 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRouting without Forgetting
Mar 10, 2026Continual learning in transformers is commonly addressed through parameter-efficient adaptation: prompts, adapters, or LoRA modules are specialized per task while the backbone remains frozen. Although effective in controlled multi-epoch settings, these approaches rely on gradual gradient-based specialization and struggle in Online Continual Learning (OCL), where data arrive as a non-stationary stream and each sample may be observed only once. We recast continual learning in transformers as a routing problem: under strict online constraints, the model must dynamically select the appropriate representational subspace for each input without explicit task identifiers or repeated optimization. We thus introduce Routing without Forgetting (RwF), a transformer architecture augmented with energy-based associative retrieval layers inspired by Modern Hopfield Networks. Instead of storing or merging task-specific prompts, RwF generates dynamic prompts through single-step associative retrieval over the transformer token embeddings at each layer. Retrieval corresponds to the closed-form minimization of a strictly convex free-energy functional, enabling input-conditioned routing within each forward pass, independently of iterative gradient refinement. Across challenging class-incremental benchmarks, RwF improves over existing prompt-based methods. On Split-ImageNet-R and Split-ImageNet-S, RwF outperforms prior prompt-based approaches by a large margin, even in few-shot learning regimes. These results indicate that embedding energy-based associative routing directly within the transformer backbone provides a principled and effective foundation for OCL.
UNBOX: Unveiling Black-box visual models with Natural-language
Mar 09, 2026Ensuring trustworthiness in open-world visual recognition requires models that are interpretable, fair, and robust to distribution shifts. Yet modern vision systems are increasingly deployed as proprietary black-box APIs, exposing only output probabilities and hiding architecture, parameters, gradients, and training data. This opacity prevents meaningful auditing, bias detection, and failure analysis. Existing explanation methods assume white- or gray-box access or knowledge of the training distribution, making them unusable in these real-world settings. We introduce UNBOX, a framework for class-wise model dissection under fully data-free, gradient-free, and backpropagation-free constraints. UNBOX leverages Large Language Models and text-to-image diffusion models to recast activation maximization as a purely semantic search driven by output probabilities. The method produces human-interpretable text descriptors that maximally activate each class, revealing the concepts a model has implicitly learned, the training distribution it reflects, and potential sources of bias. We evaluate UNBOX on ImageNet-1K, Waterbirds, and CelebA through semantic fidelity tests, visual-feature correlation analyses and slice-discovery auditing. Despite operating under the strictest black-box constraints, UNBOX performs competitively with state-of-the-art white-box interpretability methods. This demonstrates that meaningful insight into a model's internal reasoning can be recovered without any internal access, enabling more trustworthy and accountable visual recognition systems.
Dream2Learn: Structured Generative Dreaming for Continual Learning
Mar 02, 2026Continual learning requires balancing plasticity and stability while mitigating catastrophic forgetting. Inspired by human dreaming as a mechanism for internal simulation and knowledge restructuring, we introduce Dream2Learn (D2L), a framework in which a model autonomously generates structured synthetic experiences from its own internal representations and uses them for self-improvement. Rather than reconstructing past data as in generative replay, D2L enables a classifier to create novel, semantically distinct dreamed classes that are coherent with its learned knowledge yet do not correspond to previously observed data. These dreamed samples are produced by conditioning a frozen diffusion model through soft prompt optimization driven by the classifier itself. The generated data are not used to replace memory, but to expand and reorganize the representation space, effectively allowing the network to self-train on internally synthesized concepts. By integrating dreamed classes into continual training, D2L proactively structures latent features to support forward knowledge transfer and adaptation to future tasks. This prospective self-training mechanism mirrors the role of sleep in consolidating and reorganizing memory, turning internal simulations into a tool for improved generalization. Experiments on Mini-ImageNet, FG-ImageNet, and ImageNet-R demonstrate that D2L consistently outperforms strong rehearsal-based baselines and achieves positive forward transfer, confirming its ability to enhance adaptability through internally generated training signals.
