 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRewardFlow: Generate Images by Optimizing What You Reward
Apr 09, 2026We introduce RewardFlow, an inversion-free framework that steers pretrained diffusion and flow-matching models at inference time through multi-reward Langevin dynamics. RewardFlow unifies complementary differentiable rewards for semantic alignment, perceptual fidelity, localized grounding, object consistency, and human preference, and further introduces a differentiable VQA-based reward that provides fine-grained semantic supervision through language-vision reasoning. To coordinate these heterogeneous objectives, we design a prompt-aware adaptive policy that extracts semantic primitives from the instruction, infers edit intent, and dynamically modulates reward weights and step sizes throughout sampling. Across several image editing and compositional generation benchmarks, RewardFlow delivers state-of-the-art edit fidelity and compositional alignment.
Best of Both Worlds: Multimodal Reasoning and Generation via Unified Discrete Flow Matching
Feb 12, 2026We propose UniDFlow, a unified discrete flow-matching framework for multimodal understanding, generation, and editing. It decouples understanding and generation via task-specific low-rank adapters, avoiding objective interference and representation entanglement, while a novel reference-based multimodal preference alignment optimizes relative outcomes under identical conditioning, improving faithfulness and controllability without large-scale retraining. UniDFlpw achieves SOTA performance across eight benchmarks and exhibits strong zero-shot generalization to tasks including inpainting, in-context image generation, reference-based editing, and compositional generation, despite no explicit task-specific training.
PyraTok: Language-Aligned Pyramidal Tokenizer for Video Understanding and Generation
Jan 22, 2026Discrete video VAEs underpin modern text-to-video generation and video understanding systems, yet existing tokenizers typically learn visual codebooks at a single scale with limited vocabularies and shallow language supervision, leading to poor cross-modal alignment and zero-shot transfer. We introduce PyraTok, a language-aligned pyramidal tokenizer that learns semantically structured discrete latents across multiple spatiotemporal resolutions. PyraTok builds on a pretrained video VAE and a novel Language aligned Pyramidal Quantization (LaPQ) module that discretizes encoder features at several depths using a shared large binary codebook, yielding compact yet expressive video token sequences. To tightly couple visual tokens with language, PyraTok jointly optimizes multi-scale text-guided quantization and a global autoregressive objective over the token hierarchy. Across ten benchmarks, PyraTok delivers state-of-the-art (SOTA) video reconstruction, consistently improves text-to-video quality, and sets new SOTA zero-shot performance on video segmentation, temporal action localization, and video understanding, scaling robustly to up to 4K/8K resolutions.
ViCTr: Vital Consistency Transfer for Pathology Aware Image Synthesis
May 08, 2025Synthesizing medical images remains challenging due to limited annotated pathological data, modality domain gaps, and the complexity of representing diffuse pathologies such as liver cirrhosis. Existing methods often struggle to maintain anatomical fidelity while accurately modeling pathological features, frequently relying on priors derived from natural images or inefficient multi-step sampling. In this work, we introduce ViCTr (Vital Consistency Transfer), a novel two-stage framework that combines a rectified flow trajectory with a Tweedie-corrected diffusion process to achieve high-fidelity, pathology-aware image synthesis. First, we pretrain ViCTr on the ATLAS-8k dataset using Elastic Weight Consolidation (EWC) to preserve critical anatomical structures. We then fine-tune the model adversarially with Low-Rank Adaptation (LoRA) modules for precise control over pathology severity. By reformulating Tweedie's formula within a linear trajectory framework, ViCTr supports one-step sampling, reducing inference from 50 steps to just 4, without sacrificing anatomical realism. We evaluate ViCTr on BTCV (CT), AMOS (MRI), and CirrMRI600+ (cirrhosis) datasets. Results demonstrate state-of-the-art performance, achieving a Medical Frechet Inception Distance (MFID) of 17.01 for cirrhosis synthesis 28% lower than existing approaches and improving nnUNet segmentation by +3.8% mDSC when used for data augmentation. Radiologist reviews indicate that ViCTr-generated liver cirrhosis MRIs are clinically indistinguishable from real scans. To our knowledge, ViCTr is the first method to provide fine-grained, pathology-aware MRI synthesis with graded severity control, closing a critical gap in AI-driven medical imaging research.
