 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantFormer: Learning to Quantize for Neural Activity Forecasting in Mouse Visual Cortex
Dec 10, 2024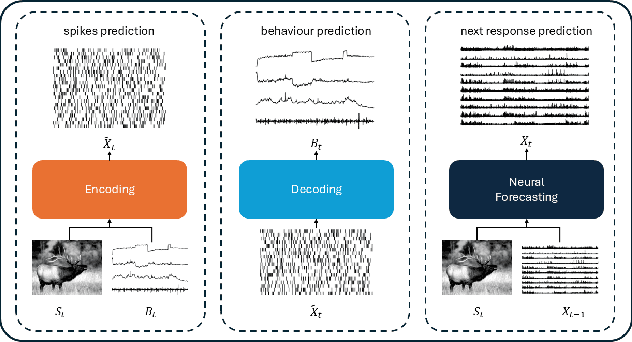
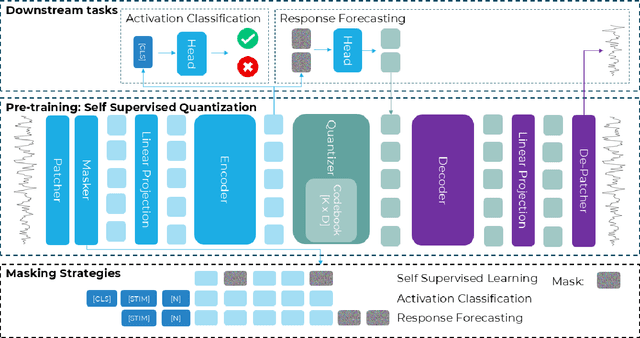
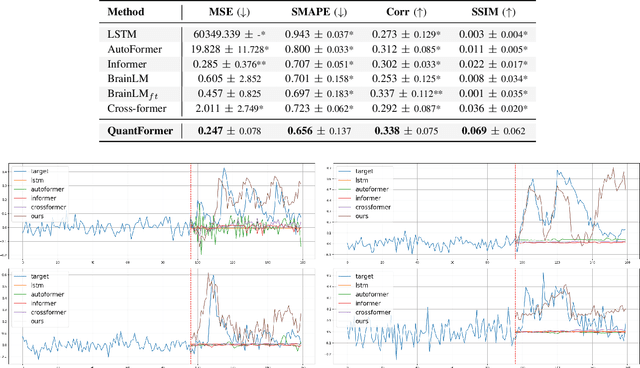
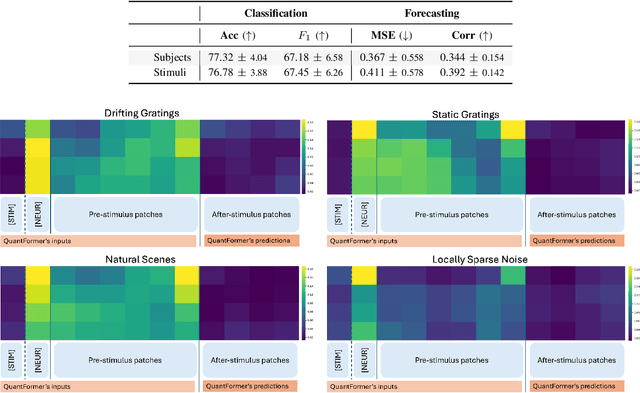
Understanding complex animal behaviors hinges on deciphering the neural activity patterns within brain circuits, making the ability to forecast neural activity crucial for developing predictive models of brain dynamics. This capability holds immense value for neuroscience, particularly in applications such as real-time optogenetic interventions. While traditional encoding and decoding methods have been used to map external variables to neural activity and vice versa, they focus on interpreting past data. In contrast, neural forecasting aims to predict future neural activity, presenting a unique and challenging task due to the spatiotemporal sparsity and complex dependencies of neural signals. Existing transformer-based forecasting methods, while effective in many domains, struggle to capture the distinctiveness of neural signals characterized by spatiotemporal sparsity and intricate dependencies. To address this challenge, we here introduce QuantFormer, a transformer-based model specifically designed for forecasting neural activity from two-photon calcium imaging data. Unlike conventional regression-based approaches, QuantFormerreframes the forecasting task as a classification problem via dynamic signal quantization, enabling more effective learning of sparse neural activation patterns. Additionally, QuantFormer tackles the challenge of analyzing multivariate signals from an arbitrary number of neurons by incorporating neuron-specific tokens, allowing scalability across diverse neuronal populations. Trained with unsupervised quantization on the Allen dataset, QuantFormer sets a new benchmark in forecasting mouse visual cortex activity. It demonstrates robust performance and generalization across various stimuli and individuals, paving the way for a foundational model in neural signal prediction.
Back to Supervision: Boosting Word Boundary Detection through Frame Classification
Nov 15, 2024

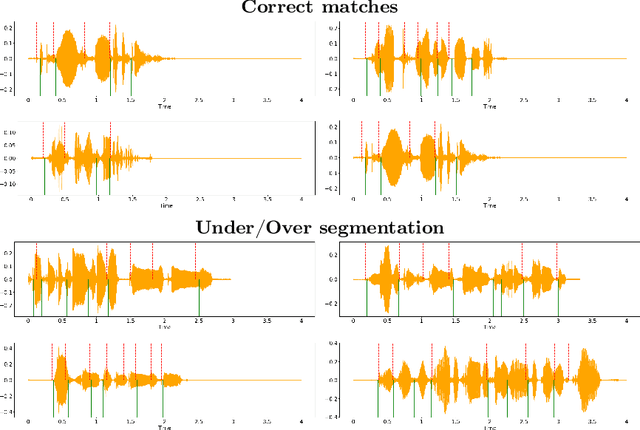

Speech segmentation at both word and phoneme levels is crucial for various speech processing tasks. It significantly aids in extracting meaningful units from an utterance, thus enabling the generation of discrete elements. In this work we propose a model-agnostic framework to perform word boundary detection in a supervised manner also employing a labels augmentation technique and an output-frame selection strategy. We trained and tested on the Buckeye dataset and only tested on TIMIT one, using state-of-the-art encoder models, including pre-trained solutions (Wav2Vec 2.0 and HuBERT), as well as convolutional and convolutional recurrent networks. Our method, with the HuBERT encoder, surpasses the performance of other state-of-the-art architectures, whether trained in supervised or self-supervised settings on the same datasets. Specifically, we achieved F-values of 0.8427 on the Buckeye dataset and 0.7436 on the TIMIT dataset, along with R-values of 0.8489 and 0.7807, respectively. These results establish a new state-of-the-art for both datasets. Beyond the immediate task, our approach offers a robust and efficient preprocessing method for future research in audio tokenization.