Zero-Shot Decentralized Federated Learning
Sep 30, 2025CLIP has revolutionized zero-shot learning by enabling task generalization without fine-tuning. While prompting techniques like CoOp and CoCoOp enhance CLIP's adaptability, their effectiveness in Federated Learning (FL) remains an open challenge. Existing federated prompt learning approaches, such as FedCoOp and FedTPG, improve performance but face generalization issues, high communication costs, and reliance on a central server, limiting scalability and privacy. We propose Zero-shot Decentralized Federated Learning (ZeroDFL), a fully decentralized framework that enables zero-shot adaptation across distributed clients without a central coordinator. ZeroDFL employs an iterative prompt-sharing mechanism, allowing clients to optimize and exchange textual prompts to enhance generalization while drastically reducing communication overhead. We validate ZeroDFL on nine diverse image classification datasets, demonstrating that it consistently outperforms--or remains on par with--state-of-the-art federated prompt learning methods. More importantly, ZeroDFL achieves this performance in a fully decentralized setting while reducing communication overhead by 118x compared to FedTPG. These results highlight that our approach not only enhances generalization in federated zero-shot learning but also improves scalability, efficiency, and privacy preservation--paving the way for decentralized adaptation of large vision-language models in real-world applications.
Cyst-X: AI-Powered Pancreatic Cancer Risk Prediction from Multicenter MRI in Centralized and Federated Learning
Jul 29, 2025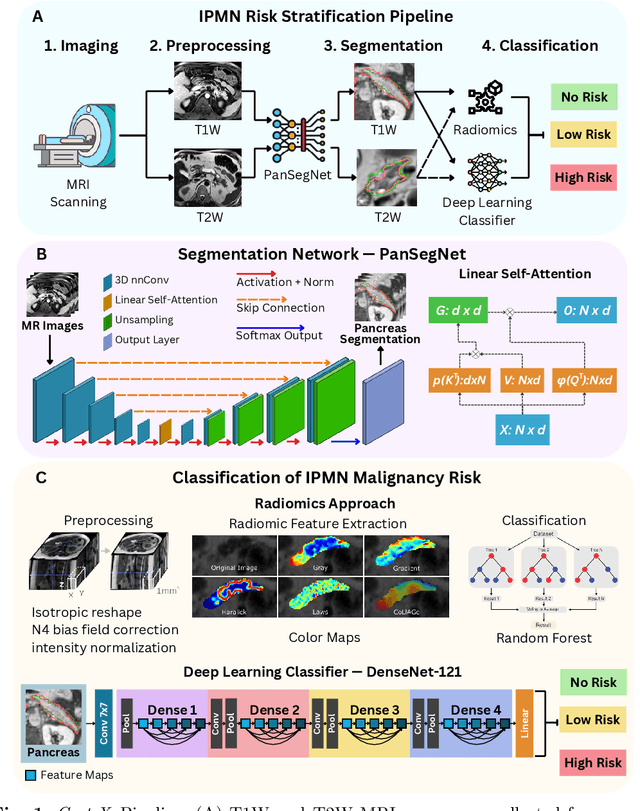

