 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantFormer: Learning to Quantize for Neural Activity Forecasting in Mouse Visual Cortex
Dec 10, 2024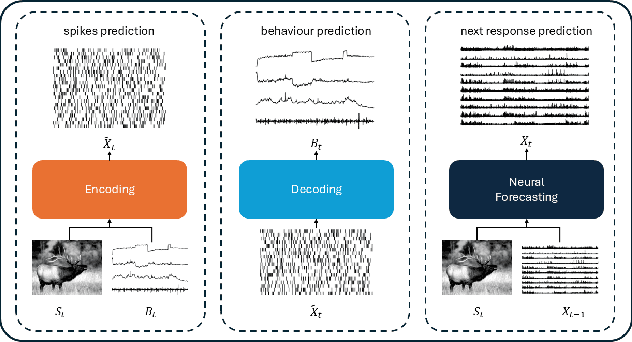
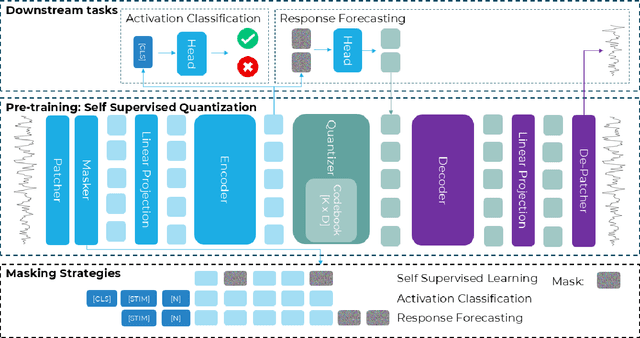
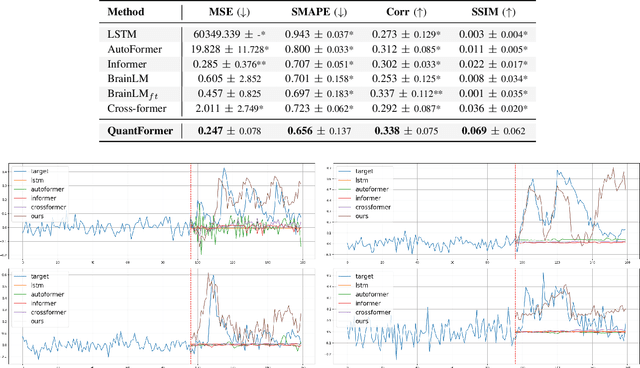
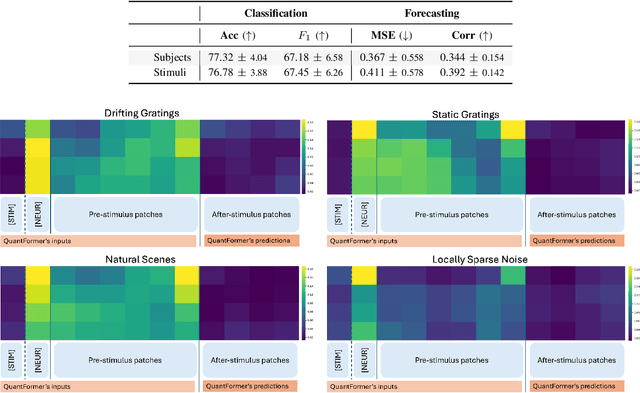
Understanding complex animal behaviors hinges on deciphering the neural activity patterns within brain circuits, making the ability to forecast neural activity crucial for developing predictive models of brain dynamics. This capability holds immense value for neuroscience, particularly in applications such as real-time optogenetic interventions. While traditional encoding and decoding methods have been used to map external variables to neural activity and vice versa, they focus on interpreting past data. In contrast, neural forecasting aims to predict future neural activity, presenting a unique and challenging task due to the spatiotemporal sparsity and complex dependencies of neural signals. Existing transformer-based forecasting methods, while effective in many domains, struggle to capture the distinctiveness of neural signals characterized by spatiotemporal sparsity and intricate dependencies. To address this challenge, we here introduce QuantFormer, a transformer-based model specifically designed for forecasting neural activity from two-photon calcium imaging data. Unlike conventional regression-based approaches, QuantFormerreframes the forecasting task as a classification problem via dynamic signal quantization, enabling more effective learning of sparse neural activation patterns. Additionally, QuantFormer tackles the challenge of analyzing multivariate signals from an arbitrary number of neurons by incorporating neuron-specific tokens, allowing scalability across diverse neuronal populations. Trained with unsupervised quantization on the Allen dataset, QuantFormer sets a new benchmark in forecasting mouse visual cortex activity. It demonstrates robust performance and generalization across various stimuli and individuals, paving the way for a foundational model in neural signal prediction.
