 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiscale Physics-Informed Neural Network for Complex Fluid Flows with Long-Range Dependencies
Apr 07, 2026Fluid flows are governed by the nonlinear Navier-Stokes equations, which can manifest multiscale dynamics even from predictable initial conditions. Predicting such phenomena remains a formidable challenge in scientific machine learning, particularly regarding convergence speed, data requirements, and solution accuracy. In complex fluid flows, these challenges are exacerbated by long-range spatial dependencies arising from distant boundary conditions, which typically necessitate extensive supervision data to achieve acceptable results. We propose the Domain-Decomposed and Shifted Physics-Informed Neural Network (DDS-PINN), a framework designed to resolve such multiscale interactions with minimal supervision. By utilizing localized networks with a unified global loss, DDS-PINN captures global dependencies while maintaining local precision. The robustness of the approach is demonstrated across a suite of benchmarks, including a multiscale linear differential equation, the nonlinear Burgers' equation, and data-free Navier-Stokes simulations of flat-plate boundary layers. Finally, DDS-PINN is applied to the computationally challenging backward-facing step (BFS) problem; for laminar regimes (Re = 100), the model yields results comparable to computational fluid dynamics (CFD) without the need for any data, accurately predicting boundary layer thickness, separation, and reattachment lengths. For turbulent BFS flow at Re = 10,000, the framework achieves convergence to O(10^-4) using only 500 random supervision points (< 0.3 % of the total domain), outperforming established methods like Residual-based Attention-PINN in accuracy. This approach demonstrates strong potential for the super-resolution of complex turbulent flows from sparse experimental measurements.
Replaceable Bit-based Gripper for Picking Cluttered Food Items
Jan 01, 2026The food packaging industry goes through changes in food items and their weights quite rapidly. These items range from easy-to-pick, single-piece food items to flexible, long and cluttered ones. We propose a replaceable bit-based gripper system to tackle the challenge of weight-based handling of cluttered food items. The gripper features specialized food attachments(bits) that enhance its grasping capabilities, and a belt replacement system allows switching between different food items during packaging operations. It offers a wide range of control options, enabling it to grasp and drop specific weights of granular, cluttered, and entangled foods. We specifically designed bits for two flexible food items that differ in shape: ikura(salmon roe) and spaghetti. They represent the challenging categories of sticky, granular food and long, sticky, cluttered food, respectively. The gripper successfully picked up both spaghetti and ikura and demonstrated weight-specific dropping of these items with an accuracy over 80% and 95% respectively. The gripper system also exhibited quick switching between different bits, leading to the handling of a large range of food items.
SLACK: Attacking LiDAR-based SLAM with Adversarial Point Injections
Apr 03, 2025The widespread adoption of learning-based methods for the LiDAR makes autonomous vehicles vulnerable to adversarial attacks through adversarial \textit{point injections (PiJ)}. It poses serious security challenges for navigation and map generation. Despite its critical nature, no major work exists that studies learning-based attacks on LiDAR-based SLAM. Our work proposes SLACK, an end-to-end deep generative adversarial model to attack LiDAR scans with several point injections without deteriorating LiDAR quality. To facilitate SLACK, we design a novel yet simple autoencoder that augments contrastive learning with segmentation-based attention for precise reconstructions. SLACK demonstrates superior performance on the task of \textit{point injections (PiJ)} compared to the best baselines on KITTI and CARLA-64 dataset while maintaining accurate scan quality. We qualitatively and quantitatively demonstrate PiJ attacks using a fraction of LiDAR points. It severely degrades navigation and map quality without deteriorating the LiDAR scan quality.
Temperature Driven Multi-modal/Single-actuated Soft Finger
Jan 13, 2025Soft pneumatic fingers are of great research interest. However, their significant potential is limited as most of them can generate only one motion, mostly bending. The conventional design of soft fingers does not allow them to switch to another motion mode. In this paper, we developed a novel multi-modal and single-actuated soft finger where its motion mode is switched by changing the finger's temperature. Our soft finger is capable of switching between three distinctive motion modes: bending, twisting, and extension-in approximately five seconds. We carried out a detailed experimental study of the soft finger and evaluated its repeatability and range of motion. It exhibited repeatability of around one millimeter and a fifty percent larger range of motion than a standard bending actuator. We developed an analytical model for a fiber-reinforced soft actuator for twisting motion. This helped us relate the input pressure to the output twist radius of the twisting motion. This model was validated by experimental verification. Further, a soft robotic gripper with multiple grasp modes was developed using three actuators. This gripper can adapt to and grasp objects of a large range of size, shape, and stiffness. We showcased its grasping capabilities by successfully grasping a small berry, a large roll, and a delicate tofu cube.