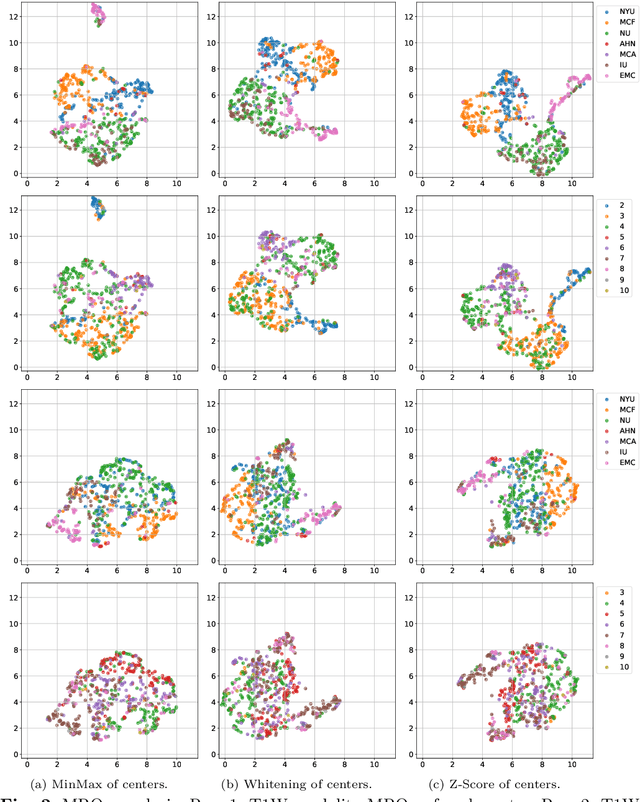
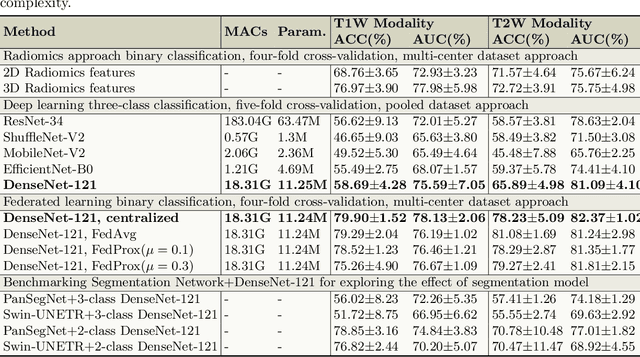
Pancreatic cancer is projected to become the second-deadliest malignancy in Western countries by 2030, highlighting the urgent need for better early detection. Intraductal papillary mucinous neoplasms (IPMNs), key precursors to pancreatic cancer, are challenging to assess with current guidelines, often leading to unnecessary surgeries or missed malignancies. We present Cyst-X, an AI framework that predicts IPMN malignancy using multicenter MRI data, leveraging MRI's superior soft tissue contrast over CT. Trained on 723 T1- and 738 T2-weighted scans from 764 patients across seven institutions, our models (AUC=0.82) significantly outperform both Kyoto guidelines (AUC=0.75) and expert radiologists. The AI-derived imaging features align with known clinical markers and offer biologically meaningful insights. We also demonstrate strong performance in a federated learning setting, enabling collaborative training without sharing patient data. To promote privacy-preserving AI development and improve IPMN risk stratification, the Cyst-X dataset is released as the first large-scale, multi-center pancreatic cysts MRI dataset.
QuantFormer: Learning to Quantize for Neural Activity Forecasting in Mouse Visual Cortex
Dec 10, 2024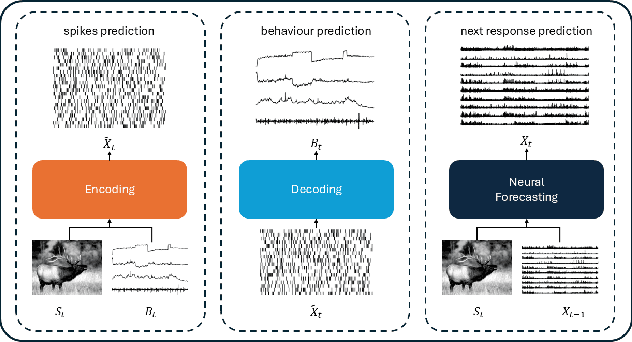
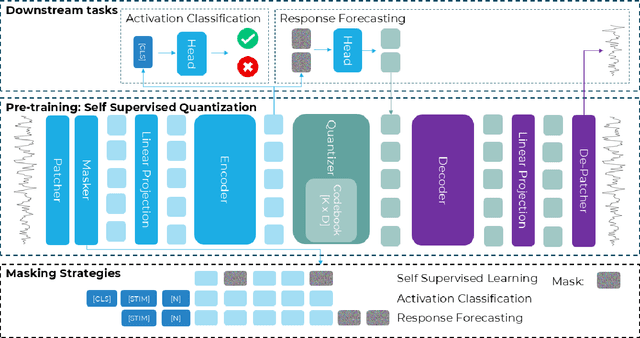
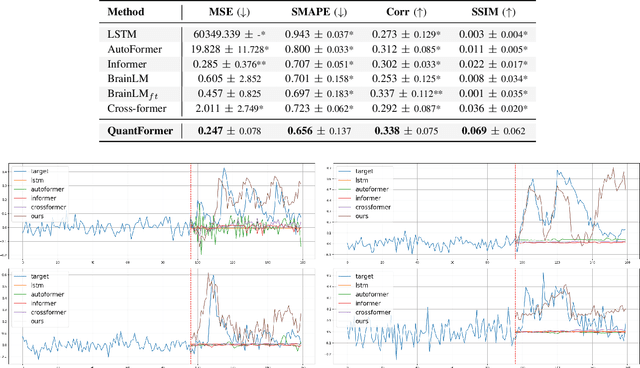
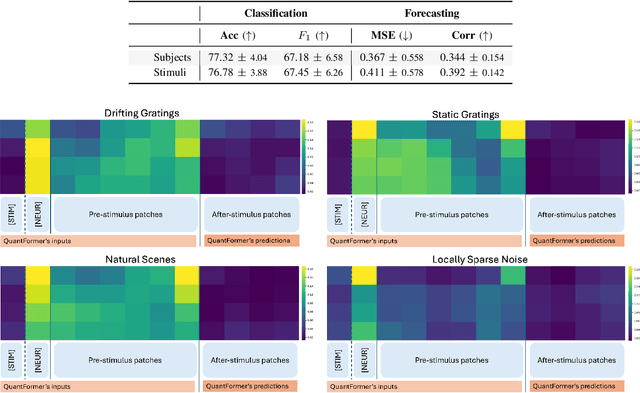