An Explainable AI System for Automated COVID-19 Assessment and Lesion Categorization from CT-scans
Jan 28, 2021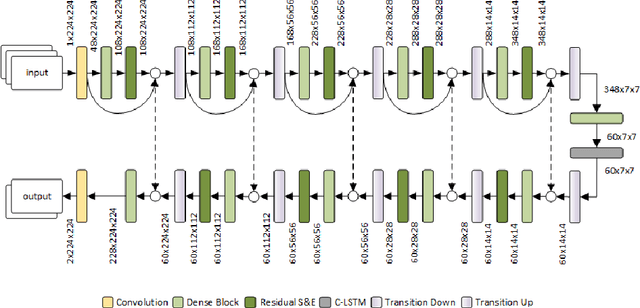
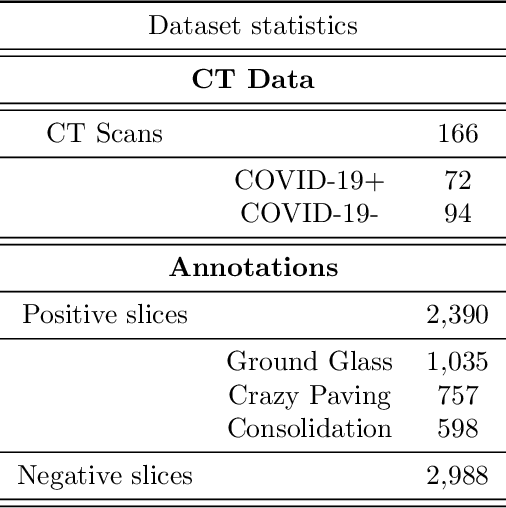
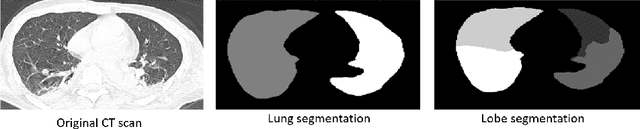

COVID-19 infection caused by SARS-CoV-2 pathogen is a catastrophic pandemic outbreak all over the world with exponential increasing of confirmed cases and, unfortunately, deaths. In this work we propose an AI-powered pipeline, based on the deep-learning paradigm, for automated COVID-19 detection and lesion categorization from CT scans. We first propose a new segmentation module aimed at identifying automatically lung parenchyma and lobes. Next, we combined such segmentation network with classification networks for COVID-19 identification and lesion categorization. We compare the obtained classification results with those obtained by three expert radiologists on a dataset consisting of 162 CT scans. Results showed a sensitivity of 90\% and a specificity of 93.5% for COVID-19 detection, outperforming those yielded by the expert radiologists, and an average lesion categorization accuracy of over 84%. Results also show that a significant role is played by prior lung and lobe segmentation that allowed us to enhance performance by over 20 percent points. The interpretation of the trained AI models, moreover, reveals that the most significant areas for supporting the decision on COVID-19 identification are consistent with the lesions clinically associated to the virus, i.e., crazy paving, consolidation and ground glass. This means that the artificial models are able to discriminate a positive patient from a negative one (both controls and patients with interstitial pneumonia tested negative to COVID) by evaluating the presence of those lesions into CT scans. Finally, the AI models are integrated into a user-friendly GUI to support AI explainability for radiologists, which is publicly available at http://perceivelab.com/covid-ai.
