 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBack to Supervision: Boosting Word Boundary Detection through Frame Classification
Nov 15, 2024

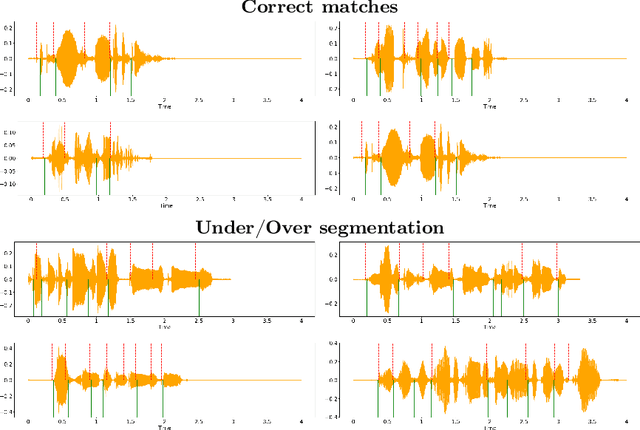

Speech segmentation at both word and phoneme levels is crucial for various speech processing tasks. It significantly aids in extracting meaningful units from an utterance, thus enabling the generation of discrete elements. In this work we propose a model-agnostic framework to perform word boundary detection in a supervised manner also employing a labels augmentation technique and an output-frame selection strategy. We trained and tested on the Buckeye dataset and only tested on TIMIT one, using state-of-the-art encoder models, including pre-trained solutions (Wav2Vec 2.0 and HuBERT), as well as convolutional and convolutional recurrent networks. Our method, with the HuBERT encoder, surpasses the performance of other state-of-the-art architectures, whether trained in supervised or self-supervised settings on the same datasets. Specifically, we achieved F-values of 0.8427 on the Buckeye dataset and 0.7436 on the TIMIT dataset, along with R-values of 0.8489 and 0.7807, respectively. These results establish a new state-of-the-art for both datasets. Beyond the immediate task, our approach offers a robust and efficient preprocessing method for future research in audio tokenization.