Understanding complex animal behaviors hinges on deciphering the neural activity patterns within brain circuits, making the ability to forecast neural activity crucial for developing predictive models of brain dynamics. This capability holds immense value for neuroscience, particularly in applications such as real-time optogenetic interventions. While traditional encoding and decoding methods have been used to map external variables to neural activity and vice versa, they focus on interpreting past data. In contrast, neural forecasting aims to predict future neural activity, presenting a unique and challenging task due to the spatiotemporal sparsity and complex dependencies of neural signals. Existing transformer-based forecasting methods, while effective in many domains, struggle to capture the distinctiveness of neural signals characterized by spatiotemporal sparsity and intricate dependencies. To address this challenge, we here introduce QuantFormer, a transformer-based model specifically designed for forecasting neural activity from two-photon calcium imaging data. Unlike conventional regression-based approaches, QuantFormerreframes the forecasting task as a classification problem via dynamic signal quantization, enabling more effective learning of sparse neural activation patterns. Additionally, QuantFormer tackles the challenge of analyzing multivariate signals from an arbitrary number of neurons by incorporating neuron-specific tokens, allowing scalability across diverse neuronal populations. Trained with unsupervised quantization on the Allen dataset, QuantFormer sets a new benchmark in forecasting mouse visual cortex activity. It demonstrates robust performance and generalization across various stimuli and individuals, paving the way for a foundational model in neural signal prediction.