Correct block-design experiments mitigate temporal correlation bias in EEG classification
Nov 25, 2020It is argued in [1] that [2] was able to classify EEG responses to visual stimuli solely because of the temporal correlation that exists in all EEG data and the use of a block design. We here show that the main claim in [1] is drastically overstated and their other analyses are seriously flawed by wrong methodological choices. To validate our counter-claims, we evaluate the performance of state-of-the-art methods on the dataset in [2] reaching about 50% classification accuracy over 40 classes, lower than in [2], but still significant. We then investigate the influence of EEG temporal correlation on classification accuracy by testing the same models in two additional experimental settings: one that replicates [1]'s rapid-design experiment, and another one that examines the data between blocks while subjects are shown a blank screen. In both cases, classification accuracy is at or near chance, in contrast to what [1] reports, indicating a negligible contribution of temporal correlation to classification accuracy. We, instead, are able to replicate the results in [1] only when intentionally contaminating our data by inducing a temporal correlation. This suggests that what Li et al. [1] demonstrate is that their data are strongly contaminated by temporal correlation and low signal-to-noise ratio. We argue that the reason why Li et al. [1] observe such high correlation in EEG data is their unconventional experimental design and settings that violate the basic cognitive neuroscience design recommendations, first and foremost the one of limiting the experiments' duration, as instead done in [2]. Our analyses in this paper refute the claims of the "perils and pitfalls of block-design" in [1]. Finally, we conclude the paper by examining a number of other oversimplistic statements, inconsistencies, misinterpretation of machine learning concepts, speculations and misleading claims in [1].
Decoding Brain Representations by Multimodal Learning of Neural Activity and Visual Features
Oct 25, 2018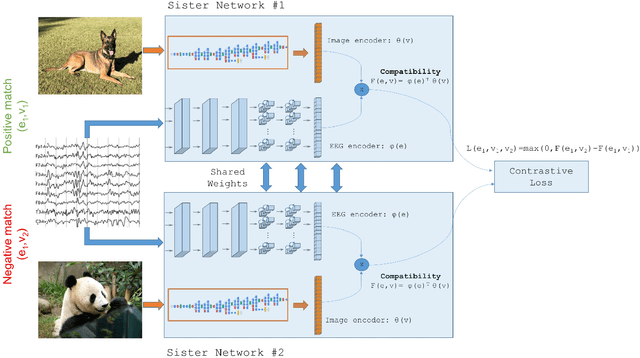
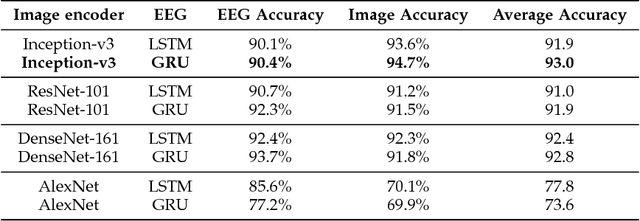
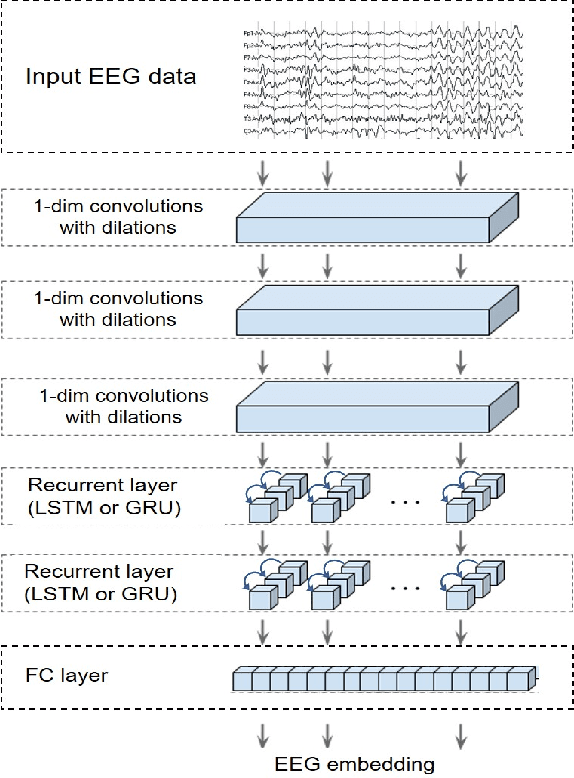
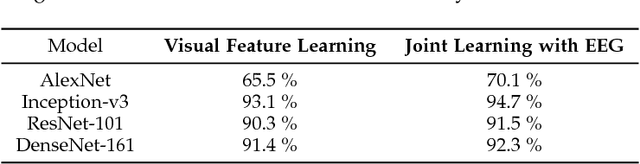