Historic Scripts to Modern Vision: A Novel Dataset and A VLM Framework for Transliteration of Modi Script to Devanagari
Mar 17, 2025In medieval India, the Marathi language was written using the Modi script. The texts written in Modi script include extensive knowledge about medieval sciences, medicines, land records and authentic evidence about Indian history. Around 40 million documents are in poor condition and have not yet been transliterated. Furthermore, only a few experts in this domain can transliterate this script into English or Devanagari. Most of the past research predominantly focuses on individual character recognition. A system that can transliterate Modi script documents to Devanagari script is needed. We propose the MoDeTrans dataset, comprising 2,043 images of Modi script documents accompanied by their corresponding textual transliterations in Devanagari. We further introduce MoScNet (\textbf{Mo}di \textbf{Sc}ript \textbf{Net}work), a novel Vision-Language Model (VLM) framework for transliterating Modi script images into Devanagari text. MoScNet leverages Knowledge Distillation, where a student model learns from a teacher model to enhance transliteration performance. The final student model of MoScNet has better performance than the teacher model while having 163$\times$ lower parameters. Our work is the first to perform direct transliteration from the handwritten Modi script to the Devanagari script. MoScNet also shows competitive results on the optical character recognition (OCR) task.
MotionAura: Generating High-Quality and Motion Consistent Videos using Discrete Diffusion
Oct 10, 2024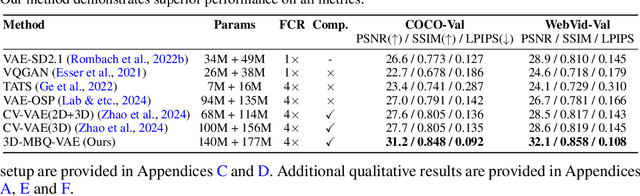
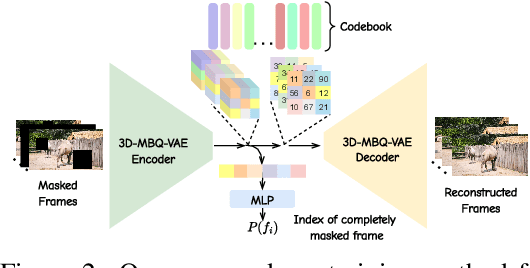
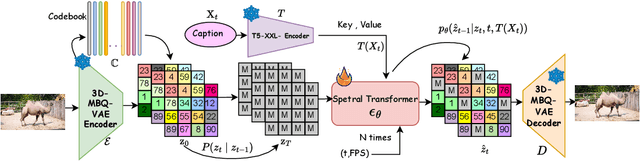
The spatio-temporal complexity of video data presents significant challenges in tasks such as compression, generation, and inpainting. We present four key contributions to address the challenges of spatiotemporal video processing. First, we introduce the 3D Mobile Inverted Vector-Quantization Variational Autoencoder (3D-MBQ-VAE), which combines Variational Autoencoders (VAEs) with masked token modeling to enhance spatiotemporal video compression. The model achieves superior temporal consistency and state-of-the-art (SOTA) reconstruction quality by employing a novel training strategy with full frame masking. Second, we present MotionAura, a text-to-video generation framework that utilizes vector-quantized diffusion models to discretize the latent space and capture complex motion dynamics, producing temporally coherent videos aligned with text prompts. Third, we propose a spectral transformer-based denoising network that processes video data in the frequency domain using the Fourier Transform. This method effectively captures global context and long-range dependencies for high-quality video generation and denoising. Lastly, we introduce a downstream task of Sketch Guided Video Inpainting. This task leverages Low-Rank Adaptation (LoRA) for parameter-efficient fine-tuning. Our models achieve SOTA performance on a range of benchmarks. Our work offers robust frameworks for spatiotemporal modeling and user-driven video content manipulation. We will release the code, datasets, and models in open-source.