Self-supervised learning for radio-astronomy source classification: a benchmark
Nov 22, 2024The upcoming Square Kilometer Array (SKA) telescope marks a significant step forward in radio astronomy, presenting new opportunities and challenges for data analysis. Traditional visual models pretrained on optical photography images may not perform optimally on radio interferometry images, which have distinct visual characteristics. Self-Supervised Learning (SSL) offers a promising approach to address this issue, leveraging the abundant unlabeled data in radio astronomy to train neural networks that learn useful representations from radio images. This study explores the application of SSL to radio astronomy, comparing the performance of SSL-trained models with that of traditional models pretrained on natural images, evaluating the importance of data curation for SSL, and assessing the potential benefits of self-supervision to different domain-specific radio astronomy datasets. Our results indicate that, SSL-trained models achieve significant improvements over the baseline in several downstream tasks, especially in the linear evaluation setting; when the entire backbone is fine-tuned, the benefits of SSL are less evident but still outperform pretraining. These findings suggest that SSL can play a valuable role in efficiently enhancing the analysis of radio astronomical data. The trained models and code is available at: \url{https://github.com/dr4thmos/solo-learn-radio}
Evidential Federated Learning for Skin Lesion Image Classification
Nov 15, 2024We introduce FedEvPrompt, a federated learning approach that integrates principles of evidential deep learning, prompt tuning, and knowledge distillation for distributed skin lesion classification. FedEvPrompt leverages two sets of prompts: b-prompts (for low-level basic visual knowledge) and t-prompts (for task-specific knowledge) prepended to frozen pre-trained Vision Transformer (ViT) models trained in an evidential learning framework to maximize class evidences. Crucially, knowledge sharing across federation clients is achieved only through knowledge distillation on attention maps generated by the local ViT models, ensuring enhanced privacy preservation compared to traditional parameter or synthetic image sharing methodologies. FedEvPrompt is optimized within a round-based learning paradigm, where each round involves training local models followed by attention maps sharing with all federation clients. Experimental validation conducted in a real distributed setting, on the ISIC2019 dataset, demonstrates the superior performance of FedEvPrompt against baseline federated learning algorithms and knowledge distillation methods, without sharing model parameters. In conclusion, FedEvPrompt offers a promising approach for federated learning, effectively addressing challenges such as data heterogeneity, imbalance, privacy preservation, and knowledge sharing.
FedRewind: Rewinding Continual Model Exchange for Decentralized Federated Learning
Nov 14, 2024



In this paper, we present FedRewind, a novel approach to decentralized federated learning that leverages model exchange among nodes to address the issue of data distribution shift. Drawing inspiration from continual learning (CL) principles and cognitive neuroscience theories for memory retention, FedRewind implements a decentralized routing mechanism where nodes send/receive models to/from other nodes in the federation to address spatial distribution challenges inherent in distributed learning (FL). During local training, federation nodes periodically send their models back (i.e., rewind) to the nodes they received them from for a limited number of iterations. This strategy reduces the distribution shift between nodes' data, leading to enhanced learning and generalization performance. We evaluate our method on multiple benchmarks, demonstrating its superiority over standard decentralized federated learning methods and those enforcing specific routing schemes within the federation. Furthermore, the combination of federated and continual learning concepts enables our method to tackle the more challenging federated continual learning task, with data shifts over both space and time, surpassing existing baselines.
IPMN Risk Assessment under Federated Learning Paradigm
Nov 08, 2024



Accurate classification of Intraductal Papillary Mucinous Neoplasms (IPMN) is essential for identifying high-risk cases that require timely intervention. In this study, we develop a federated learning framework for multi-center IPMN classification utilizing a comprehensive pancreas MRI dataset. This dataset includes 653 T1-weighted and 656 T2-weighted MRI images, accompanied by corresponding IPMN risk scores from 7 leading medical institutions, making it the largest and most diverse dataset for IPMN classification to date. We assess the performance of DenseNet-121 in both centralized and federated settings for training on distributed data. Our results demonstrate that the federated learning approach achieves high classification accuracy comparable to centralized learning while ensuring data privacy across institutions. This work marks a significant advancement in collaborative IPMN classification, facilitating secure and high-accuracy model training across multiple centers.