This paper tackles the problem of learning brain-visual representations for understanding and neural processes behind human visual perception, with a view towards replicating these processes into machines. The core idea is to learn plausible representations through the combined use of human neural activity evoked by natural images as a supervision mechanism for deep learning models. To accomplish this, we propose a multimodal approach that uses two different deep encoders, one for images and one for EEGs, trained in a siamese configuration for learning a joint manifold that maximizes a compatibility measure between visual features and brain representation. The learned manifold is then used to perform image classification and saliency detection as well as to shed light on the possible representations generated by the human brain when perceiving the visual world. Performance analysis shows that neural signals can be used to effectively supervise the training of deep learning models, as demonstrated by the achieved performance in both image classification and saliency detection. Furthermore, the learned brain-visual manifold is consistent with cognitive neuroscience literature about visual perception and, most importantly, highlights new associations between brain areas, image patches and computational kernels. In particular, we are able to approximate brain responses to visual stimuli by training an artificial model with image features correlated to neural activity.
Deep Learning Human Mind for Automated Visual Classification
Sep 01, 2016

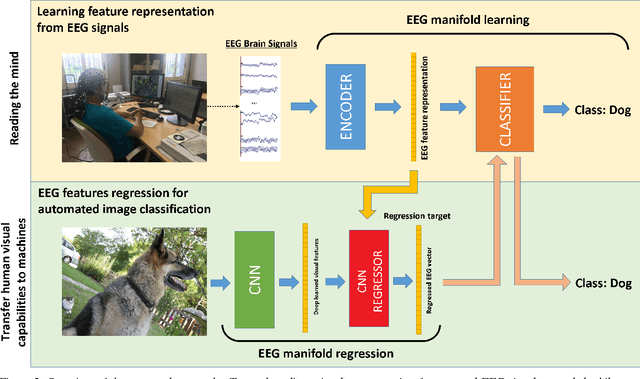
What if we could effectively read the mind and transfer human visual capabilities to computer vision methods? In this paper, we aim at addressing this question by developing the first visual object classifier driven by human brain signals. In particular, we employ EEG data evoked by visual object stimuli combined with Recurrent Neural Networks (RNN) to learn a discriminative brain activity manifold of visual categories. Afterwards, we train a Convolutional Neural Network (CNN)-based regressor to project images onto the learned manifold, thus effectively allowing machines to employ human brain-based features for automated visual classification. We use a 32-channel EEG to record brain activity of seven subjects while looking at images of 40 ImageNet object classes. The proposed RNN based approach for discriminating object classes using brain signals reaches an average accuracy of about 40%, which outperforms existing methods attempting to learn EEG visual object representations. As for automated object categorization, our human brain-driven approach obtains competitive performance, comparable to those achieved by powerful CNN models, both on ImageNet and CalTech 101, thus demonstrating its classification and generalization capabilities. This gives us a real hope that, indeed, human mind can be read and transferred to machines.