 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOVESe: MOVablE and Moving LiDAR Scene Segmentation with Improved Navigation in Seg-label free settings
Jun 26, 2023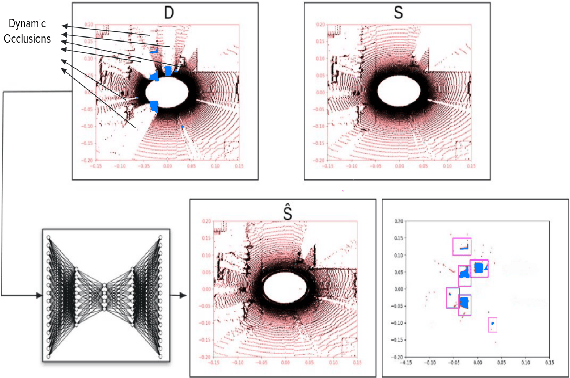


Accurate detection of movable and moving objects in LiDAR is of vital importance for navigation. Most existing works focus on extracting and removing moving objects during navigation. Movable objects like pedestrians, parked vehicles, etc. although static may move in the future. This leads to erroneous navigation and accidents. In such cases, it becomes necessary to detect potentially movable objects. To this end, we present a learning-based approach that segments movable and moving objects by generating static parts of scenes that are otherwise occluded. Our model performs superior to existing baselines on static LiDAR reconstructions using 3 datasets including a challenging sparse industrial dataset. We achieve this without the assistance of any segmentation labels because such labels might not always be available for less popular yet important settings like industrial environments. The non-movable static parts of the scene generated by our model are of vital importance for downstream navigation for SLAM. The movable objects detected by our model can be fed to a downstream 3D detector for aiding navigation. Though we do not use segmentation, we evaluate our method against navigation baselines that use it to remove dynamic objects for SLAM. Through extensive experiments on several datasets, we showcase that our model surpasses these baselines on navigation.
TPFNet: A Novel Text In-painting Transformer for Text Removal
Oct 27, 2022
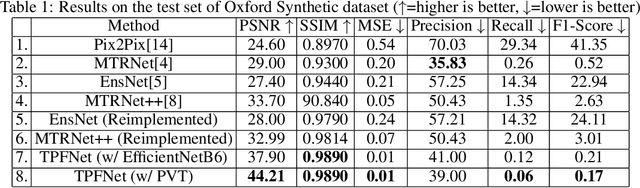