Towards Synergistic Deep Learning Models for Volumetric Cirrhotic Liver Segmentation in MRIs
Aug 08, 2024



Liver cirrhosis, a leading cause of global mortality, requires precise segmentation of ROIs for effective disease monitoring and treatment planning. Existing segmentation models often fail to capture complex feature interactions and generalize across diverse datasets. To address these limitations, we propose a novel synergistic theory that leverages complementary latent spaces for enhanced feature interaction modeling. Our proposed architecture, nnSynergyNet3D integrates continuous and discrete latent spaces for 3D volumes and features auto-configured training. This approach captures both fine-grained and coarse features, enabling effective modeling of intricate feature interactions. We empirically validated nnSynergyNet3D on a private dataset of 628 high-resolution T1 abdominal MRI scans from 339 patients. Our model outperformed the baseline nnUNet3D by approximately 2%. Additionally, zero-shot testing on healthy liver CT scans from the public LiTS dataset demonstrated superior cross-modal generalization capabilities. These results highlight the potential of synergistic latent space models to improve segmentation accuracy and robustness, thereby enhancing clinical workflows by ensuring consistency across CT and MRI modalities.
D2Styler: Advancing Arbitrary Style Transfer with Discrete Diffusion Methods
Aug 07, 2024



In image processing, one of the most challenging tasks is to render an image's semantic meaning using a variety of artistic approaches. Existing techniques for arbitrary style transfer (AST) frequently experience mode-collapse, over-stylization, or under-stylization due to a disparity between the style and content images. We propose a novel framework called D$^2$Styler (Discrete Diffusion Styler) that leverages the discrete representational capability of VQ-GANs and the advantages of discrete diffusion, including stable training and avoidance of mode collapse. Our method uses Adaptive Instance Normalization (AdaIN) features as a context guide for the reverse diffusion process. This makes it easy to move features from the style image to the content image without bias. The proposed method substantially enhances the visual quality of style-transferred images, allowing the combination of content and style in a visually appealing manner. We take style images from the WikiArt dataset and content images from the COCO dataset. Experimental results demonstrate that D$^2$Styler produces high-quality style-transferred images and outperforms twelve existing methods on nearly all the metrics. The qualitative results and ablation studies provide further insights into the efficacy of our technique. The code is available at https://github.com/Onkarsus13/D2Styler.
Large-Scale Multi-Center CT and MRI Segmentation of Pancreas with Deep Learning
May 20, 2024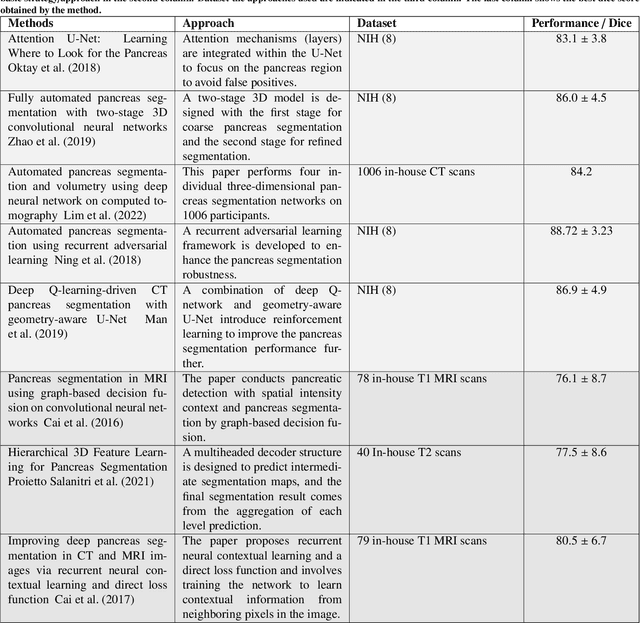
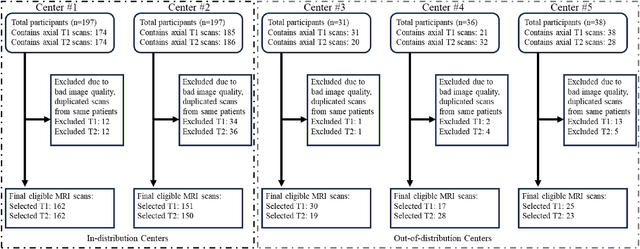
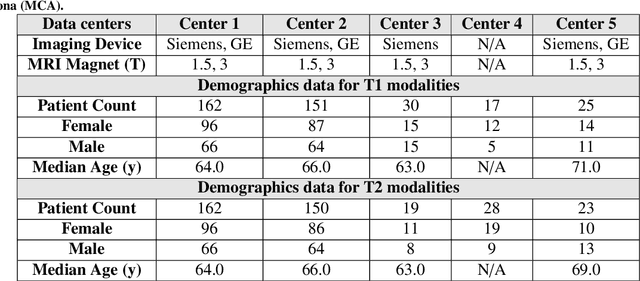
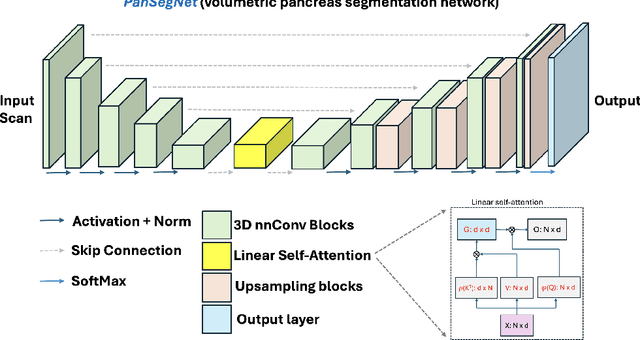
