neoplasms (IPMN), in pancreas is a challenging and complex task, and it may lead to a more favourable outcome. Once detected, grading IPMNs accurately is also necessary, since low-risk IPMNs can be under surveillance program, while high-risk IPMNs have to be surgically resected before they turn into cancer. Current standards (Fukuoka and others) for IPMN classification show significant intra- and inter-operator variability, beside being error-prone, making a proper diagnosis unreliable. The established progress in artificial intelligence, through the deep learning paradigm, may provide a key tool for an effective support to medical decision for pancreatic cancer. In this work, we follow this trend, by proposing a novel AI-based IPMN classifier that leverages the recent success of transformer networks in generalizing across a wide variety of tasks, including vision ones. We specifically show that our transformer-based model exploits pre-training better than standard convolutional neural networks, thus supporting the sought architectural universalism of transformers in vision, including the medical image domain and it allows for a better interpretation of the obtained results.
Correct block-design experiments mitigate temporal correlation bias in EEG classification
Nov 25, 2020It is argued in [1] that [2] was able to classify EEG responses to visual stimuli solely because of the temporal correlation that exists in all EEG data and the use of a block design. We here show that the main claim in [1] is drastically overstated and their other analyses are seriously flawed by wrong methodological choices. To validate our counter-claims, we evaluate the performance of state-of-the-art methods on the dataset in [2] reaching about 50% classification accuracy over 40 classes, lower than in [2], but still significant. We then investigate the influence of EEG temporal correlation on classification accuracy by testing the same models in two additional experimental settings: one that replicates [1]'s rapid-design experiment, and another one that examines the data between blocks while subjects are shown a blank screen. In both cases, classification accuracy is at or near chance, in contrast to what [1] reports, indicating a negligible contribution of temporal correlation to classification accuracy. We, instead, are able to replicate the results in [1] only when intentionally contaminating our data by inducing a temporal correlation. This suggests that what Li et al. [1] demonstrate is that their data are strongly contaminated by temporal correlation and low signal-to-noise ratio. We argue that the reason why Li et al. [1] observe such high correlation in EEG data is their unconventional experimental design and settings that violate the basic cognitive neuroscience design recommendations, first and foremost the one of limiting the experiments' duration, as instead done in [2]. Our analyses in this paper refute the claims of the "perils and pitfalls of block-design" in [1]. Finally, we conclude the paper by examining a number of other oversimplistic statements, inconsistencies, misinterpretation of machine learning concepts, speculations and misleading claims in [1].
