 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgekooplearn: A Scikit-Learn Compatible Library of Algorithms for Evolution Operator Learning
Dec 24, 2025



kooplearn is a machine-learning library that implements linear, kernel, and deep-learning estimators of dynamical operators and their spectral decompositions. kooplearn can model both discrete-time evolution operators (Koopman/Transfer) and continuous-time infinitesimal generators. By learning these operators, users can analyze dynamical systems via spectral methods, derive data-driven reduced-order models, and forecast future states and observables. kooplearn's interface is compliant with the scikit-learn API, facilitating its integration into existing machine learning and data science workflows. Additionally, kooplearn includes curated benchmark datasets to support experimentation, reproducibility, and the fair comparison of learning algorithms. The software is available at https://github.com/Machine-Learning-Dynamical-Systems/kooplearn.
Self-Supervised Evolution Operator Learning for High-Dimensional Dynamical Systems
May 24, 2025
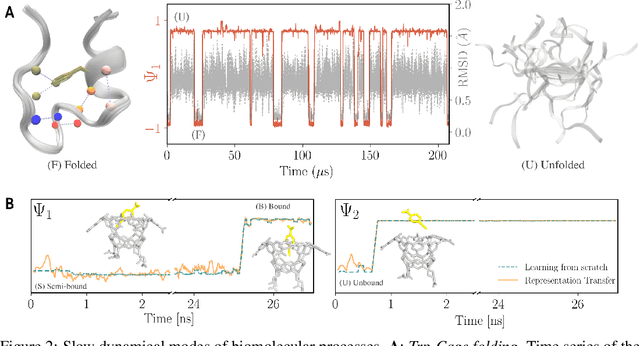
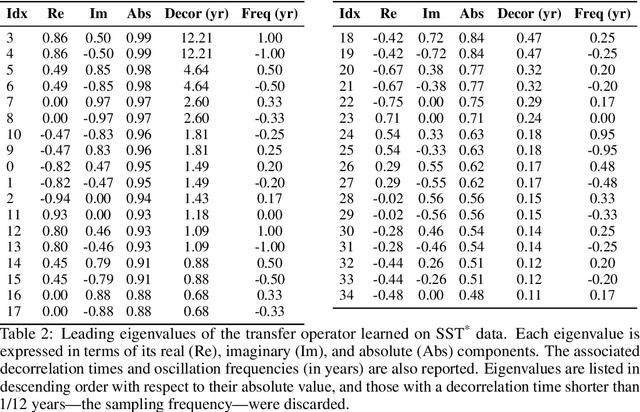
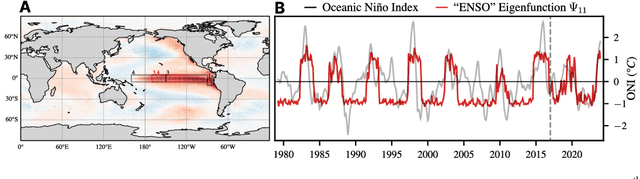
We introduce an encoder-only approach to learn the evolution operators of large-scale non-linear dynamical systems, such as those describing complex natural phenomena. Evolution operators are particularly well-suited for analyzing systems that exhibit complex spatio-temporal patterns and have become a key analytical tool across various scientific communities. As terabyte-scale weather datasets and simulation tools capable of running millions of molecular dynamics steps per day are becoming commodities, our approach provides an effective tool to make sense of them from a data-driven perspective. The core of it lies in a remarkable connection between self-supervised representation learning methods and the recently established learning theory of evolution operators. To show the usefulness of the proposed method, we test it across multiple scientific domains: explaining the folding dynamics of small proteins, the binding process of drug-like molecules in host sites, and autonomously finding patterns in climate data. Code and data to reproduce the experiments are made available open source.