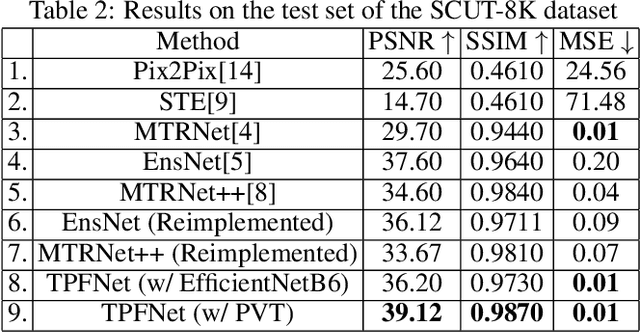
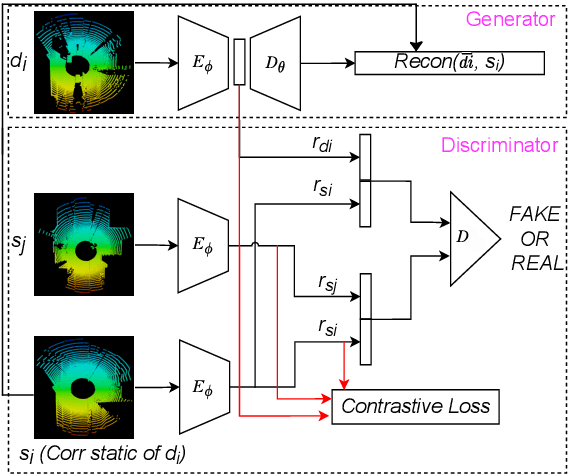
Text erasure from an image is helpful for various tasks such as image editing and privacy preservation. In this paper, we present TPFNet, a novel one-stage (end-toend) network for text removal from images. Our network has two parts: feature synthesis and image generation. Since noise can be more effectively removed from low-resolution images, part 1 operates on low-resolution images. The output of part 1 is a low-resolution text-free image. Part 2 uses the features learned in part 1 to predict a high-resolution text-free image. In part 1, we use "pyramidal vision transformer" (PVT) as the encoder. Further, we use a novel multi-headed decoder that generates a high-pass filtered image and a segmentation map, in addition to a text-free image. The segmentation branch helps locate the text precisely, and the high-pass branch helps in learning the image structure. To precisely locate the text, TPFNet employs an adversarial loss that is conditional on the segmentation map rather than the input image. On Oxford, SCUT, and SCUT-EnsText datasets, our network outperforms recently proposed networks on nearly all the metrics. For example, on SCUT-EnsText dataset, TPFNet has a PSNR (higher is better) of 39.0 and text-detection precision (lower is better) of 21.1, compared to the best previous technique, which has a PSNR of 32.3 and precision of 53.2. The source code can be obtained from https://github.com/CandleLabAI/TPFNet
ACLNet: An Attention and Clustering-based Cloud Segmentation Network
Jul 13, 2022
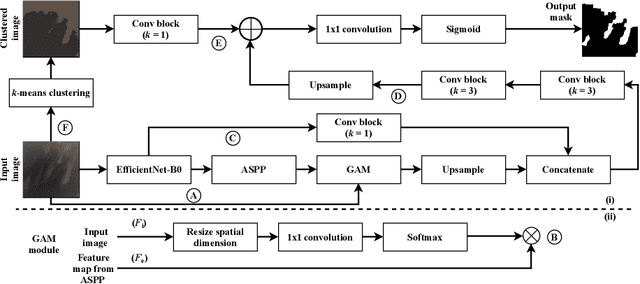
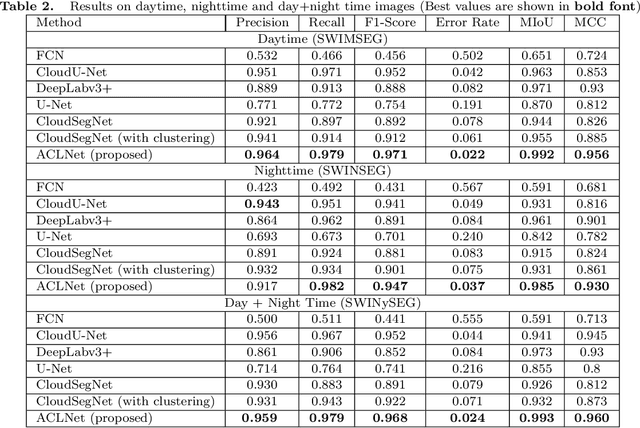

We propose a novel deep learning model named ACLNet, for cloud segmentation from ground images. ACLNet uses both deep neural network and machine learning (ML) algorithm to extract complementary features. Specifically, it uses EfficientNet-B0 as the backbone, "`a trous spatial pyramid pooling" (ASPP) to learn at multiple receptive fields, and "global attention module" (GAM) to extract finegrained details from the image. ACLNet also uses k-means clustering to extract cloud boundaries more precisely. ACLNet is effective for both daytime and nighttime images. It provides lower error rate, higher recall and higher F1-score than state-of-art cloud segmentation models. The source-code of ACLNet is available here: https://github.com/ckmvigil/ACLNet.
* 11 pages, 3 figures, 5 tables, Published in remote sensing letters
WaferSegClassNet -- A Light-weight Network for Classification and Segmentation of Semiconductor Wafer Defects
Jul 03, 2022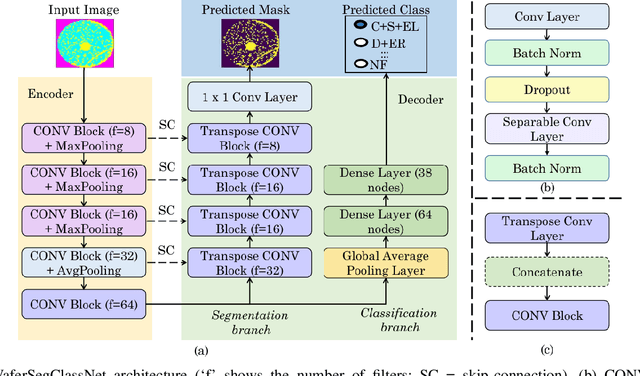
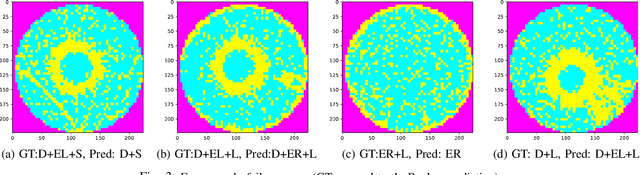

