 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoding Brain Representations by Multimodal Learning of Neural Activity and Visual Features
Paper and Code
Oct 25, 2018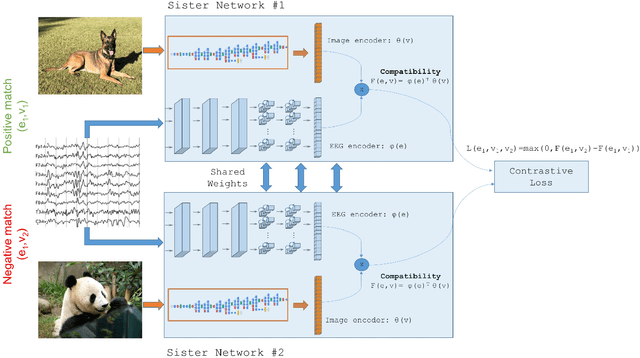
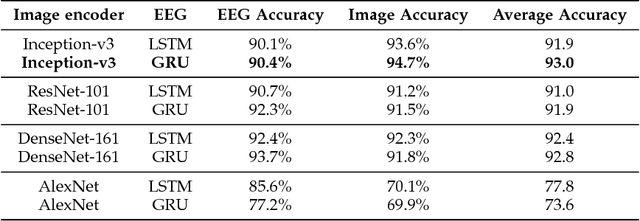
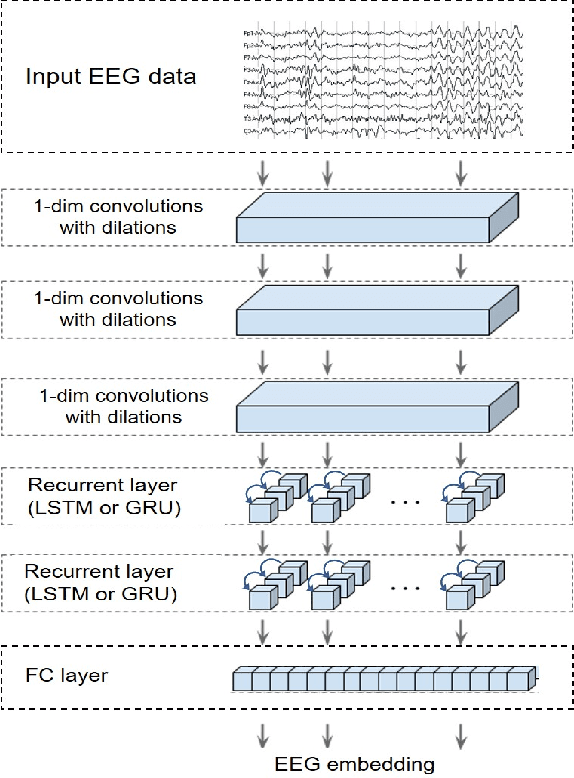
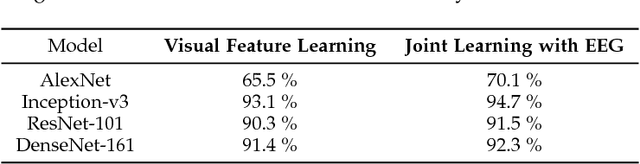
This paper tackles the problem of learning brain-visual representations for understanding and neural processes behind human visual perception, with a view towards replicating these processes into machines. The core idea is to learn plausible representations through the combined use of human neural activity evoked by natural images as a supervision mechanism for deep learning models. To accomplish this, we propose a multimodal approach that uses two different deep encoders, one for images and one for EEGs, trained in a siamese configuration for learning a joint manifold that maximizes a compatibility measure between visual features and brain representation. The learned manifold is then used to perform image classification and saliency detection as well as to shed light on the possible representations generated by the human brain when perceiving the visual world. Performance analysis shows that neural signals can be used to effectively supervise the training of deep learning models, as demonstrated by the achieved performance in both image classification and saliency detection. Furthermore, the learned brain-visual manifold is consistent with cognitive neuroscience literature about visual perception and, most importantly, highlights new associations between brain areas, image patches and computational kernels. In particular, we are able to approximate brain responses to visual stimuli by training an artificial model with image features correlated to neural activity.