QuantFormer: Learning to Quantize for Neural Activity Forecasting in Mouse Visual Cortex
Dec 10, 2024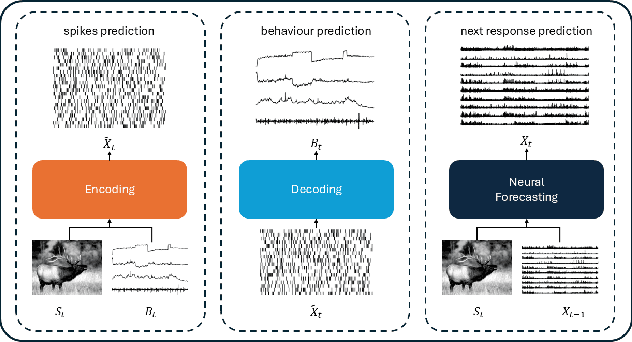
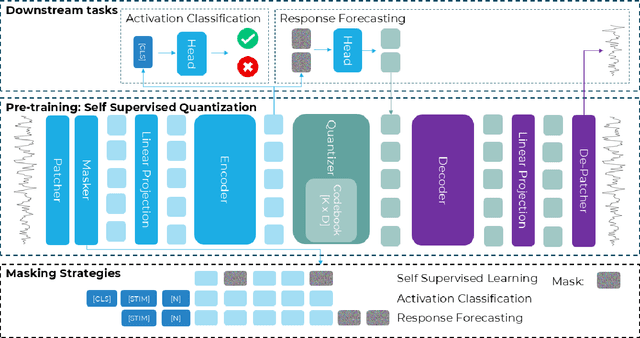
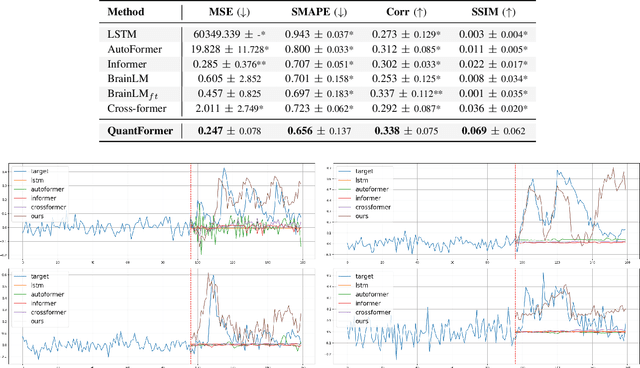
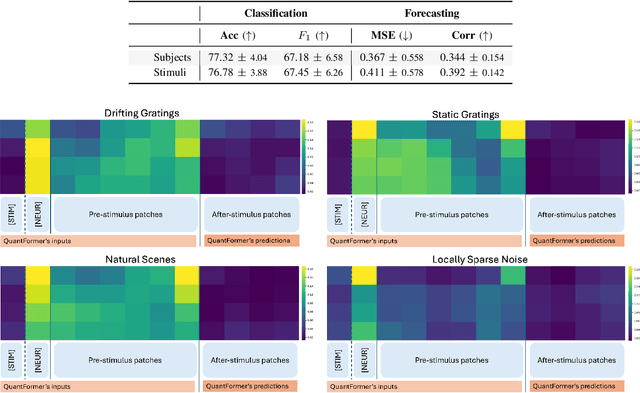
Understanding complex animal behaviors hinges on deciphering the neural activity patterns within brain circuits, making the ability to forecast neural activity crucial for developing predictive models of brain dynamics. This capability holds immense value for neuroscience, particularly in applications such as real-time optogenetic interventions. While traditional encoding and decoding methods have been used to map external variables to neural activity and vice versa, they focus on interpreting past data. In contrast, neural forecasting aims to predict future neural activity, presenting a unique and challenging task due to the spatiotemporal sparsity and complex dependencies of neural signals. Existing transformer-based forecasting methods, while effective in many domains, struggle to capture the distinctiveness of neural signals characterized by spatiotemporal sparsity and intricate dependencies. To address this challenge, we here introduce QuantFormer, a transformer-based model specifically designed for forecasting neural activity from two-photon calcium imaging data. Unlike conventional regression-based approaches, QuantFormerreframes the forecasting task as a classification problem via dynamic signal quantization, enabling more effective learning of sparse neural activation patterns. Additionally, QuantFormer tackles the challenge of analyzing multivariate signals from an arbitrary number of neurons by incorporating neuron-specific tokens, allowing scalability across diverse neuronal populations. Trained with unsupervised quantization on the Allen dataset, QuantFormer sets a new benchmark in forecasting mouse visual cortex activity. It demonstrates robust performance and generalization across various stimuli and individuals, paving the way for a foundational model in neural signal prediction.
Neural Conditional Probability for Inference
Jul 01, 2024



We introduce NCP (Neural Conditional Probability), a novel operator-theoretic approach for learning conditional distributions with a particular focus on inference tasks. NCP can be used to build conditional confidence regions and extract important statistics like conditional quantiles, mean, and covariance. It offers streamlined learning through a single unconditional training phase, facilitating efficient inference without the need for retraining even when conditioning changes. By tapping into the powerful approximation capabilities of neural networks, our method efficiently handles a wide variety of complex probability distributions, effectively dealing with nonlinear relationships between input and output variables. Theoretical guarantees ensure both optimization consistency and statistical accuracy of the NCP method. Our experiments show that our approach matches or beats leading methods using a simple Multi-Layer Perceptron (MLP) with two hidden layers and GELU activations. This demonstrates that a minimalistic architecture with a theoretically grounded loss function can achieve competitive results without sacrificing performance, even in the face of more complex architectures.
A randomized algorithm to solve reduced rank operator regression
Dec 28, 2023We present and analyze an algorithm designed for addressing vector-valued regression problems involving possibly infinite-dimensional input and output spaces. The algorithm is a randomized adaptation of reduced rank regression, a technique to optimally learn a low-rank vector-valued function (i.e. an operator) between sampled data via regularized empirical risk minimization with rank constraints. We propose Gaussian sketching techniques both for the primal and dual optimization objectives, yielding Randomized Reduced Rank Regression (R4) estimators that are efficient and accurate. For each of our R4 algorithms we prove that the resulting regularized empirical risk is, in expectation w.r.t. randomness of a sketch, arbitrarily close to the optimal value when hyper-parameteres are properly tuned. Numerical expreriments illustrate the tightness of our bounds and show advantages in two distinct scenarios: (i) solving a vector-valued regression problem using synthetic and large-scale neuroscience datasets, and (ii) regressing the Koopman operator of a nonlinear stochastic dynamical system.