Video Saliency Detection with Domain Adaptation using Hierarchical Gradient Reversal Layers
Oct 06, 2020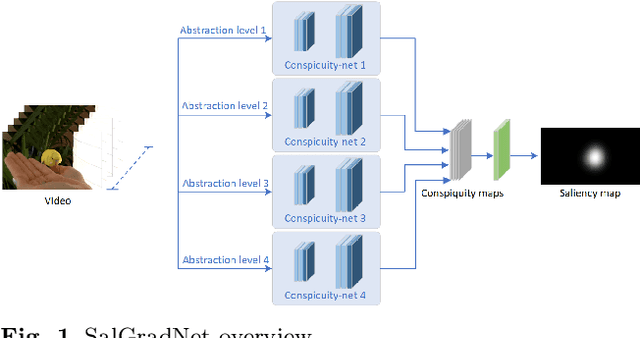
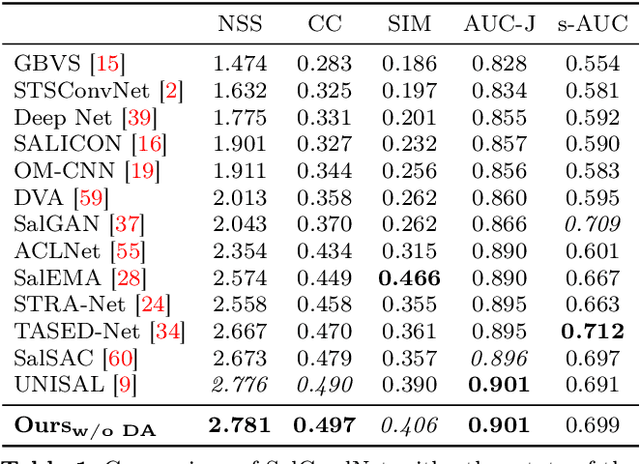

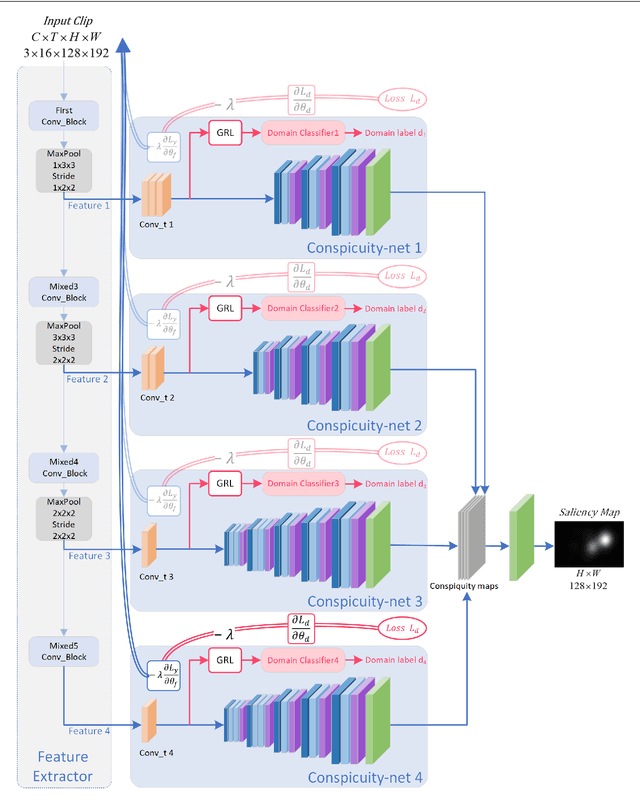
In this work, we propose a 3D fully convolutional architecture for video saliency detection that employs multi-head supervision on intermediate maps (referred to as conspicuity maps) generated using features extracted at different abstraction level. More specifically, the model employs a single encoder and features extracted at different levels are then passed to multiple decoders aiming at predicting multiple saliency instances that are finally combined to obtain final output saliency maps. We also combine the hierarchical features extracted from the model's encoder with a domain adaptation approach based on gradient reversal at multiple scales in order to improve the generalization capabilities on datasets for which no annotations are provided during training. The results of our experiments on standard benchmarks, namely DHF1K, Hollywood2 and UCF Sports, show that the proposed model outperforms state-of-the-art methods on most metrics for supervised saliency prediction. Moreover, when tested in an unsupervised settings, it is able to obtain performance comparable to those achieved by supervised state-of-the-art methods.
Domain Adaptation for Outdoor Robot Traversability Estimation from RGB data with Safety-Preserving Loss
Sep 16, 2020
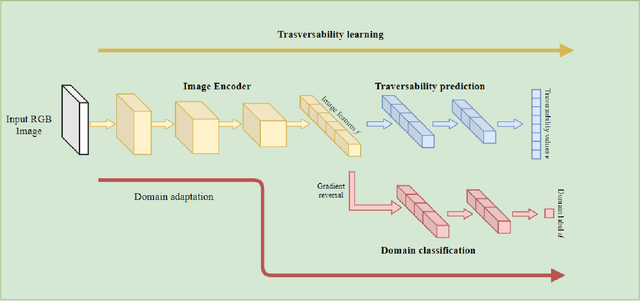


Being able to estimate the traversability of the area surrounding a mobile robot is a fundamental task in the design of a navigation algorithm. However, the task is often complex, since it requires evaluating distances from obstacles, type and slope of terrain, and dealing with non-obvious discontinuities in detected distances due to perspective. In this paper, we present an approach based on deep learning to estimate and anticipate the traversing score of different routes in the field of view of an on-board RGB camera. The backbone of the proposed model is based on a state-of-the-art deep segmentation model, which is fine-tuned on the task of predicting route traversability. We then enhance the model's capabilities by a) addressing domain shifts through gradient-reversal unsupervised adaptation, and b) accounting for the specific safety requirements of a mobile robot, by encouraging the model to err on the safe side, i.e., penalizing errors that would cause collisions with obstacles more than those that would cause the robot to stop in advance. Experimental results show that our approach is able to satisfactorily identify traversable areas and to generalize to unseen locations.