As the integration density and design intricacy of semiconductor wafers increase, the magnitude and complexity of defects in them are also on the rise. Since the manual inspection of wafer defects is costly, an automated artificial intelligence (AI) based computer-vision approach is highly desired. The previous works on defect analysis have several limitations, such as low accuracy and the need for separate models for classification and segmentation. For analyzing mixed-type defects, some previous works require separately training one model for each defect type, which is non-scalable. In this paper, we present WaferSegClassNet (WSCN), a novel network based on encoder-decoder architecture. WSCN performs simultaneous classification and segmentation of both single and mixed-type wafer defects. WSCN uses a "shared encoder" for classification, and segmentation, which allows training WSCN end-to-end. We use N-pair contrastive loss to first pretrain the encoder and then use BCE-Dice loss for segmentation, and categorical cross-entropy loss for classification. Use of N-pair contrastive loss helps in better embedding representation in the latent dimension of wafer maps. WSCN has a model size of only 0.51MB and performs only 0.2M FLOPS. Thus, it is much lighter than other state-of-the-art models. Also, it requires only 150 epochs for convergence, compared to 4,000 epochs needed by a previous work. We evaluate our model on the MixedWM38 dataset, which has 38,015 images. WSCN achieves an average classification accuracy of 98.2% and a dice coefficient of 0.9999. We are the first to show segmentation results on the MixedWM38 dataset. The source code can be obtained from https://github.com/ckmvigil/WaferSegClassNet.
* 11 pages, 2 figures, 7 tables, Published in Computers in Industry
RRLFSOR: An Efficient Self-Supervised Learning Strategy of Graph Convolutional Networks
Aug 17, 2021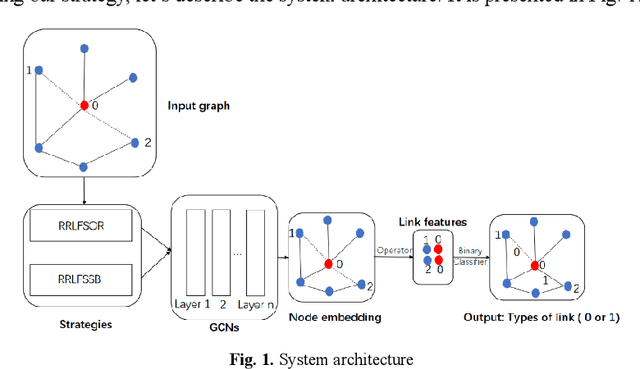
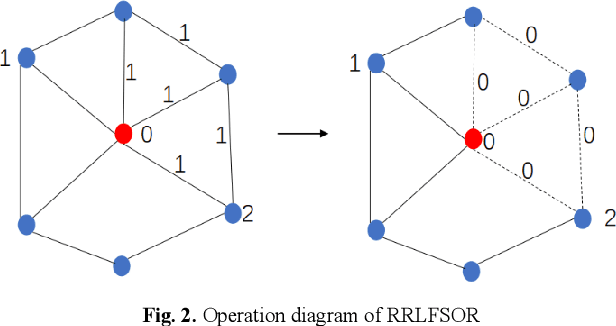
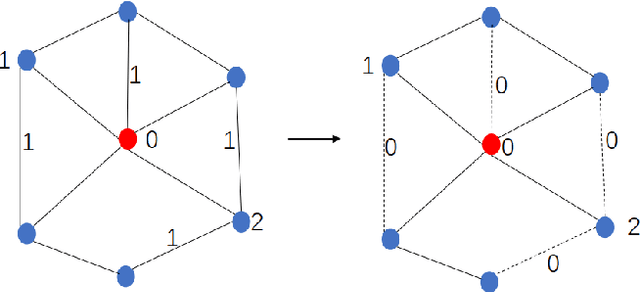

To further improve the performance and the self-learning ability of GCNs, in this paper, we propose an efficient self-supervised learning strategy of GCNs, named randomly removed links with a fixed step at one region (RRLFSOR). In addition, we also propose another self-supervised learning strategy of GCNs, named randomly removing links with a fixed step at some blocks (RRLFSSB), to solve the problem that adjacent nodes have no selected step. Experiments on transductive link prediction tasks show that our strategies outperform the baseline models consistently by up to 21.34% in terms of accuracy on three benchmark datasets.