 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi and Weakly Supervised Semantic Segmentation Using Generative Adversarial Network
Mar 28, 2017
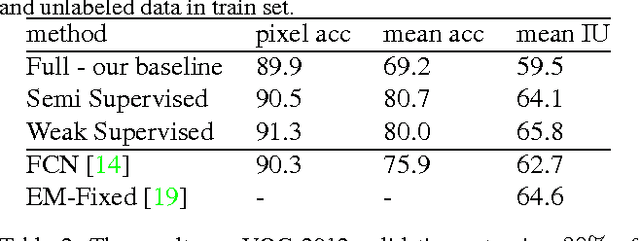


Semantic segmentation has been a long standing challenging task in computer vision. It aims at assigning a label to each image pixel and needs significant number of pixellevel annotated data, which is often unavailable. To address this lack, in this paper, we leverage, on one hand, massive amount of available unlabeled or weakly labeled data, and on the other hand, non-real images created through Generative Adversarial Networks. In particular, we propose a semi-supervised framework ,based on Generative Adversarial Networks (GANs), which consists of a generator network to provide extra training examples to a multi-class classifier, acting as discriminator in the GAN framework, that assigns sample a label y from the K possible classes or marks it as a fake sample (extra class). The underlying idea is that adding large fake visual data forces real samples to be close in the feature space, enabling a bottom-up clustering process, which, in turn, improves multiclass pixel classification. To ensure higher quality of generated images for GANs with consequent improved pixel classification, we extend the above framework by adding weakly annotated data, i.e., we provide class level information to the generator. We tested our approaches on several challenging benchmarking visual datasets, i.e. PASCAL, SiftFLow, Stanford and CamVid, achieving competitive performance also compared to state-of-the-art semantic segmentation method
Deep Learning Human Mind for Automated Visual Classification
Sep 01, 2016

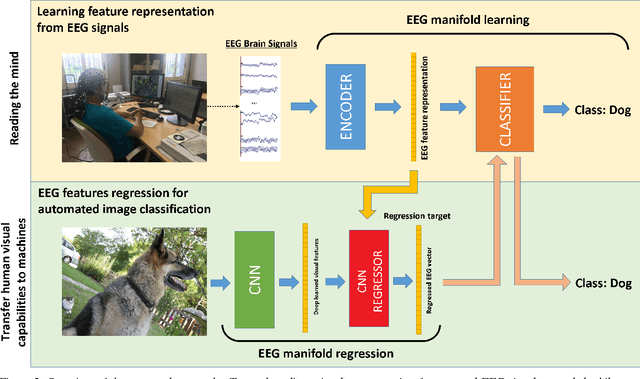
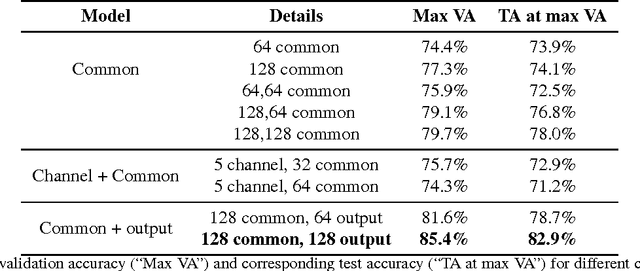
What if we could effectively read the mind and transfer human visual capabilities to computer vision methods? In this paper, we aim at addressing this question by developing the first visual object classifier driven by human brain signals. In particular, we employ EEG data evoked by visual object stimuli combined with Recurrent Neural Networks (RNN) to learn a discriminative brain activity manifold of visual categories. Afterwards, we train a Convolutional Neural Network (CNN)-based regressor to project images onto the learned manifold, thus effectively allowing machines to employ human brain-based features for automated visual classification. We use a 32-channel EEG to record brain activity of seven subjects while looking at images of 40 ImageNet object classes. The proposed RNN based approach for discriminating object classes using brain signals reaches an average accuracy of about 40%, which outperforms existing methods attempting to learn EEG visual object representations. As for automated object categorization, our human brain-driven approach obtains competitive performance, comparable to those achieved by powerful CNN models, both on ImageNet and CalTech 101, thus demonstrating its classification and generalization capabilities. This gives us a real hope that, indeed, human mind can be read and transferred to machines.
Scene Labeling Through Knowledge-Based Rules Employing Constrained Integer Linear Programing
Aug 17, 2016


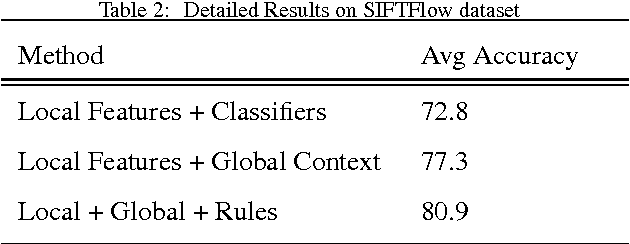
Scene labeling task is to segment the image into meaningful regions and categorize them into classes of objects which comprised the image. Commonly used methods typically find the local features for each segment and label them using classifiers. Afterward, labeling is smoothed in order to make sure that neighboring regions receive similar labels. However, they ignore expressive and non-local dependencies among regions due to expensive training and inference. In this paper, we propose to use high-level knowledge regarding rules in the inference to incorporate dependencies among regions in the image to improve scores of classification. Towards this aim, we extract these rules from data and transform them into constraints for Integer Programming to optimize the structured problem of assigning labels to super-pixels (consequently pixels) of an image. In addition, we propose to use soft-constraints in some scenarios, allowing violating the constraint by imposing a penalty, to make the model more flexible. We assessed our approach on three datasets and obtained promising results.
Covariance of Motion and Appearance Featuresfor Spatio Temporal Recognition Tasks
Jun 16, 2016



In this paper, we introduce an end-to-end framework for video analysis focused towards practical scenarios built on theoretical foundations from sparse representation, including a novel descriptor for general purpose video analysis. In our approach, we compute kinematic features from optical flow and first and second-order derivatives of intensities to represent motion and appearance respectively. These features are then used to construct covariance matrices which capture joint statistics of both low-level motion and appearance features extracted from a video. Using an over-complete dictionary of the covariance based descriptors built from labeled training samples, we formulate low-level event recognition as a sparse linear approximation problem. Within this, we pose the sparse decomposition of a covariance matrix, which also conforms to the space of semi-positive definite matrices, as a determinant maximization problem. Also since covariance matrices lie on non-linear Riemannian manifolds, we compare our former approach with a sparse linear approximation alternative that is suitable for equivalent vector spaces of covariance matrices. This is done by searching for the best projection of the query data on a dictionary using an Orthogonal Matching pursuit algorithm. We show the applicability of our video descriptor in two different application domains - namely low-level event recognition in unconstrained scenarios and gesture recognition using one shot learning. Our experiments provide promising insights in large scale video analysis.