Decoding Brain Representations by Multimodal Learning of Neural Activity and Visual Features
Oct 25, 2018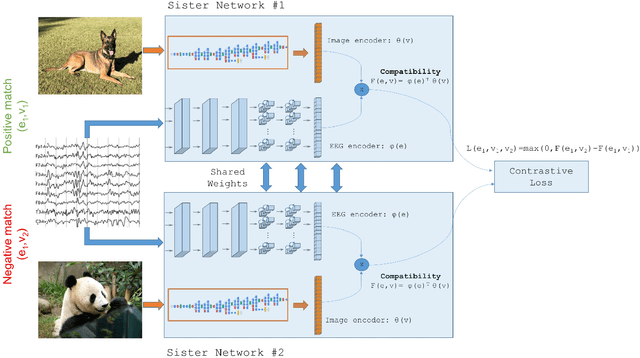
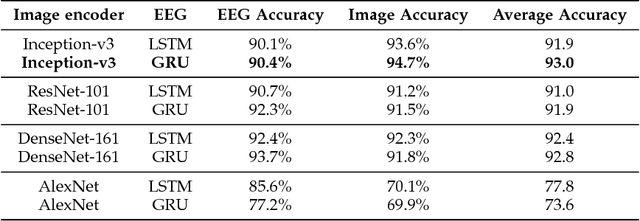
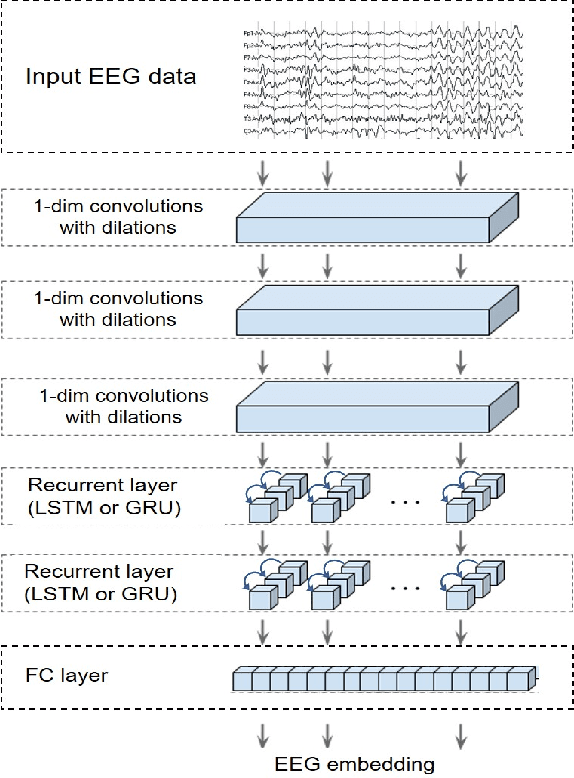
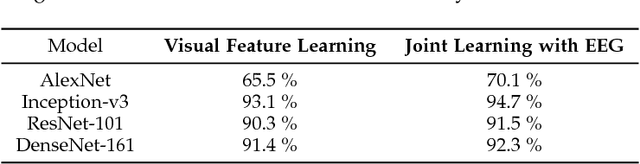
This paper tackles the problem of learning brain-visual representations for understanding and neural processes behind human visual perception, with a view towards replicating these processes into machines. The core idea is to learn plausible representations through the combined use of human neural activity evoked by natural images as a supervision mechanism for deep learning models. To accomplish this, we propose a multimodal approach that uses two different deep encoders, one for images and one for EEGs, trained in a siamese configuration for learning a joint manifold that maximizes a compatibility measure between visual features and brain representation. The learned manifold is then used to perform image classification and saliency detection as well as to shed light on the possible representations generated by the human brain when perceiving the visual world. Performance analysis shows that neural signals can be used to effectively supervise the training of deep learning models, as demonstrated by the achieved performance in both image classification and saliency detection. Furthermore, the learned brain-visual manifold is consistent with cognitive neuroscience literature about visual perception and, most importantly, highlights new associations between brain areas, image patches and computational kernels. In particular, we are able to approximate brain responses to visual stimuli by training an artificial model with image features correlated to neural activity.