Revisiting Point Cloud Completion: Are We Ready For The Real-World?
Nov 26, 2024Point clouds acquired in constrained and challenging real-world settings are incomplete, non-uniformly sparse, or both. These obstacles present acute challenges for a vital task - point cloud completion. Using tools from Algebraic Topology and Persistent Homology ($\mathcal{PH}$), we demonstrate that current benchmark synthetic point clouds lack rich topological features that are important constituents of point clouds captured in realistic settings. To facilitate research in this direction, we contribute the first real-world industrial point cloud dataset for point cloud completion, RealPC - a diverse set of rich and varied point clouds, consisting of $\sim$ 40,000 pairs across 21 categories of industrial structures in railway establishments. Our benchmark results on several strong baselines reveal a striking observation - the existing methods are tailored for synthetic datasets and fail miserably in real-world settings. Building on our observation that RealPC consists of several 0 and 1-dimensional $\mathcal{PH}$-based topological features, we demonstrate the potential of integrating Homology-based topological priors into existing works. More specifically, we present how 0-dimensional $\mathcal{PH}$ priors, which extract the global topology of a complete shape in the form of a 3-D skeleton, can assist a model in generating topologically-consistent complete shapes.
PhishNet: A Phishing Website Detection Tool using XGBoost
Jun 29, 2024PhisNet is a cutting-edge web application designed to detect phishing websites using advanced machine learning. It aims to help individuals and organizations identify and prevent phishing attacks through a robust AI framework. PhisNet utilizes Python to apply various machine learning algorithms and feature extraction techniques for high accuracy and efficiency. The project starts by collecting and preprocessing a comprehensive dataset of URLs, comprising both phishing and legitimate sites. Key features such as URL length, special characters, and domain age are extracted to effectively train the model. Multiple machine learning algorithms, including logistic regression, decision trees, and neural networks, are evaluated to determine the best performance in phishing detection. The model is finely tuned to optimize metrics like accuracy, precision, recall, and the F1 score, ensuring reliable detection of both common and sophisticated phishing tactics. PhisNet's web application is developed using React.js, which allows for client-side rendering and smooth integration with backend services, creating a responsive and user-friendly interface. Users can input URLs and receive immediate predictions with confidence scores, thanks to a robust backend infrastructure that processes data and provides real-time results. The model is deployed using Google Colab and AWS EC2 for their computational power and scalability, ensuring the application remains accessible and functional under varying loads. In summary, PhisNet represents a significant advancement in cybersecurity, showcasing the effective use of machine learning and web development technologies to enhance user security. It empowers users to prevent phishing attacks and highlights AI's potential in transforming cybersecurity.
ECC Analyzer: Extract Trading Signal from Earnings Conference Calls using Large Language Model for Stock Performance Prediction
Apr 29, 2024



In the realm of financial analytics, leveraging unstructured data, such as earnings conference calls (ECCs), to forecast stock performance is a critical challenge that has attracted both academics and investors. While previous studies have used deep learning-based models to obtain a general view of ECCs, they often fail to capture detailed, complex information. Our study introduces a novel framework: \textbf{ECC Analyzer}, combining Large Language Models (LLMs) and multi-modal techniques to extract richer, more predictive insights. The model begins by summarizing the transcript's structure and analyzing the speakers' mode and confidence level by detecting variations in tone and pitch for audio. This analysis helps investors form an overview perception of the ECCs. Moreover, this model uses the Retrieval-Augmented Generation (RAG) based methods to meticulously extract the focuses that have a significant impact on stock performance from an expert's perspective, providing a more targeted analysis. The model goes a step further by enriching these extracted focuses with additional layers of analysis, such as sentiment and audio segment features. By integrating these insights, the ECC Analyzer performs multi-task predictions of stock performance, including volatility, value-at-risk (VaR), and return for different intervals. The results show that our model outperforms traditional analytic benchmarks, confirming the effectiveness of using advanced LLM techniques in financial analytics.