Automated volumetric segmentation of the pancreas on cross-sectional imaging is needed for diagnosis and follow-up of pancreatic diseases. While CT-based pancreatic segmentation is more established, MRI-based segmentation methods are understudied, largely due to a lack of publicly available datasets, benchmarking research efforts, and domain-specific deep learning methods. In this retrospective study, we collected a large dataset (767 scans from 499 participants) of T1-weighted (T1W) and T2-weighted (T2W) abdominal MRI series from five centers between March 2004 and November 2022. We also collected CT scans of 1,350 patients from publicly available sources for benchmarking purposes. We developed a new pancreas segmentation method, called PanSegNet, combining the strengths of nnUNet and a Transformer network with a new linear attention module enabling volumetric computation. We tested PanSegNet's accuracy in cross-modality (a total of 2,117 scans) and cross-center settings with Dice and Hausdorff distance (HD95) evaluation metrics. We used Cohen's kappa statistics for intra and inter-rater agreement evaluation and paired t-tests for volume and Dice comparisons, respectively. For segmentation accuracy, we achieved Dice coefficients of 88.3% (std: 7.2%, at case level) with CT, 85.0% (std: 7.9%) with T1W MRI, and 86.3% (std: 6.4%) with T2W MRI. There was a high correlation for pancreas volume prediction with R^2 of 0.91, 0.84, and 0.85 for CT, T1W, and T2W, respectively. We found moderate inter-observer (0.624 and 0.638 for T1W and T2W MRI, respectively) and high intra-observer agreement scores. All MRI data is made available at https://osf.io/kysnj/. Our source code is available at https://github.com/NUBagciLab/PaNSegNet.
Towards Scene-Text to Scene-Text Translation
Aug 06, 2023In this work, we study the task of ``visually" translating scene text from a source language (e.g., English) to a target language (e.g., Chinese). Visual translation involves not just the recognition and translation of scene text but also the generation of the translated image that preserves visual features of the text, such as font, size, and background. There are several challenges associated with this task, such as interpolating font to unseen characters and preserving text size and the background. To address these, we introduce VTNet, a novel conditional diffusion-based method. To train the VTNet, we create a synthetic cross-lingual dataset of 600K samples of scene text images in six popular languages, including English, Hindi, Tamil, Chinese, Bengali, and German. We evaluate the performance of VTnet through extensive experiments and comparisons to related methods. Our model also surpasses the previous state-of-the-art results on the conventional scene-text editing benchmarks. Further, we present rigorous qualitative studies to understand the strengths and shortcomings of our model. Results show that our approach generalizes well to unseen words and fonts. We firmly believe our work can benefit real-world applications, such as text translation using a phone camera and translating educational materials. Code and data will be made publicly available.