Deep Learning Human Mind for Automated Visual Classification
Sep 01, 2016

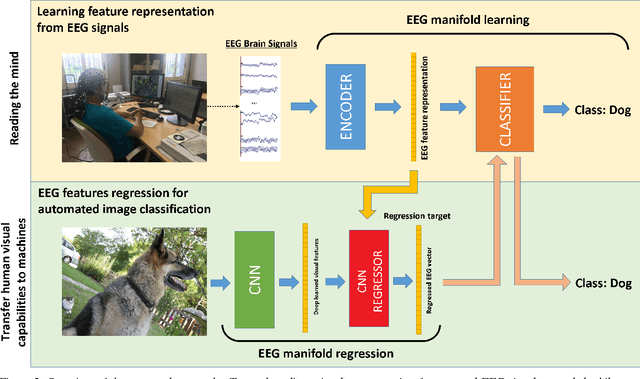
What if we could effectively read the mind and transfer human visual capabilities to computer vision methods? In this paper, we aim at addressing this question by developing the first visual object classifier driven by human brain signals. In particular, we employ EEG data evoked by visual object stimuli combined with Recurrent Neural Networks (RNN) to learn a discriminative brain activity manifold of visual categories. Afterwards, we train a Convolutional Neural Network (CNN)-based regressor to project images onto the learned manifold, thus effectively allowing machines to employ human brain-based features for automated visual classification. We use a 32-channel EEG to record brain activity of seven subjects while looking at images of 40 ImageNet object classes. The proposed RNN based approach for discriminating object classes using brain signals reaches an average accuracy of about 40%, which outperforms existing methods attempting to learn EEG visual object representations. As for automated object categorization, our human brain-driven approach obtains competitive performance, comparable to those achieved by powerful CNN models, both on ImageNet and CalTech 101, thus demonstrating its classification and generalization capabilities. This gives us a real hope that, indeed, human mind can be read and transferred to machines.
Gamifying Video Object Segmentation
Jan 05, 2016



Video object segmentation can be considered as one of the most challenging computer vision problems. Indeed, so far, no existing solution is able to effectively deal with the peculiarities of real-world videos, especially in cases of articulated motion and object occlusions; limitations that appear more evident when we compare their performance with the human one. However, manually segmenting objects in videos is largely impractical as it requires a lot of human time and concentration. To address this problem, in this paper we propose an interactive video object segmentation method, which exploits, on one hand, the capability of humans to identify correctly objects in visual scenes, and on the other hand, the collective human brainpower to solve challenging tasks. In particular, our method relies on a web game to collect human inputs on object locations, followed by an accurate segmentation phase achieved by optimizing an energy function encoding spatial and temporal constraints between object regions as well as human-provided input. Performance analysis carried out on challenging video datasets with some users playing the game demonstrated that our method shows a better trade-off between annotation times and segmentation accuracy than interactive video annotation and automated video object segmentation approaches.