RiskLabs: Predicting Financial Risk Using Large Language Model Based on Multi-Sources Data
Apr 11, 2024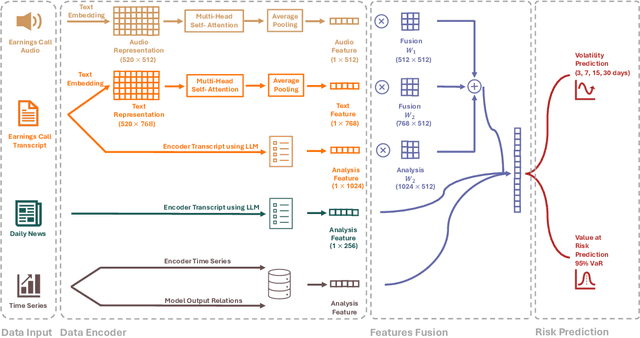
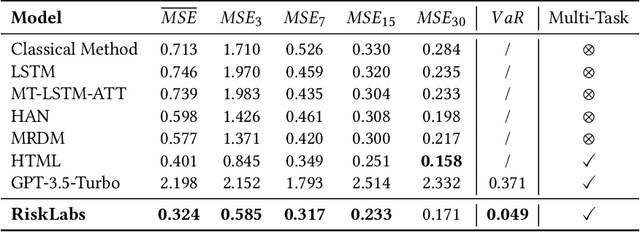


The integration of Artificial Intelligence (AI) techniques, particularly large language models (LLMs), in finance has garnered increasing academic attention. Despite progress, existing studies predominantly focus on tasks like financial text summarization, question-answering (Q$\&$A), and stock movement prediction (binary classification), with a notable gap in the application of LLMs for financial risk prediction. Addressing this gap, in this paper, we introduce \textbf{RiskLabs}, a novel framework that leverages LLMs to analyze and predict financial risks. RiskLabs uniquely combines different types of financial data, including textual and vocal information from Earnings Conference Calls (ECCs), market-related time series data, and contextual news data surrounding ECC release dates. Our approach involves a multi-stage process: initially extracting and analyzing ECC data using LLMs, followed by gathering and processing time-series data before the ECC dates to model and understand risk over different timeframes. Using multimodal fusion techniques, RiskLabs amalgamates these varied data features for comprehensive multi-task financial risk prediction. Empirical experiment results demonstrate RiskLab's effectiveness in forecasting both volatility and variance in financial markets. Through comparative experiments, we demonstrate how different data sources contribute to financial risk assessment and discuss the critical role of LLMs in this context. Our findings not only contribute to the AI in finance application but also open new avenues for applying LLMs in financial risk assessment.
GLiDR: Topologically Regularized Graph Generative Network for Sparse LiDAR Point Clouds
Nov 29, 2023Sparse LiDAR point clouds cause severe loss of detail of static structures and reduce the density of static points available for navigation. Reduced density can be detrimental to navigation under several scenarios. We observe that despite high sparsity, in most cases, the global topology of LiDAR outlining the static structures can be inferred. We utilize this property to obtain a backbone skeleton of a static LiDAR scan in the form of a single connected component that is a proxy to its global topology. We utilize the backbone to augment new points along static structures to overcome sparsity. Newly introduced points could correspond to existing static structures or to static points that were earlier obstructed by dynamic objects. To the best of our knowledge, we are the first to use this strategy for sparse LiDAR point clouds. Existing solutions close to our approach fail to identify and preserve the global static LiDAR topology and generate sub-optimal points. We propose GLiDR, a Graph Generative network that is topologically regularized using 0-dimensional Persistent Homology (PH) constraints. This enables GLiDR to introduce newer static points along a topologically consistent global static LiDAR backbone. GLiDR generates precise static points using 32x sparser dynamic scans and performs better than the baselines across three datasets. The newly introduced static points allow GLiDR to outperform LiDAR-based navigation using SLAM in several settings. GLiDR generates a valuable byproduct - an accurate binary segmentation mask of static and dynamic objects that is helpful for navigation planning and safety in constrained environments.
Differentiable SLAM Helps Deep Learning-based LiDAR Perception Tasks
Sep 17, 2023



We investigate a new paradigm that uses differentiable SLAM architectures in a self-supervised manner to train end-to-end deep learning models in various LiDAR based applications. To the best of our knowledge there does not exist any work that leverages SLAM as a training signal for deep learning based models. We explore new ways to improve the efficiency, robustness, and adaptability of LiDAR systems with deep learning techniques. We focus on the potential benefits of differentiable SLAM architectures for improving performance of deep learning tasks such as classification, regression as well as SLAM. Our experimental results demonstrate a non-trivial increase in the performance of two deep learning applications - Ground Level Estimation and Dynamic to Static LiDAR Translation, when used with differentiable SLAM architectures. Overall, our findings provide important insights that enhance the performance of LiDAR based navigation systems. We demonstrate that this new paradigm of using SLAM Loss signal while training LiDAR based models can be easily adopted by the community.